def entrenar_modelos_cnn_ts(
train_scaled,
test_scaled,
train_index,
test_index,
prepare_data,
lags,
cantidad_modelos,
filters,
kernel_size,
pool_size,
n_conv_layers,
strides,
padding,
post_cnn_type,
post_cnn_units,
n_post_cnn_layers,
activation_conv,
activation_post,
learning_rate,
batch_size,
optimizer,
Dropout_rate,
epochs,
loss="mse",
scaler=None,
transformacion=None,
lambda_bc=None,
guardar_modelos=True,
graficar_loss=True,
graficar_ajuste=True,
graficar_residuales=True,
):
"""
Entrena múltiples redes CNN (Conv1D directa, sin TimeDistributed)
para regresión de series de tiempo, con búsqueda aleatoria de
hiperparámetros.
Arquitectura general
--------------------
Input (lags, 1)
→ [Conv1D + Dropout] × n_conv_layers
→ MaxPooling1D
→ Flatten (si post_cnn_type == "Dense")
ó directamente a LSTM/GRU (si post_cnn_type == "LSTM"/"GRU")
→ Capa post-CNN: LSTM | GRU | Dense (+ Dropout)
→ Dense(1)
Parámetros
----------
train_scaled : np.array
Serie de entrenamiento (escalada/transformada), 1-D o 2-D col.
test_scaled : np.array
Serie de prueba (escalada/transformada), 1-D o 2-D col.
train_index : pd.DatetimeIndex o array-like
Índice temporal del conjunto de entrenamiento COMPLETO
(antes de crear lags). Se usará train_index[lags:] para graficar.
test_index : pd.DatetimeIndex o array-like
Índice temporal del conjunto de prueba COMPLETO
(antes de crear lags). Se usará test_index[lags:] para graficar.
prepare_data : callable
Función externa que crea lags.
Firma: prepare_data(series, lags) -> (X, y)
donde X tiene forma (samples, lags, 1).
lags : int o list
Número de rezagos.
Si es lista, se selecciona aleatoriamente.
cantidad_modelos : int
Número de modelos a entrenar.
filters : int o list
Número de filtros de cada capa Conv1D.
kernel_size : int o list
Tamaño del kernel Conv1D.
pool_size : int o list
Tamaño del MaxPooling1D.
n_conv_layers : int o list
Número de capas Conv1D apiladas (antes del pooling).
strides : int o list
Strides de la Conv1D (default 1).
padding : str o list
Padding de la Conv1D ("same" o "valid").
post_cnn_type : str o list
Tipo de capa después del bloque CNN:
"LSTM", "GRU" o "Dense".
post_cnn_units : int o list
Neuronas de la capa post-CNN.
n_post_cnn_layers : int o list
Número de capas ocultas post-CNN apiladas.
Para LSTM/GRU con n > 1, las capas intermedias usan
return_sequences=True.
activation_conv : str o list
Activación de las capas Conv1D.
activation_post : str o list
Activación de la capa post-CNN (LSTM/GRU/Dense).
learning_rate : float o list
Tasa de aprendizaje.
batch_size : int o list
Tamaño del batch.
optimizer : str o list
Nombre del optimizador ("Adam", "RMSprop", etc.).
Dropout_rate : float o list
Tasa de dropout.
epochs : int o list
Número de épocas.
loss : str
Función de pérdida (default: "mse").
scaler : objeto sklearn o None
Scaler ajustado. Pipeline de inversión:
scaler.inverse_transform() → inv. transformación.
transformacion : str o None
"log", "boxcox" o None.
lambda_bc : float o None
Parámetro lambda de Box-Cox (requerido si transformacion="boxcox").
guardar_modelos : bool
Si True, guarda cada modelo en formato .keras.
graficar_loss : bool
Si True, muestra gráfico de Loss vs Val_loss.
graficar_ajuste : bool
Si True, muestra gráfico de ajuste sobre train y test.
graficar_residuales : bool
Si True, muestra gráfico de residuales en el tiempo.
Retorna
-------
resultados_df : pd.DataFrame
DataFrame con hiperparámetros y métricas de cada modelo.
predicciones : dict
Diccionario con las predicciones del último modelo:
- "y_train", "y_test": valores reales (escalados)
- "y_train_pred", "y_test_pred": predicciones (escalados)
- "y_train_inv", "y_test_inv": reales en escala original
- "y_train_pred_inv", "y_test_pred_inv": predicciones en escala original
- "train_index", "test_index": índice temporal post-lags
"""
# -------------------------------------------------
# Funciones auxiliares
# -------------------------------------------------
def seleccionar(param):
if isinstance(param, list):
return np.random.choice(param).item()
return param
def invertir_a_escala_original(valores):
resultado = valores.copy().flatten()
if scaler is not None:
resultado = scaler.inverse_transform(
resultado.reshape(-1, 1)
).flatten()
if transformacion == "log":
resultado = np.exp(resultado)
elif transformacion == "boxcox":
if lambda_bc is None:
raise ValueError(
"Se requiere lambda_bc para invertir Box-Cox."
)
resultado = inv_boxcox(resultado, lambda_bc)
elif transformacion is not None:
raise ValueError(
f"Transformación '{transformacion}' no soportada. "
"Use None, 'log' o 'boxcox'."
)
return resultado
def invertir_solo_scaler(valores):
resultado = valores.copy().flatten()
if scaler is not None:
resultado = scaler.inverse_transform(
resultado.reshape(-1, 1)
).flatten()
return resultado
# -------------------------------------------------
# Diccionarios
# -------------------------------------------------
opt_dict = {
"Adam": optimizers.Adam,
"RMSprop": optimizers.RMSprop,
"SGD": optimizers.SGD,
"Adagrad": optimizers.Adagrad,
"Adadelta": optimizers.Adadelta,
"Adamax": optimizers.Adamax,
"Nadam": optimizers.Nadam,
"Ftrl": optimizers.Ftrl,
}
post_layer_dict = {
"LSTM": LSTM,
"GRU": GRU,
}
# -------------------------------------------------
# Validaciones
# -------------------------------------------------
if transformacion == "boxcox" and lambda_bc is None:
raise ValueError(
"Debe proporcionar lambda_bc cuando transformacion='boxcox'."
)
hay_inversion = (scaler is not None) or (transformacion is not None)
resultados = []
predicciones = {}
for i in range(cantidad_modelos):
# ---------------------------------------------
# Selección de hiperparámetros
# ---------------------------------------------
lags_i = int(seleccionar(lags))
filters_i = int(seleccionar(filters))
kernel_size_i = int(seleccionar(kernel_size))
pool_size_i = int(seleccionar(pool_size))
n_conv_i = int(seleccionar(n_conv_layers))
strides_i = int(seleccionar(strides))
padding_i = seleccionar(padding)
post_type_i = seleccionar(post_cnn_type)
post_units_i = int(seleccionar(post_cnn_units))
n_post_i = int(seleccionar(n_post_cnn_layers))
act_conv_i = seleccionar(activation_conv)
act_post_i = seleccionar(activation_post)
lr_i = seleccionar(learning_rate)
batch_size_i = int(seleccionar(batch_size))
optimizer_i = seleccionar(optimizer)
dropout_i = seleccionar(Dropout_rate)
epochs_i = int(seleccionar(epochs))
print(f"\n{'='*60}")
print(f"Modelo {i+1}/{cantidad_modelos} — CNN + {post_type_i}")
print(f"{'='*60}")
print(f" Lags: {lags_i}")
print(f" Filters: {filters_i}, Kernel: {kernel_size_i}, "
f"Pool: {pool_size_i}")
print(f" Conv layers: {n_conv_i}, Strides: {strides_i}, "
f"Padding: {padding_i}")
print(f" Post-CNN: {post_type_i} ({post_units_i} units, "
f"{n_post_i} capas)")
print(f" Act Conv: {act_conv_i}, Act Post: {act_post_i}")
print(f" LR: {lr_i}, Optimizer: {optimizer_i}, "
f"Batch: {batch_size_i}")
print(f" Dropout: {dropout_i}, Epochs: {epochs_i}")
# ---------------------------------------------
# Preparar datos
# ---------------------------------------------
X_train, y_train = prepare_data(train_scaled, lags_i)
X_test, y_test = prepare_data(test_scaled, lags_i)
# Reshape directo: (samples, lags, 1)
X_train = X_train.reshape(X_train.shape[0], lags_i, 1)
X_test = X_test.reshape(X_test.shape[0], lags_i, 1)
# ---------------------------------------------
# Construir modelo
# ---------------------------------------------
model = Sequential()
model.add(Input(shape=(lags_i, 1)))
# Capas Conv1D directas (sin TimeDistributed)
for conv_idx in range(n_conv_i):
current_kernel = min(kernel_size_i, lags_i)
model.add(
Conv1D(
filters=filters_i,
kernel_size=current_kernel,
activation=act_conv_i,
padding=padding_i,
strides=strides_i,
)
)
if dropout_i > 0:
model.add(Dropout(dropout_i))
# MaxPooling1D
model.add(MaxPooling1D(pool_size=pool_size_i))
# Capas post-CNN
if post_type_i in post_layer_dict:
# LSTM / GRU reciben entrada 3D directamente
# (la salida de MaxPooling1D ya es 3D: samples, steps, filters)
RecurrentLayer = post_layer_dict[post_type_i]
for layer_idx in range(n_post_i):
return_seq = layer_idx < (n_post_i - 1)
model.add(
RecurrentLayer(
post_units_i,
activation=act_post_i,
return_sequences=return_seq,
)
)
if dropout_i > 0:
model.add(Dropout(dropout_i))
elif post_type_i == "Dense":
model.add(Flatten())
for _ in range(n_post_i):
model.add(Dense(post_units_i, activation=act_post_i))
if dropout_i > 0:
model.add(Dropout(dropout_i))
else:
raise ValueError(
f"post_cnn_type '{post_type_i}' no soportado. "
"Use 'LSTM', 'GRU' o 'Dense'."
)
# Capa de salida
model.add(Dense(1))
# ---------------------------------------------
# Optimizador
# ---------------------------------------------
if optimizer_i not in opt_dict:
raise ValueError(f"Optimizador '{optimizer_i}' no soportado.")
opt = opt_dict[optimizer_i](learning_rate=lr_i)
# ---------------------------------------------
# Compilar y entrenar
# ---------------------------------------------
model.compile(loss=loss, optimizer=opt)
try:
history = model.fit(
X_train, y_train,
validation_data=(X_test, y_test),
epochs=epochs_i,
batch_size=batch_size_i,
verbose=0,
)
except Exception as e:
print(f"\n ✗ Error al entrenar modelo {i+1}: {e}")
print(" Saltando este modelo...")
continue
# ---------------------------------------------
# Predicciones
# ---------------------------------------------
y_train_pred = model.predict(X_train, verbose=0).flatten()
y_test_pred = model.predict(X_test, verbose=0).flatten()
# Métricas en espacio escalado/transformado
rmse_train = np.sqrt(mean_squared_error(y_train, y_train_pred))
rmse_test = np.sqrt(mean_squared_error(y_test, y_test_pred))
r2_train = r2_score(y_train, y_train_pred)
r2_test = r2_score(y_test, y_test_pred)
# Índices temporales post-lags
idx_train = train_index[lags_i:]
idx_test = test_index[lags_i:]
print(f"\n --- Métricas (espacio escalado/transformado) ---")
print(f" RMSE Train: {rmse_train:.6f} | Test: {rmse_test:.6f}")
print(f" R² Train: {r2_train:.6f} | Test: {r2_test:.6f}")
# ---------------------------------------------
# Invertir a escala original
# ---------------------------------------------
y_train_inv = None
y_test_inv = None
y_train_pred_inv = None
y_test_pred_inv = None
rmse_train_inv = None
rmse_test_inv = None
r2_train_inv = None
r2_test_inv = None
if hay_inversion:
y_train_inv = invertir_a_escala_original(y_train)
y_test_inv = invertir_a_escala_original(y_test)
y_train_pred_inv = invertir_a_escala_original(y_train_pred)
y_test_pred_inv = invertir_a_escala_original(y_test_pred)
rmse_train_inv = np.sqrt(
mean_squared_error(y_train_inv, y_train_pred_inv)
)
rmse_test_inv = np.sqrt(
mean_squared_error(y_test_inv, y_test_pred_inv)
)
r2_train_inv = r2_score(y_train_inv, y_train_pred_inv)
r2_test_inv = r2_score(y_test_inv, y_test_pred_inv)
inv_label = []
if scaler is not None:
inv_label.append(type(scaler).__name__)
if transformacion is not None:
inv_label.append(transformacion)
inv_label_str = " + ".join(inv_label)
print(
f"\n --- Métricas (escala original, "
f"inv. {inv_label_str}) ---"
)
print(
f" RMSE Train: {rmse_train_inv:.6f} | "
f"Test: {rmse_test_inv:.6f}"
)
print(
f" R² Train: {r2_train_inv:.6f} | "
f"Test: {r2_test_inv:.6f}"
)
# ---------------------------------------------
# Gráfico de Loss y Val Loss
# ---------------------------------------------
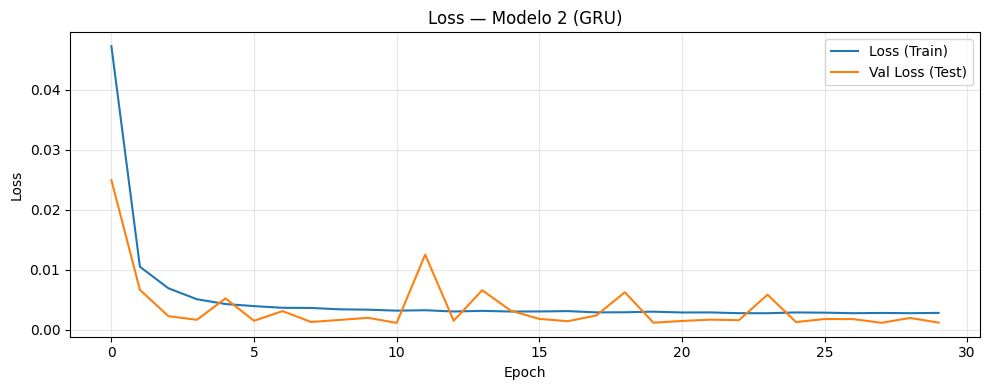
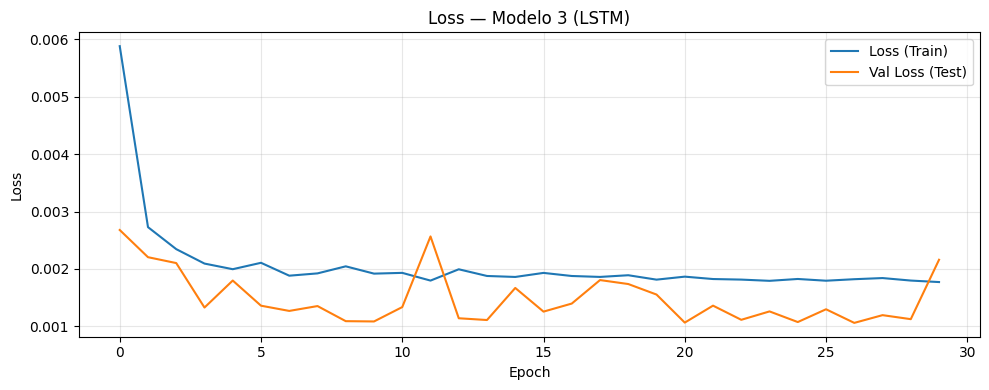
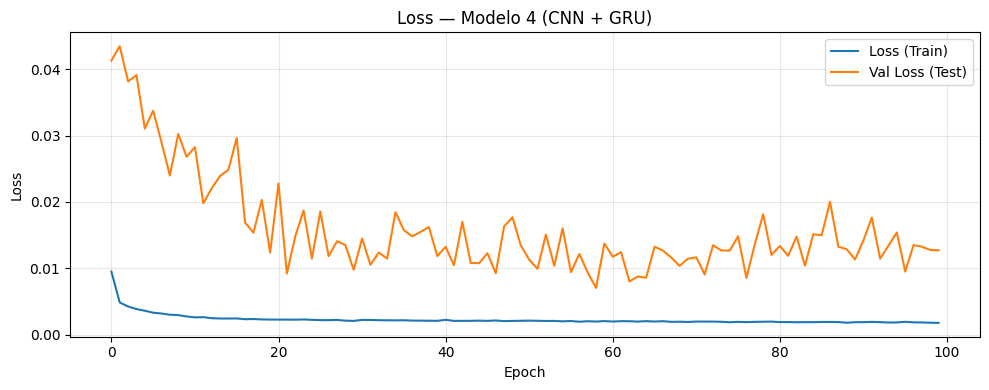
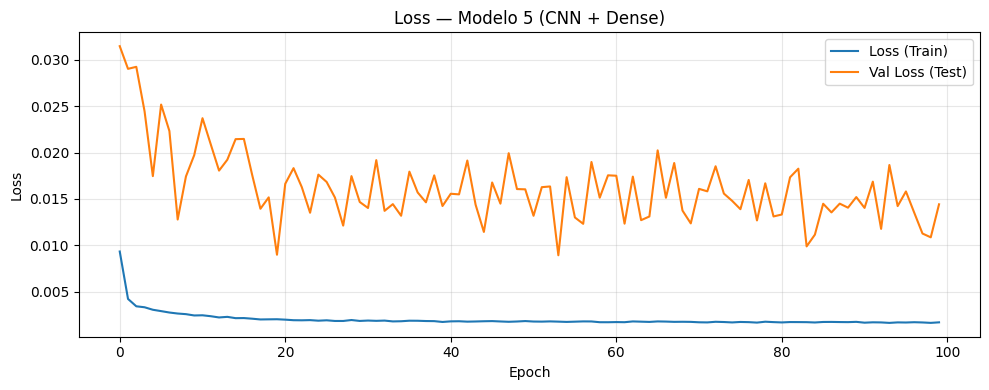
if graficar_loss:
plt.figure(figsize=(10, 4))
plt.plot(history.history["loss"], label="Loss (Train)")
plt.plot(history.history["val_loss"], label="Val Loss (Test)")
plt.title(
f"Loss — Modelo {i+1} (CNN + {post_type_i})"
)
plt.xlabel("Epoch")
plt.ylabel("Loss")
plt.legend()
plt.grid(alpha=0.3)
plt.tight_layout()
plt.show()
# ---------------------------------------------
# Gráfico de ajuste
# ---------------------------------------------
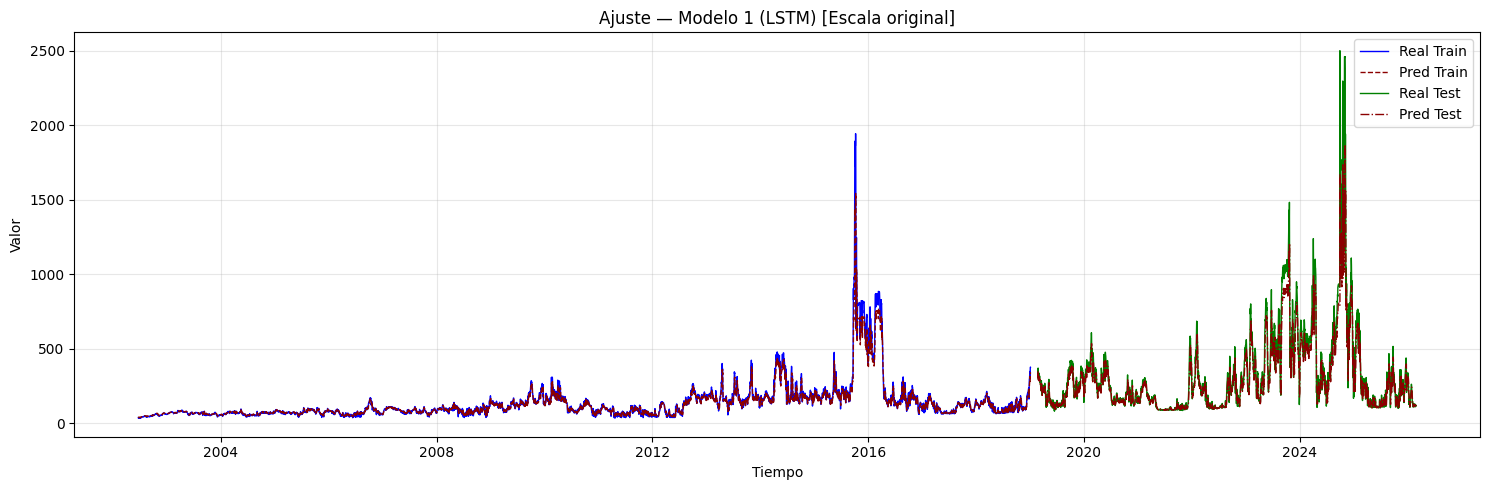
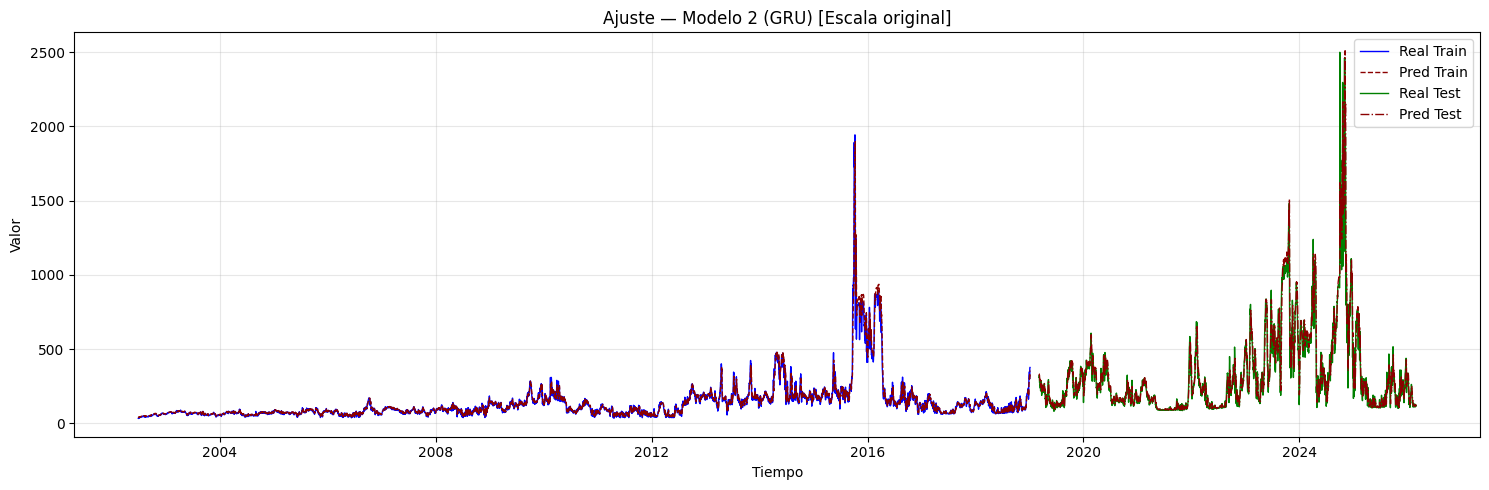
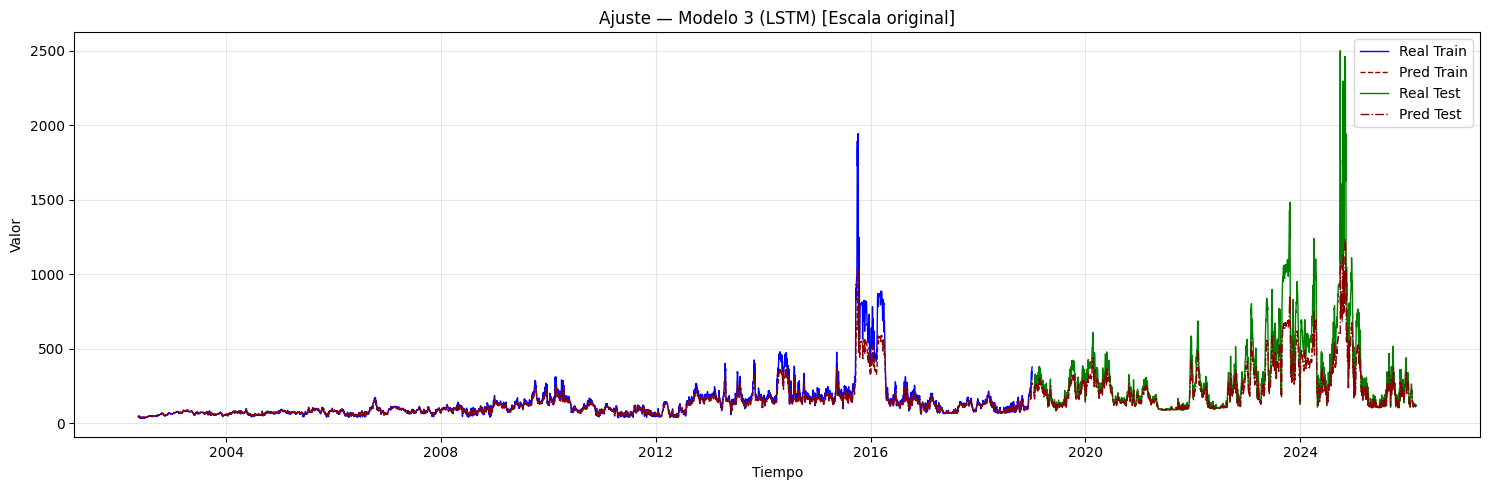
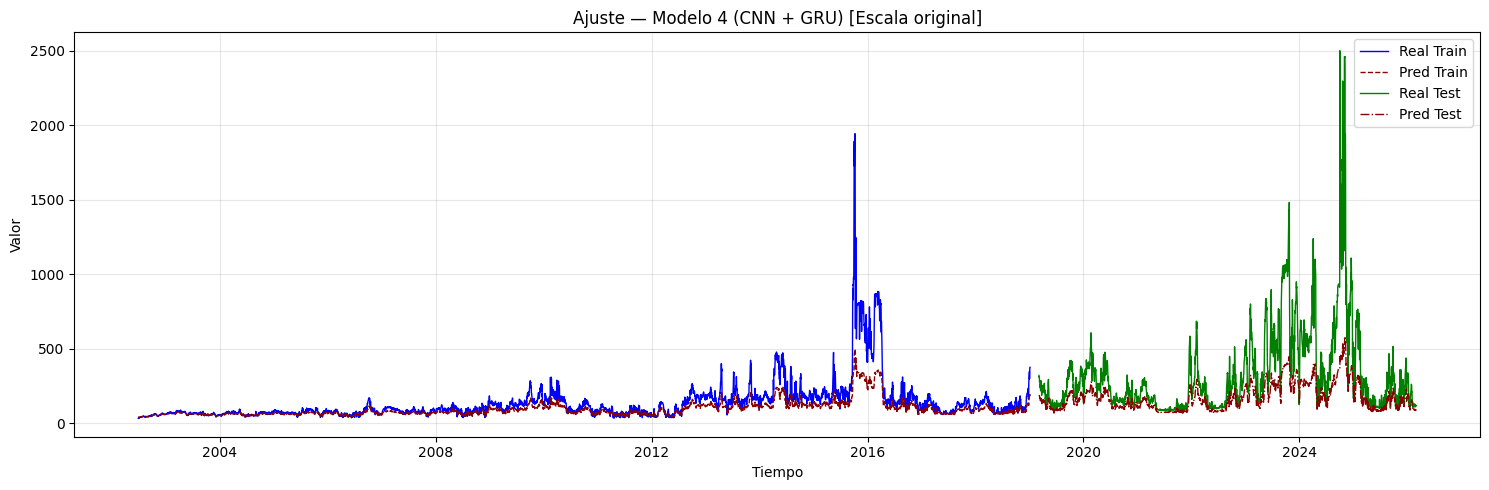
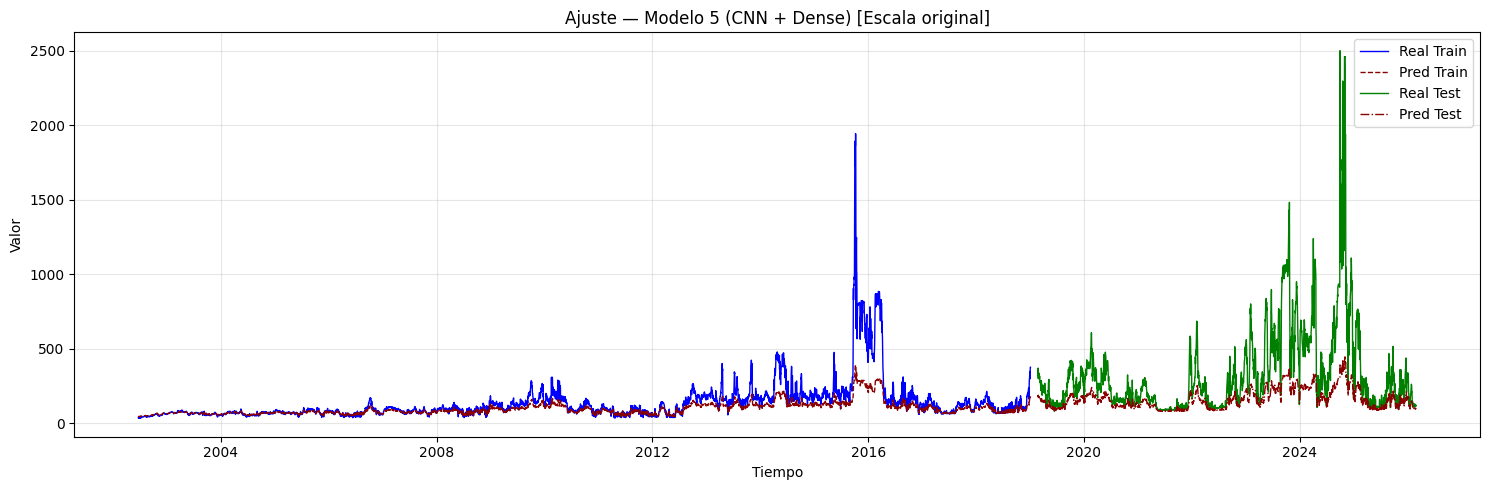
if graficar_ajuste:
if hay_inversion:
plt.figure(figsize=(15, 5))
plt.plot(
idx_train, y_train_inv,
label="Real Train", color="blue", linewidth=1,
)
plt.plot(
idx_train, y_train_pred_inv,
label="Pred Train", color="darkred",
linewidth=1, linestyle="--",
)
plt.plot(
idx_test, y_test_inv,
label="Real Test", color="green", linewidth=1,
)
plt.plot(
idx_test, y_test_pred_inv,
label="Pred Test", color="darkred",
linewidth=1, linestyle="-.",
)
plt.title(
f"Ajuste — Modelo {i+1} (CNN + {post_type_i}) "
f"[Escala original]"
)
plt.xlabel("Tiempo")
plt.ylabel("Valor")
plt.legend()
plt.grid(alpha=0.3)
plt.tight_layout()
plt.show()
else:
plt.figure(figsize=(15, 5))
plt.plot(
idx_train, y_train,
label="Real Train", color="blue", linewidth=1,
)
plt.plot(
idx_train, y_train_pred,
label="Pred Train", color="darkred",
linewidth=1, linestyle="--",
)
plt.plot(
idx_test, y_test,
label="Real Test", color="green", linewidth=1,
)
plt.plot(
idx_test, y_test_pred,
label="Pred Test", color="darkred",
linewidth=1, linestyle="-.",
)
plt.title(
f"Ajuste — Modelo {i+1} (CNN + {post_type_i})"
)
plt.xlabel("Tiempo")
plt.ylabel("Valor")
plt.legend()
plt.grid(alpha=0.3)
plt.tight_layout()
plt.show()
# ---------------------------------------------
# Gráfico de residuales
# ---------------------------------------------
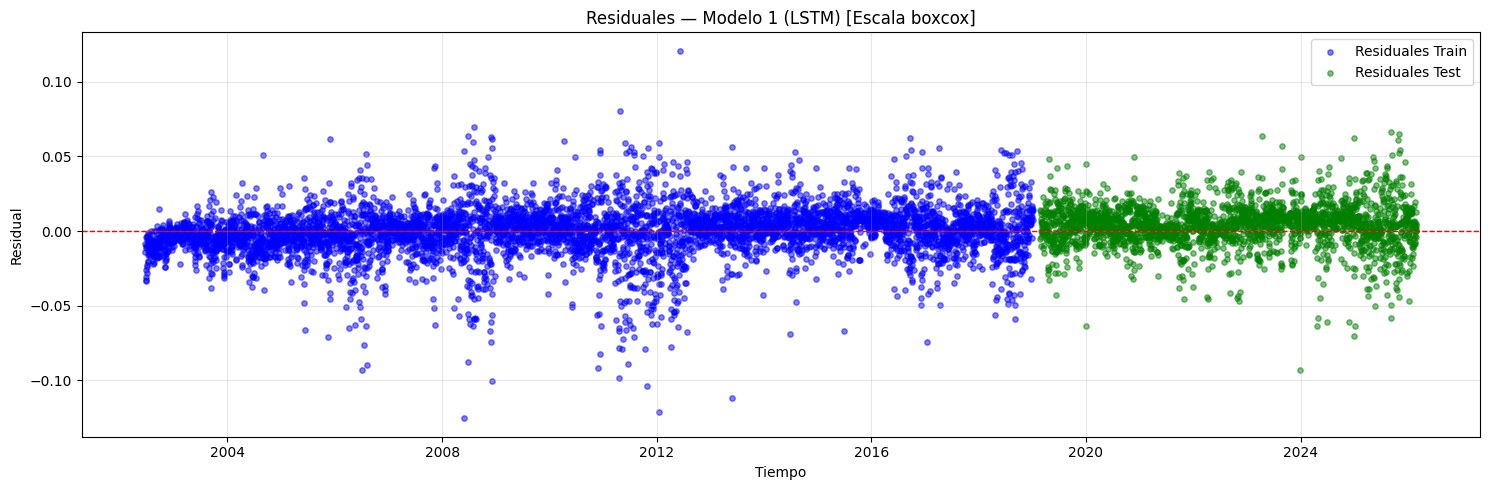
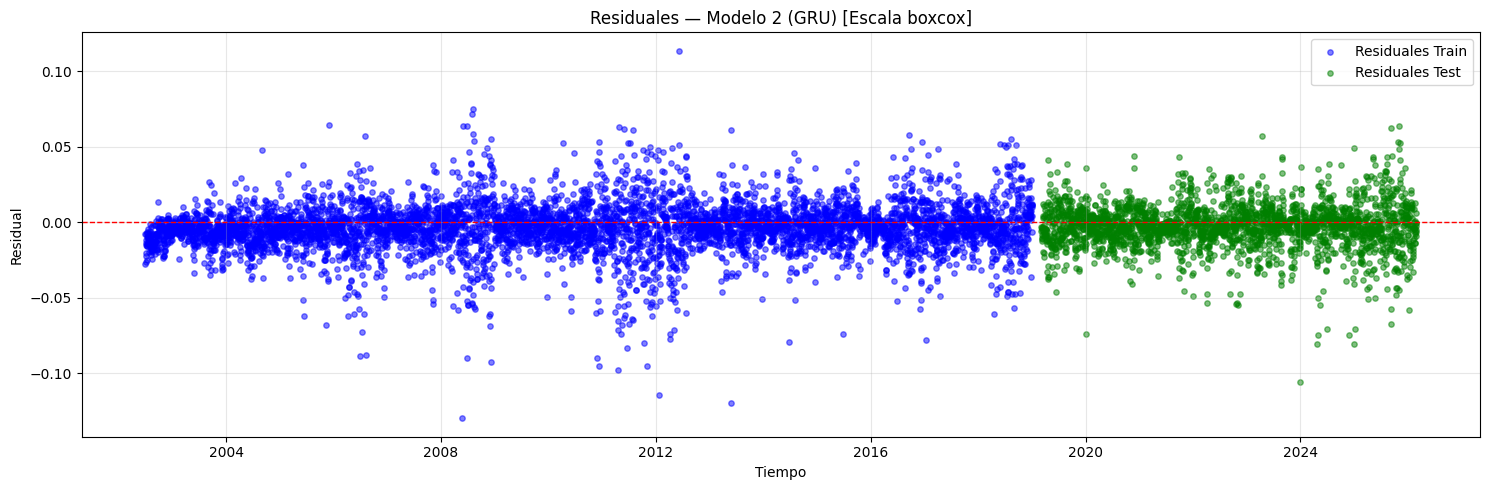
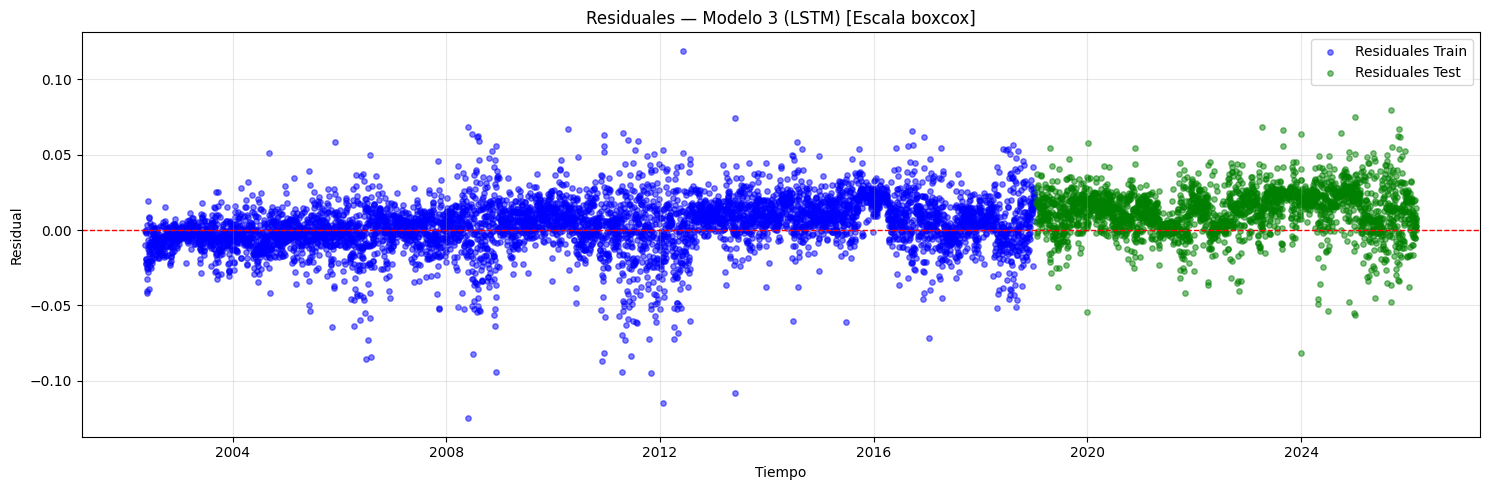
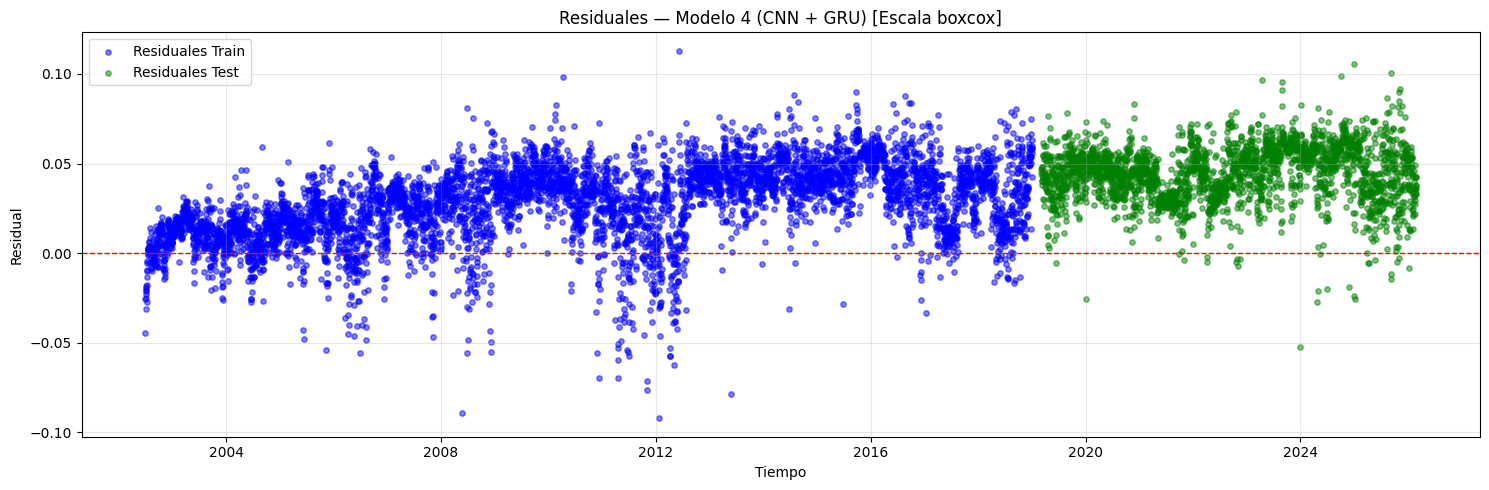
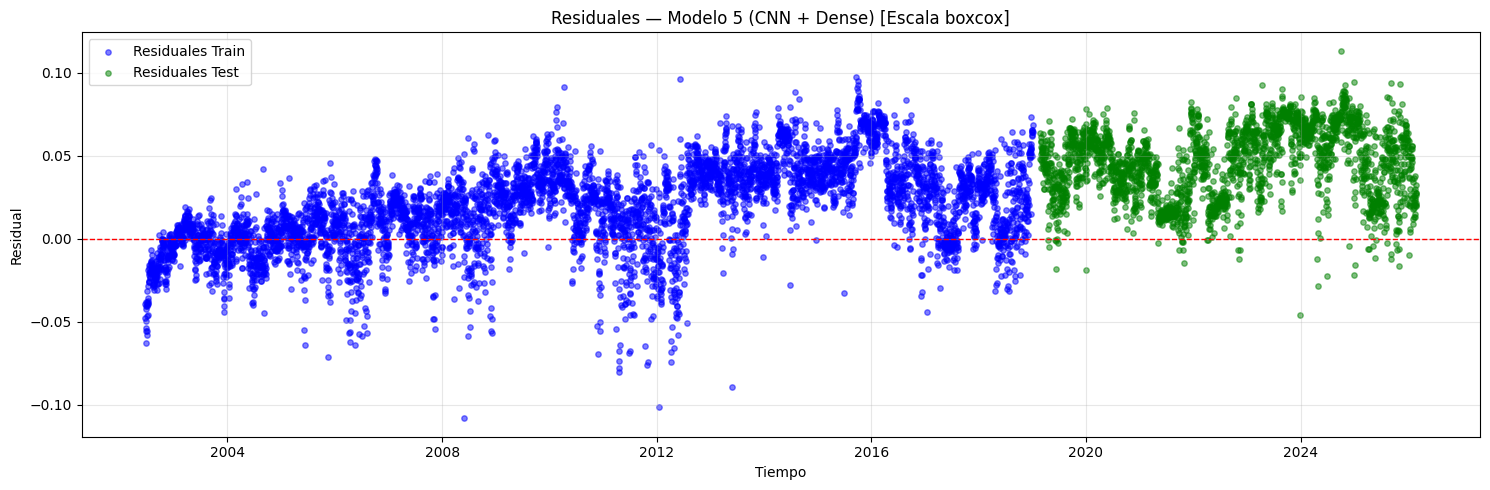
if graficar_residuales:
if scaler is not None:
y_tr_scl = invertir_solo_scaler(y_train)
y_tr_pred_scl = invertir_solo_scaler(y_train_pred)
y_te_scl = invertir_solo_scaler(y_test)
y_te_pred_scl = invertir_solo_scaler(y_test_pred)
res_train = y_tr_scl - y_tr_pred_scl
res_test = y_te_scl - y_te_pred_scl
if transformacion is not None:
res_label = f"[Escala {transformacion}]"
else:
res_label = "[Inv. scaler]"
else:
res_train = y_train - y_train_pred
res_test = y_test - y_test_pred
if transformacion is not None:
res_label = f"[Escala {transformacion}]"
else:
res_label = ""
plt.figure(figsize=(15, 5))
plt.scatter(
idx_train, res_train, color="blue",
alpha=0.5, s=15, label="Residuales Train",
)
plt.scatter(
idx_test, res_test, color="green",
alpha=0.5, s=15, label="Residuales Test",
)
plt.axhline(y=0, color="red", linestyle="--", linewidth=1)
plt.title(
f"Residuales — Modelo {i+1} "
f"(CNN + {post_type_i}) {res_label}"
)
plt.xlabel("Tiempo")
plt.ylabel("Residual")
plt.legend()
plt.grid(alpha=0.3)
plt.tight_layout()
plt.show()
# ---------------------------------------------
# Guardar modelo
# ---------------------------------------------
if guardar_modelos:
nombre_archivo = (
f"modelo_{i+1}_CNN_{post_type_i}_"
f"lags_{lags_i}.keras"
)
model.save(nombre_archivo)
print(f"\n Modelo guardado: {nombre_archivo}")
# ---------------------------------------------
# Almacenar resultados
# ---------------------------------------------
resultado = {
"modelo": i + 1,
"tipo_red": f"CNN+{post_type_i}",
"lags": lags_i,
"filters": filters_i,
"kernel_size": kernel_size_i,
"pool_size": pool_size_i,
"n_conv_layers": n_conv_i,
"strides": strides_i,
"padding": padding_i,
"post_cnn_type": post_type_i,
"post_cnn_units": post_units_i,
"n_post_cnn_layers": n_post_i,
"activation_conv": act_conv_i,
"activation_post": act_post_i,
"learning_rate": lr_i,
"batch_size": batch_size_i,
"optimizer": optimizer_i,
"dropout": dropout_i,
"epochs": epochs_i,
"loss_fn": loss,
"rmse_train": rmse_train,
"rmse_test": rmse_test,
"r2_train": r2_train,
"r2_test": r2_test,
}
if hay_inversion:
resultado["rmse_train_original"] = rmse_train_inv
resultado["rmse_test_original"] = rmse_test_inv
resultado["r2_train_original"] = r2_train_inv
resultado["r2_test_original"] = r2_test_inv
resultados.append(resultado)
# Guardar predicciones del modelo actual
predicciones = {
"y_train": y_train,
"y_test": y_test,
"y_train_pred": y_train_pred,
"y_test_pred": y_test_pred,
"y_train_inv": y_train_inv,
"y_test_inv": y_test_inv,
"y_train_pred_inv": y_train_pred_inv,
"y_test_pred_inv": y_test_pred_inv,
"train_index": idx_train,
"test_index": idx_test,
}
resultados_df = pd.DataFrame(resultados)
return resultados_df, predicciones