Análisis de Componentes Principales-PCA#
El Análisis de Componentes Principales (PCA, por sus siglas en inglés) es una técnica estadística que permite reducir la cantidad de variables en un conjunto de datos, conservando al mismo tiempo la mayor cantidad de información posible. Esta reducción se logra identificando nuevas variables llamadas componentes principales, que son combinaciones lineales de las variables originales.
¿Para qué sirve PCA?
Simplificar conjuntos de datos con muchas variables.
Visualizar datos en 2D o 3D aunque el conjunto tenga muchas dimensiones.
Eliminar redundancia si las variables están correlacionadas.
Preprocesar datos antes de aplicar otros algoritmos de aprendizaje automático.
¿Qué hace exactamente PCA?
Centra los datos: se resta la media de cada variable para que todas estén centradas en 0.
Calcula la matriz de covarianzas: esta matriz describe cómo varían conjuntamente las variables.
Obtiene los autovalores y autovectores: los autovectores son las nuevas direcciones (componentes), y los autovalores indican cuánta varianza captura cada uno.
Ordena las componentes: se seleccionan los componentes con mayor varianza explicada.
Proyecta los datos sobre estas nuevas direcciones principales.
¿Qué representa cada componente principal?
PC1 (Primer componente principal): la dirección en la que los datos tienen la mayor varianza posible.
PC2: la siguiente dirección ortogonal a PC1 que captura la mayor varianza restante, y así sucesivamente.
¿Por qué es importante escalar los datos antes de aplicar PCA?
PCA depende directamente de la varianza. Si una variable tiene valores mucho más grandes que otras, dominará el análisis aunque no sea la más relevante. Para evitarlo, es necesario escalar las variables:
Estandarización (z-score): centra en media 0 y varianza 1. Muy recomendada para PCA.
Normalización Min-Max: ajusta todas las variables al rango \([0, 1]\). Útil en algunos casos, pero puede distorsionar la varianza relativa.
Resultado final de PCA:
Nuevas variables (componentes principales) que no están correlacionadas.
Cada componente explica un porcentaje de la varianza total.
Se pueden usar los primeros componentes para trabajar con menos dimensiones, acelerando modelos y facilitando visualización.
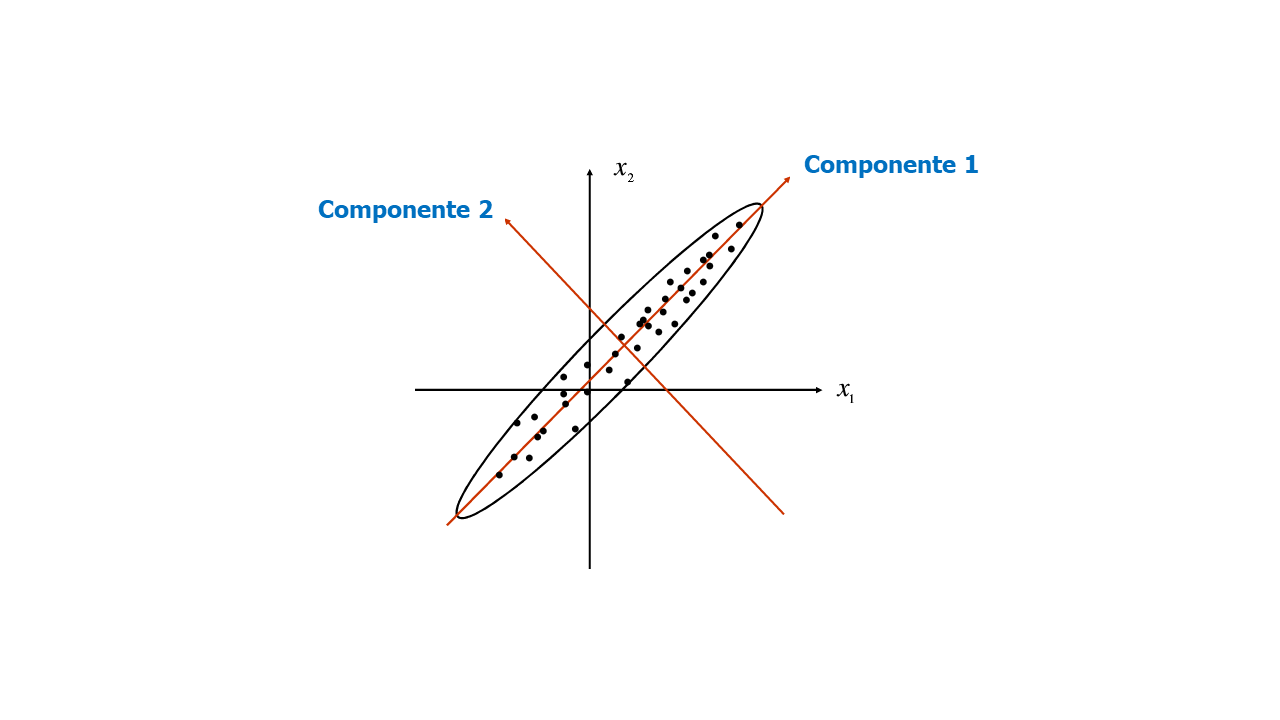
Componentes#
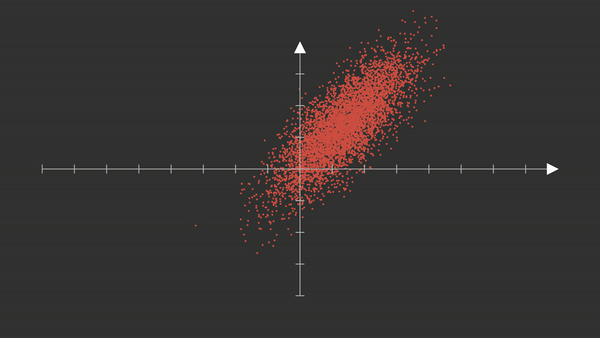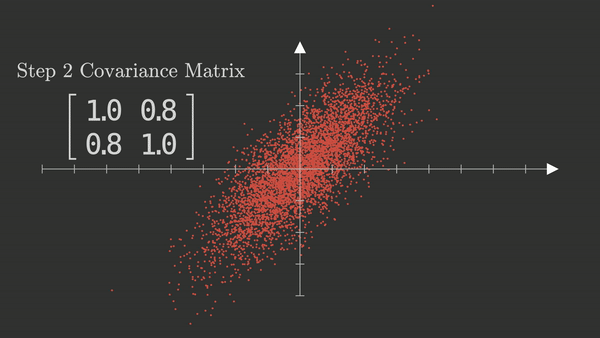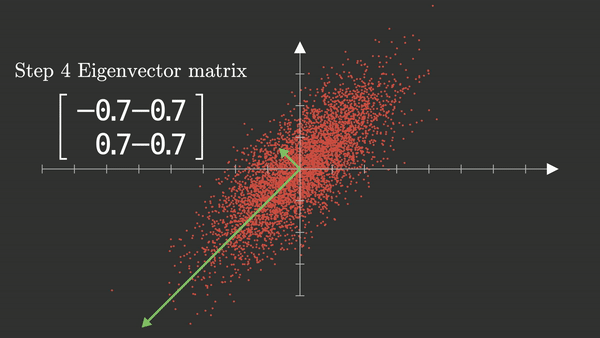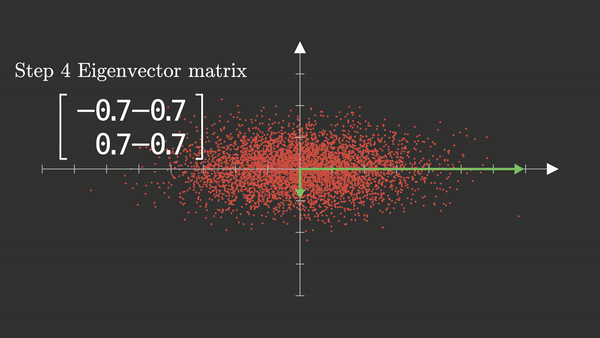
PCA_1#
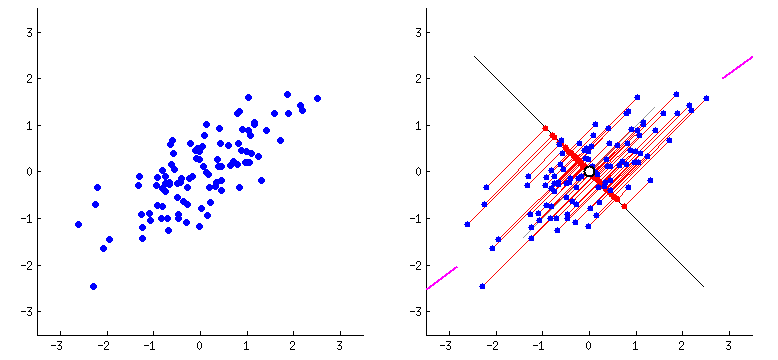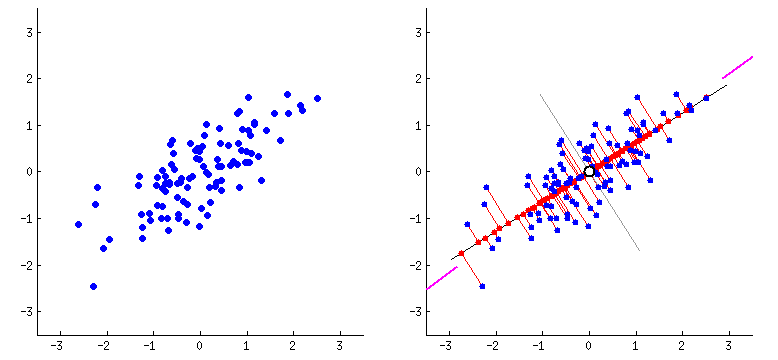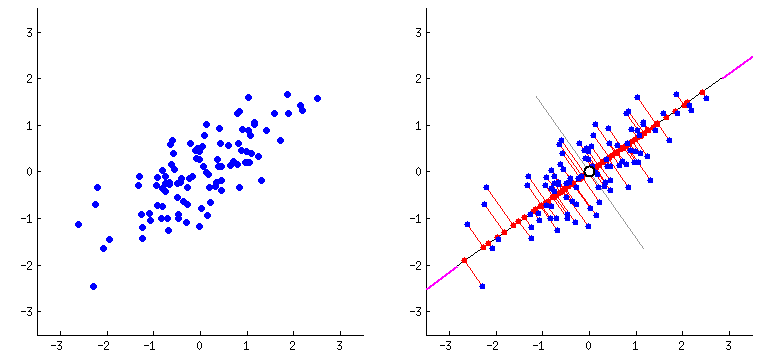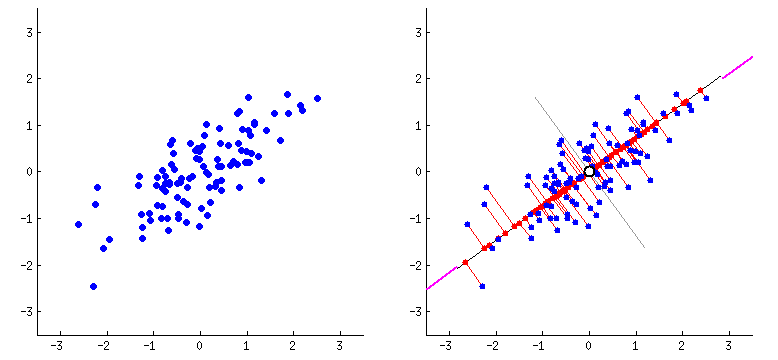
PCA_2#
Los Componentes Principales son los Eigenvectores de la matriz de varianzas-covarianzas de las variables originales y se convertirán en los nuevos ejes. El ángulo entre los Eigenvectores es de 90°, así que los Eigenvectores son ortogonales entre sí.
La matriz de varianzas-covarianzas es simétrica, del orden \(nxn\), las varianzas, \((\sigma^2_{ij})\), de cada variable están en la diagonal de la matriz, los demás valores son las covarianzas, \((\sigma_{ij})\).
Para \(p\) variables, se extraen \(p\) Eigenvectores y \(p\) Eigenvalores. Estos Eigenvectores son las Componentes Principales y el Eigenvector asociado a cada Componente Principal es la proporción de la varianza total que ese componente puede explicar.
En el ACP no se generan variables nuevas, sino que se transforman en nuevas combinaciones lineales. Por lo anterior, la varianza total de las variables originales sigue siendo la misma.
Técnicamente, PCA implica la rotación del sistema de coordenadas original a un nuevo sistema de coordenadas con propiedades estadísticas deseables. Más precisamente, se busca definir una transformación ortogonal a una matriz de covarianza diagonal. Computacionalmente, PCA se reduce a resolver los valores propios y los vectores propios de una matriz definida positiva mediante un proceso generalmente denominado análisis de valores propios o descomposición espectral.
Este proceso de extracción de características se utiliza tanto para optimizar el espacio de almacenamiento y la eficiencia computacional del algoritmo de aprendizaje, como para mejorar el rendimiento predictivo al reducir la maldición de la dimensionalidad.
Ejemplo:#
Supongamos la siguiente matriz de varianzas-covarianzas de un conjunto de dos variables:
La varianza de la variable 1 es igual a 0,00761 y la varianza de la variable 2 es 0,00840. La sumatoria de la varianza del conjunto de datos es de 0,01601 \((0,00761+0,00840)\).
Eigenvalores:#
Eigenvalores \(\lambda_i\): varianzas de cada Componente.
El Componente Principal 1 es el más importante porque es el de mayor Eigenvalor. Los Eigenvalores son las varianzas de cada Componente Principal y la suma de los Eigenvalores es la suma de las varianzas de las variables originales, es decir, es la varianza total, la cual es 0,01601 \((0,0113385+0,00467151)\).
El Componente Principal 1 explica el 70,82% de la variabilidad total. Recuerde que la sumatoria de los \(\lambda\) es igual a la sumatoria de las varianzas de las variables. El analista puede decidir en trabajar solo con esta Componente y así se reduciría la dimensionalidad de los datos. Este es el objetivo del ACP, encontrar la menor cantidad de componentes posibles que puedan explicar la mayor parte de la variación original. En otras palabras, con el ACP se busca representar la \(p\) variables en un número menor de variables (Componentes) conformadas como combinaciones lineales de las originales y perder la menor cantidad de información.
Al aplicar el ACP, las variables originales correlacionadas se transforman en variables no correlacionadas.
Proporción de la varianza de la Componente Principal 1:
Proporción de la varianza de la Componente Principal 2:
Como la desviación estándar es la raíz cuadrada de la varianza, cada Componente Principal tiene la siguiente desviación estándar.
Desviación estándar Componente Principal 1:
Desviación estándar Componente Principal 2:
Eigenvectores:#
Eigenvectores: Cargas de cada Componente.
Las cargas de un Componente Principal son los elementos del vector propio que forman la componente. Cada componente es una combinación lineal de las variables del conjunto de datos.
El primer elemento de \(Eigenvector_1\) es 0,6638921, esta es la carga o score para la primera variable original. El segundo elemento es la carga que se le asigna a la segunda variable de la base de datos.
A la matriz que se conforma con los Eigenvectores se llama matriz de rotación.
Cada vector propio debe tener una longitud igual a 1,0. Esto se comprueba si la suma de cada elemento (cargas) al cuadrado es igual a 1,0. Esta condición es una restricción del modelo porque con el valor de 1,0 las varianzas no se modifican.
Significado de las cargas:#
Las cargas, también conocidas como “loadings” en inglés, son los coeficientes que indican la contribución de cada variable original a una componente principal. En otras palabras, las cargas representan la correlación entre las variables originales y las componentes principales.
Las cargas indican cómo se combinan las variables originales para formar los nuevos componentes principales.
Interpretación de las cargas:
Una carga alta (en valor absoluto) indica que esa variable contribuye fuertemente al componente.
Una carga cercana a cero sugiere que la variable tiene poca influencia en ese componente.
El signo de la carga (positivo o negativo) indica la dirección en la que influye la variable.
Las cargas son esenciales para comprender e interpretar los resultados de PCA, ya que proporcionan una conexión directa entre las variables originales y las componentes principales.
Biplot:#
Un biplot es una combinación de un scatter plot de las puntuaciones de las componentes principales y una visualización de las cargas (coeficientes) de las variables originales. Esto ayuda a interpretar cómo las variables originales contribuyen a las componentes principales.
Esto permite:
Visualizar cómo se agrupan las observaciones en el nuevo espacio reducido.
Ver qué variables están asociadas entre sí y con cada componente.
Identificar la dirección de mayor varianza para cada variable.
¿Cómo se interpreta un biplot?
Las observaciones (puntos) que estén cerca entre sí están relacionadas.
Las flechas (variables) que apunten en la misma dirección están positivamente correlacionadas.
Flechas ortogonales indican variables no correlacionadas.
Flechas en direcciones opuestas implican correlación negativa.
La longitud de la flecha indica qué tanto influye esa variable en el plano representado (PC1 vs. PC2).
Importante: El biplot es más informativo cuando los dos primeros componentes explican un alto porcentaje de la varianza total, ya que de lo contrario la proyección puede ser distorsionada.
En resumen, las cargas permiten entender qué está midiendo cada componente, y el biplot es una herramienta visual poderosa para interpretar conjuntamente individuos y variables en el espacio reducido generado por PCA.
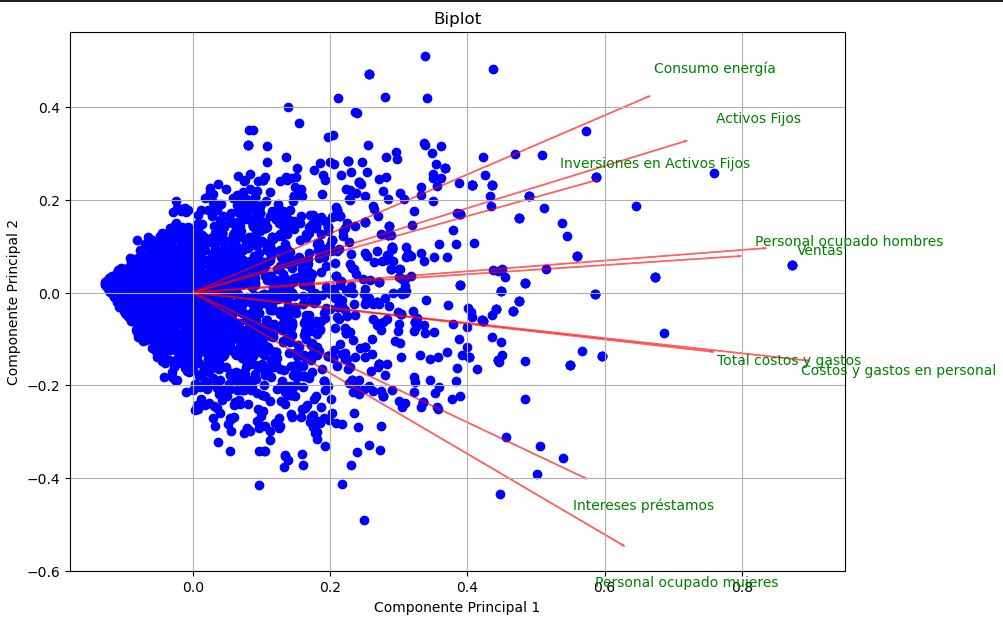
Biplot#
Unidades de las variables:#
Cuando se tienen variables con magnitudes grandes y otras pequeñas, se tiene un problema porque las variables de magnitud mayor van a predominar en la reducción de dimensionalidad y además, estas variables tienen mayor varianza. También, la covarianza entre las variables será mayor por la magnitud, siendo esto en muchos casos un resultado errado porque la covarianza estaría afectada por las unidades de las variables con unidades mayores y no por el co-movimiento.
Para solucionar esto tenemos dos opciones:
1. Cambio de escala de las variables:
2. Matriz de correlaciones: realizar el ACP sobre la matriz de coeficientes de correlación en lugar de la matriz de varianzas-covarianzas.
Como la diagonal tiene valores de 1,0, la suma de la diagonal es igual a \(p\), cantidad de variables.
Elegir el número correcto de dimensiones:#
En lugar de elegir arbitrariamente el número de dimensiones a reducir, es más sencillo elegir el número de dimensiones que sumen una porción suficientemente grande de la varianza (por ejemplo, el 80% o 95%). A menos que, por supuesto, estés reduciendo la dimensionalidad para la visualización de datos, en cuyo caso querrás reducir la dimensionalidad a 2 o 3.
Para esto se puede generar un gráfico que muestre la varianza explicada acumulada en función del número de componentes principales. La línea en el gráfico muestra cómo la varianza explicada se acumula a medida que se agregan más componentes principales. Al inicio, la varianza explicada aumenta rápidamente, lo que indica que las primeras componentes capturan la mayor parte de la variabilidad en los datos.
En muchos casos, hay un “punto de codo” en el gráfico donde la tasa de aumento de la varianza explicada se reduce significativamente. Este punto puede ser útil para determinar el número óptimo de componentes principales a utilizar, ya que más allá de este punto, agregar más componentes no proporciona una ganancia significativa en la varianza explicada.
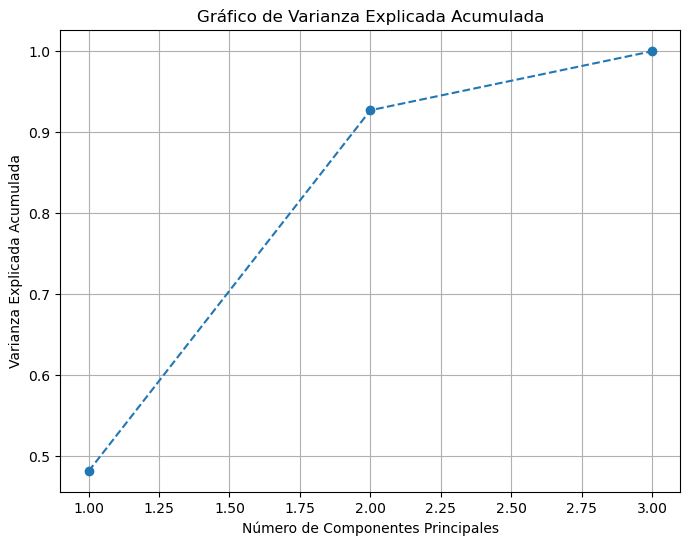
Codo#
Pruebas:#
La suma de las cargas de cada componente al cuadrado debe ser igual a 1,0:
Si los vectores son ortogonales, entonces el producto escalar de los vectores es igual a cero:
\(\sum{\lambda_i} = \sum{var_i}\): la suma de las varianzas de las variables es igual a la suma de los Eigenvalores.
Matriz de rotación vs. Cargas en PCA:#
La matriz de rotación contiene los autovectores de la matriz de covarianzas o correlaciones de los datos originales. Cada fila corresponde a una variable original, y cada columna a un componente principal.
Si tenemos
pvariables originales ykcomponentes principales, la matriz de rotación tiene dimensiónp × k.Los valores de esta matriz son los coeficientes de la combinación lineal que define cada componente principal.
Por ejemplo, si tenemos 3 variables y calculamos 2 componentes principales, la matriz podría verse así:
PC1 |
PC2 |
|
|---|---|---|
X1 |
0.70 |
-0.20 |
X2 |
0.50 |
0.85 |
X3 |
-0.45 |
0.47 |
Esto significa que:
\(PC1 = 0.70X_1 + 0.50X_2 − 0.45X_3\)
\(PC2 = −0.20X_1 + 0.85X_2 + 0.47X_3\)
Las cargas son una forma de interpretar la matriz de rotación. Indican la correlación entre cada variable original y cada componente principal.
Para obtener las cargas, se toma la matriz de rotación y se multiplica por la raíz cuadrada de la varianza (desviación estándar) explicada por cada componente:
\(Cargas = Rotación × \sqrt{(Autovalores)}\)
Valores cercanos a ±1 indican fuerte relación entre la variable y el componente.
Valores cercanos a 0 indican poca relación.
Ejemplo de cargas (continuando el ejemplo anterior):
PC1 |
PC2 |
|
|---|---|---|
X1 |
0.82 |
-0.10 |
X2 |
0.60 |
0.92 |
X3 |
-0.50 |
0.55 |
Interpretación:
\(X_1\) está fuertemente correlacionada con PC1.
\(X_2\) se asocia más a PC2.
\(X_3\) influye en ambos, con signo opuesto en PC1.
Cómo usar la matriz de rotación
La matriz de rotación permite:
Transformar los datos originales a los nuevos componentes principales.
Matemáticamente:
\(Z = X × Rotación\)
donde:
\(X\) = matriz de datos originales estandarizados, de tamaño \((n × p)\).
\(Rotación\) = matriz de componentes \((p × k)\).
\(Z\) = datos transformados en el espacio PCA \((n × k)\).
Reconstruir los datos aproximados a partir de los componentes principales:
\(X_{aprox} ≈ Z × Rotaciónᵀ\)
Esto se usa cuando reducimos la dimensionalidad y queremos volver a aproximar los datos originales.
Interpretación práctica
La matriz de rotación nos dice qué combinación de variables forma cada componente.
Las cargas nos dicen qué tan fuertemente cada variable original está asociada con cada componente.
En la práctica, se usan ambas para dar significado a los componentes y para entender qué miden en términos de las variables originales.