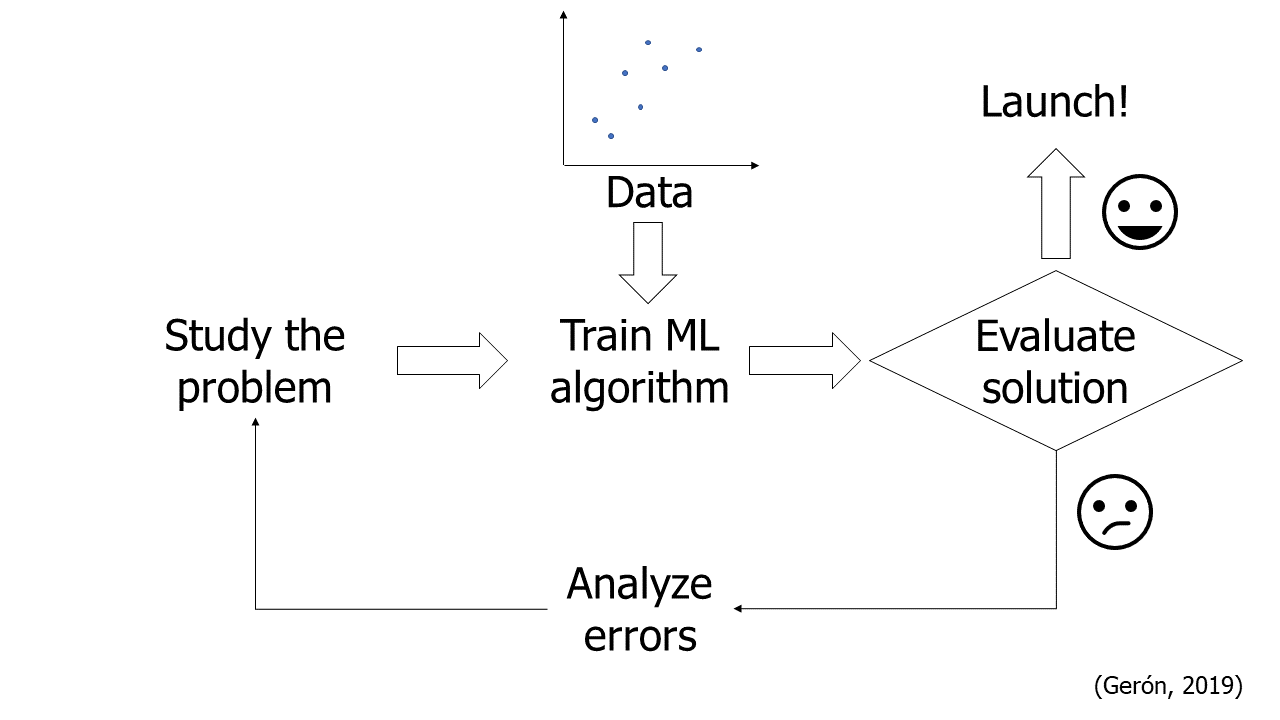
Proceso de Machine Learning#
El proceso de Machine Learning implica varias etapas clave para desarrollar modelos efectivos que resuelvan problemas específicos. A continuación, se detallan los pasos fundamentales de este proceso:
1. Estudiar el problema:
Definir los objetivos: Establecer claramente lo que se quiere lograr con el modelo. ¿Se busca predecir, clasificar, agrupar, etc.?
Identificar supuestos: Determinar las suposiciones bajo las cuales se debe desarrollar el modelo. Esto incluye aspectos como la independencia de las variables, linealidad, etc.
Medir el desempeño: Decidir las métricas de rendimiento que se utilizarán para evaluar el modelo, como la precisión, el recall, la matriz de confusión, etc.
2. Obtener los datos:
Recolectar datos: Obtener datos de fuentes relevantes que sean representativos del problema.
Formatear los datos: Convertir los datos a un formato fácil de manipular, como DataFrames en Python.
Verificar tipo y tamaño: Evaluar el tipo de datos (numéricos, categóricos) y asegurarse de que el tamaño del conjunto de datos sea adecuado para el modelo.
3. Explorar los datos para obtener información:
Análisis exploratorio de datos (EDA): Estudiar cada atributo, identificar el porcentaje de valores faltantes, analizar distribuciones, etc.
Visualización de datos: Usar herramientas gráficas para entender la distribución y las relaciones entre variables.
Análisis de correlación: Evaluar las correlaciones entre variables para identificar relaciones significativas.
4. Preparar los datos para el Machine Learning:
Manejo de outliers: Identificar y ajustar o eliminar outliers según sea necesario.
Tratamiento de valores faltantes: Imputar o eliminar valores faltantes para evitar sesgos en el modelo.
Selección de características: Eliminar variables redundantes o irrelevantes para mejorar la eficiencia del modelo.
Estandarización o normalización: Asegurar que las variables estén en la misma escala para mejorar el rendimiento de ciertos algoritmos.
5. Explorar y preseleccionar modelos:
Entrenamiento inicial: Probar varios algoritmos con configuraciones predeterminadas para identificar los más prometedores.
Comparación de desempeño: Usar métricas de rendimiento para comparar modelos y seleccionar los mejores.
Selección de modelos candidatos: Identificar los modelos que mejor se adaptan al problema para un ajuste más detallado.
6. Ajustar los modelos:
Optimización de hiperparámetros: Utilizar técnicas como
Grid SearchoRandom Searchpara ajustar los hiperparámetros.Evaluación final: Probar el modelo ajustado en un conjunto de prueba para evaluar su desempeño y estimar el error de generalización.
7. Presentar la solución:
Interpretación de resultados: Explicar los resultados del modelo de manera comprensible para los interesados.
Generación de reportes: Crear informes que resuman los hallazgos y las recomendaciones.
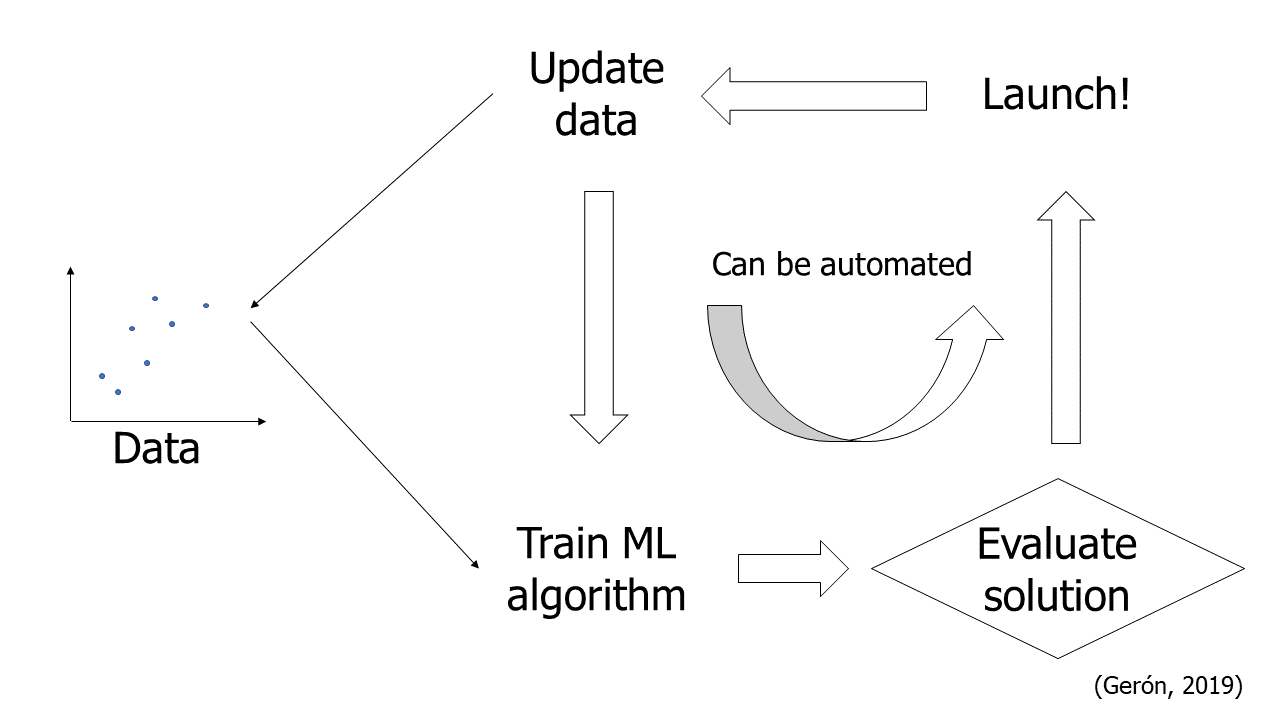
8. Desplegar, supervisar y mantener el sistema:
Implementación: Poner el modelo en producción para su uso en el entorno real.
Supervisión continua: Monitorizar el desempeño del modelo y ajustar según sea necesario para mantener su efectividad.
Consejo: Automatizar cada paso siempre que sea posible para aumentar la eficiencia y consistencia del proceso.
Proyectos de ML#
automatedML#
Tipos de problemas en Machine Learning:#
El Machine Learning se centra en aprender patrones a partir de datos para predecir eventos futuros o identificar estructuras subyacentes. Los enfoques principales son el aprendizaje supervisado y el no supervisado, que se diferencian principalmente en el uso de etiquetas.
Aprendizaje supervisado:#
En el aprendizaje supervisado, los modelos se entrenan con datos etiquetados, donde cada ejemplo de entrenamiento tiene un resultado esperado. Este enfoque se utiliza para tareas de clasificación y regresión.
Clasificación:
La clasificación implica asignar etiquetas discretas a las observaciones. Es útil para problemas como la detección de spam, clasificación de imágenes, diagnóstico médico, etc. Ejemplos de etiquetas comunes incluyen Sí/No, Positivo/Negativo, o categorías específicas.
ID cliente |
Edad |
Género |
Salario |
¿Pagó? |
|---|---|---|---|---|
1 |
50 |
F |
1000 |
Si |
2 |
18 |
M |
800 |
No |
3 |
44 |
F |
2000 |
No |
4 |
60 |
M |
1500 |
No |
5 |
32 |
M |
1200 |
Si |
. |
. |
. |
. |
. |
. |
. |
. |
. |
. |
. |
. |
. |
. |
. |
100000 |
32 |
M |
1850 |
Si |
Regresión:
La regresión se utiliza para predecir valores continuos basados en una o más variables independientes. Es útil en situaciones como la predicción de precios, estimación de la demanda, análisis de tendencias, etc.
ID cliente |
Edad |
Género |
Salario |
Valor compra |
|---|---|---|---|---|
1 |
50 |
F |
1000 |
100 |
2 |
18 |
M |
800 |
20 |
3 |
44 |
F |
2000 |
50 |
4 |
60 |
M |
1500 |
1000 |
5 |
32 |
M |
1200 |
22 |
. |
. |
. |
. |
. |
. |
. |
. |
. |
. |
. |
. |
. |
. |
. |
100000 |
32 |
M |
1850 |
200 |
Algoritmos de aprendizaje supervisado:
Regresión Lineal: Modela la relación entre variables dependientes e independientes de forma lineal.
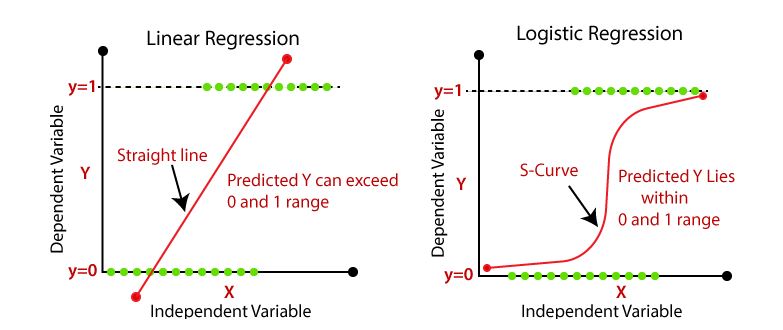
Regresión Logística: Utilizada para problemas de clasificación binaria al modelar probabilidades.
Máquinas de Vectores de Soporte (SVM): Busca un hiperplano óptimo para separar clases en el espacio de características.
Árboles de Decisión y Bosques Aleatorios (Random Forests): Modelos basados en árboles de decisión que mejoran la precisión mediante la agregación.
Redes Neuronales Artificiales: Algoritmos inspirados en el cerebro humano, capaces de modelar relaciones complejas en los datos.
Aprendizaje no supervisado:#
El aprendizaje no supervisado se utiliza cuando no se dispone de datos etiquetados. Su objetivo es descubrir patrones ocultos o estructuras en los datos.
Agrupamiento (Clustering):
El agrupamiento organiza los datos en grupos (clusters) de manera que los objetos dentro del mismo grupo sean más similares entre sí que aquellos en diferentes grupos. Es útil para segmentación de clientes, detección de anomalías, etc.
Reducción de dimensionalidad:
La reducción de dimensionalidad busca simplificar los datos preservando la información importante. Ayuda a visualizar datos complejos y mejorar el rendimiento de los modelos.
ID cliente |
Edad |
Género |
Salario |
|---|---|---|---|
1 |
50 |
F |
1000 |
2 |
18 |
M |
800 |
3 |
44 |
F |
2000 |
4 |
60 |
M |
1500 |
5 |
32 |
M |
1200 |
. |
. |
. |
. |
. |
. |
. |
. |
. |
. |
. |
. |
100000 |
32 |
M |
1850 |
Algoritmos de aprendizaje no supervisado:
Clustering:
K-Means: Agrupa datos en k clusters basándose en la similitud.
Clustering Jerárquico: Crea una jerarquía de clusters mediante un enfoque de división o aglomeración.
DBSCAN: Detecta clusters de forma arbitraria basándose en la densidad de puntos de datos.
Reducción de dimensionalidad:
Análisis de Componentes Principales (PCA): Transforma datos en un nuevo espacio de características reducidas.
Kernel PCA: Variante de PCA que utiliza kernels para capturar estructuras no lineales.
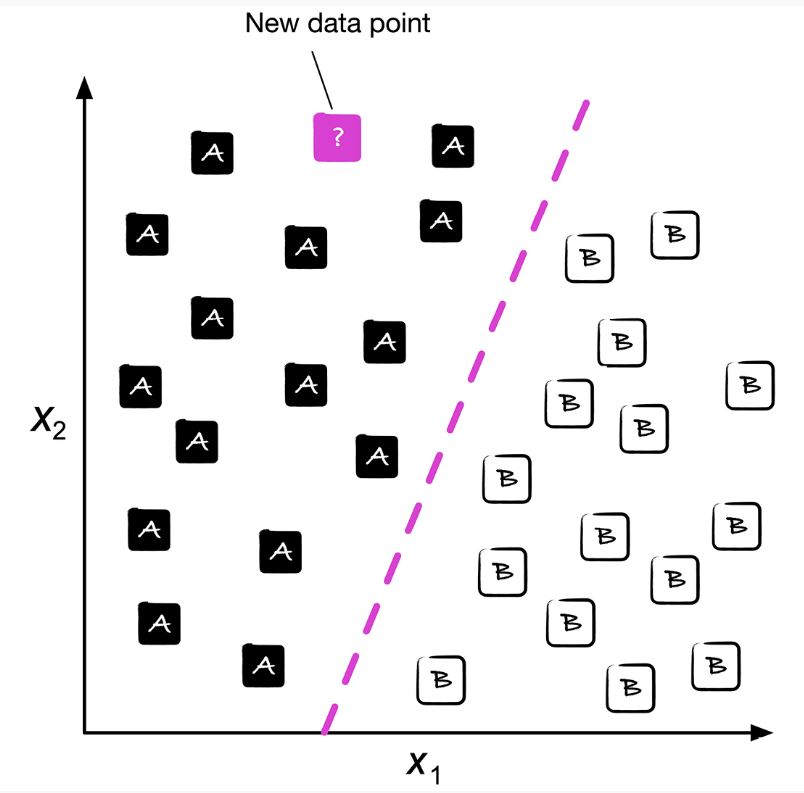
Classification (Raschka, 2022)#
Regression (Raschka, 2022)#
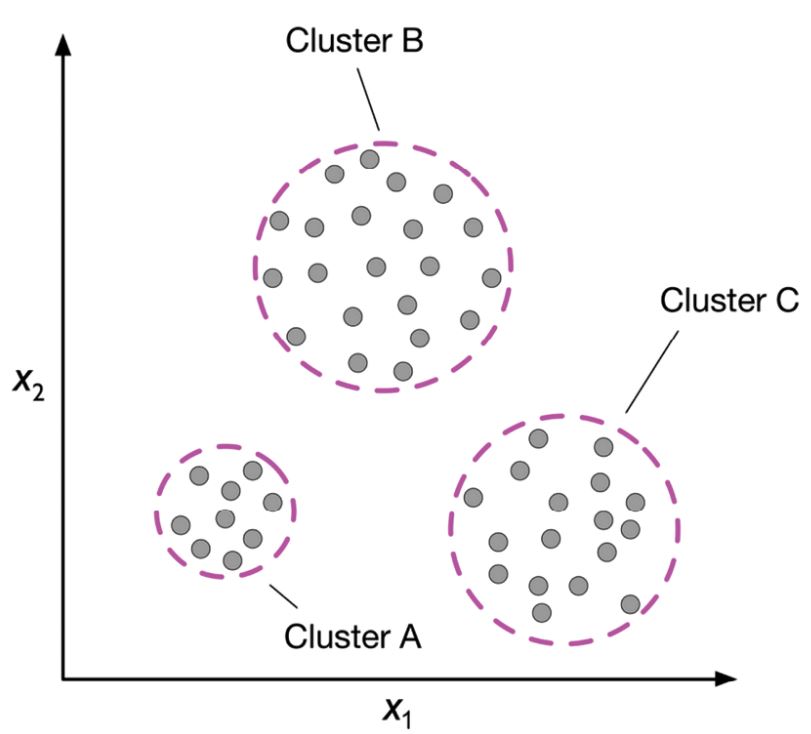
Clustering (Raschka, 2022)#
Paso a paso en los procesos de Machine Learning (ML):#
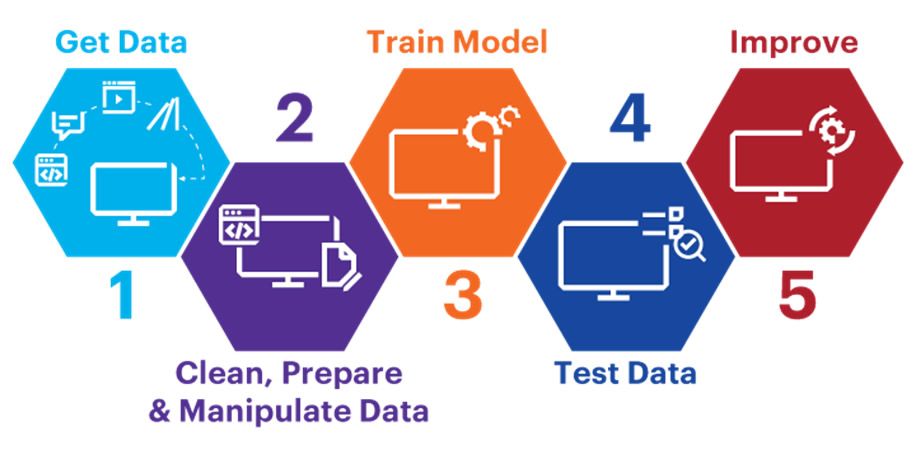
Pasos-Machine-Learning#
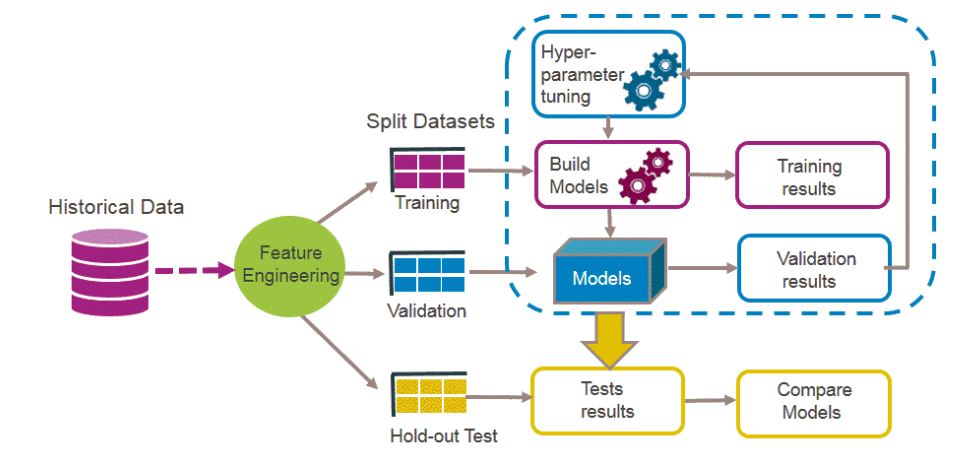
Steps-ML#