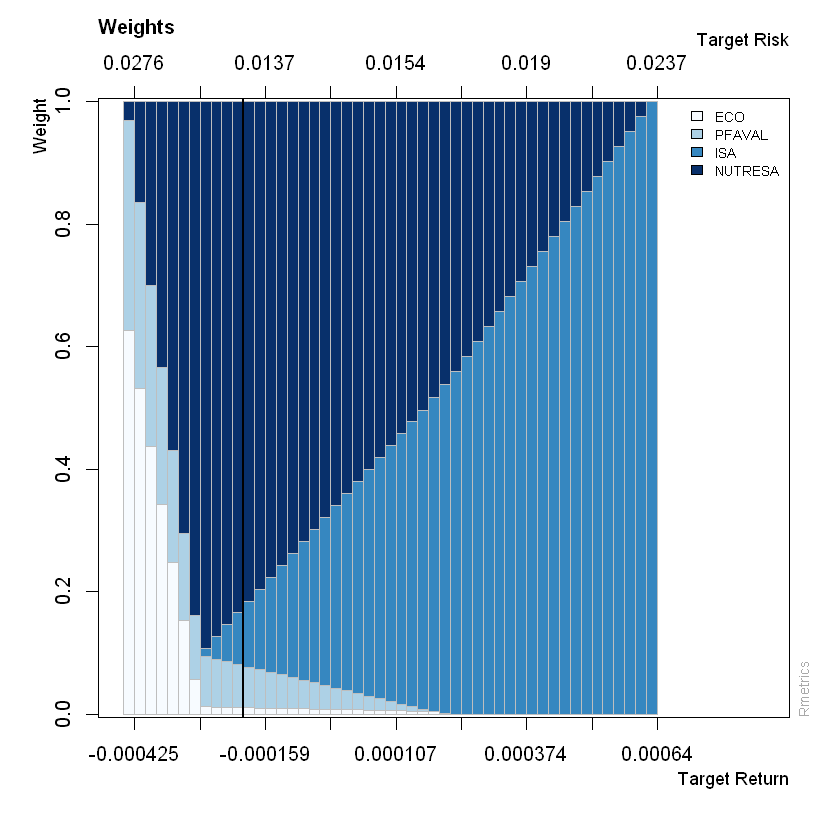
Ejemplo K-Means#
Importar librerías y generar datos ficticios:
import numpy as np
import pandas as pd
from sklearn.cluster import KMeans
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import silhouette_score
import matplotlib.pyplot as plt
# Generar datos ficticios
np.random.seed(42)
X = np.vstack(
[
np.random.normal(loc=0, scale=0.5, size=(100, 2)),
np.random.normal(loc=3, scale=0.5, size=(100, 2)),
np.random.normal(loc=6, scale=0.5, size=(100, 2)),
]
)
data = pd.DataFrame(X, columns=["Feature1", "Feature2"])
# Visualizar los datos generados
plt.scatter(data["Feature1"], data["Feature2"])
plt.xlabel("Feature1")
plt.ylabel("Feature2")
plt.title("Datos Ficticios")
plt.show()

Escalar las variables:
# Escalar los datos
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
scikit-learn:#
Por defecto n_clusters=8 y las iteraciones max_iter=300.
kmeans = KMeans(n_clusters=2, random_state=34)
kmeans.fit(X_scaled)
KMeans(n_clusters=2, random_state=34)
Centroides:
kmeans.cluster_centers_
array([[-1.20952284, -1.19727913],
[ 0.61387843, 0.60766428]])
# Ver los centroides de cada clúster
centroides = pd.DataFrame(
scaler.inverse_transform(kmeans.cluster_centers_), columns=["Feature1", "Feature2"]
)
print(centroides)
Feature1 Feature2
0 -0.043553 0.041474
1 4.536589 4.489311
Etiquetas:
kmeans.labels_
array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1])
# Visualizar los clústeres
plt.figure(figsize=(8, 4))
plt.scatter(data["Feature1"], data["Feature2"], c=kmeans.labels_, cmap="viridis")
plt.scatter(centroides["Feature1"], centroides["Feature2"],
s=300, c="red", label="Centroides")
plt.xlabel("Feature1")
plt.ylabel("Feature2")
plt.title("Clustering con K-Means")
plt.legend()
plt.show()
WCSS:
kmeans.inertia_
158.98687738372277
Cantidad de iteraciones:
kmeans.n_iter_
6
Código optimizado:#
Determinar el número óptimo de Clústeres usando el Método del Codo:
# Calcular WCSS para diferentes valores de K
wcss = []
K = range(1, 10)
for k in K:
kmeans = KMeans(n_clusters=k, random_state=34)
kmeans.fit(X_scaled)
wcss.append(kmeans.inertia_)
# Visualizar el método del codo
plt.figure(figsize=(8, 4))
plt.plot(K, wcss, "bo-")
plt.xlabel("Número de clústeres (K)")
plt.ylabel("WCSS")
plt.title("Método del Codo para determinar el número óptimo de clústeres")
plt.show()
Determinar el número óptimo de Clústeres usando el Método de la Silueta:
# Calcular la puntuación de la silueta para diferentes valores de K
silhouette_scores = []
K = range(2, 11)
for k in K:
kmeans = KMeans(n_clusters=k, random_state=34)
kmeans.fit(X_scaled)
labels = kmeans.labels_
score = silhouette_score(X_scaled, labels)
silhouette_scores.append(score)
# Visualizar la puntuación de la silueta
plt.figure(figsize=(8, 4))
plt.plot(K, silhouette_scores, "bo-")
plt.xlabel("Número de clústeres (K)")
plt.ylabel("Puntuación de la Silueta")
plt.title("Método de la Silueta para determinar el número óptimo de clústeres")
plt.show()
Ajustar K-Means con el número óptimo de Clústeres:
optimal_k = 3
# Ajustar K-Means con el número óptimo de clústeres
kmeans = KMeans(n_clusters=optimal_k, random_state=34)
kmeans.fit(X_scaled)
data["cluster"] = kmeans.labels_
# Ver los centroides de cada clúster
centroides = pd.DataFrame(scaler.inverse_transform(kmeans.cluster_centers_),
columns=["Feature1", "Feature2"])
print(centroides)
# Visualizar los clústeres
plt.figure(figsize=(8, 4))
plt.scatter(data["Feature1"], data["Feature2"], c=data["cluster"], cmap="viridis")
plt.scatter(
centroides["Feature1"], centroides["Feature2"], s=300, c="red", label="Centroides"
)
plt.xlabel("Feature1")
plt.ylabel("Feature2")
plt.title("Clustering con K-Means")
plt.legend()
plt.show()
Feature1 Feature2
0 -0.057782 0.017011
1 5.977481 5.936864
2 3.064124 3.021744
Iteraciones:#
# Visualizar K-Means con diferentes valores de K
fig, axes = plt.subplots(3, 3, figsize=(15, 15))
axes = axes.flatten()
for i, k in enumerate(range(1, 10)):
kmeans = KMeans(n_clusters=k, random_state=42)
kmeans.fit(X_scaled)
data["cluster"] = kmeans.labels_
# Ver los centroides de cada clúster
centroides = pd.DataFrame(scaler.inverse_transform(kmeans.cluster_centers_),
columns=["Feature1", "Feature2"],)
# Visualizar los clústeres
ax = axes[i]
ax.scatter(data["Feature1"], data["Feature2"], c=data["cluster"], cmap="viridis")
ax.scatter(
centroides["Feature1"],
centroides["Feature2"],
s=300,
c="red",
label="Centroides",
)
ax.set_title(f"K-Means con K={k}")
ax.set_xlabel("Feature1")
ax.set_ylabel("Feature2")
plt.tight_layout()
plt.show()