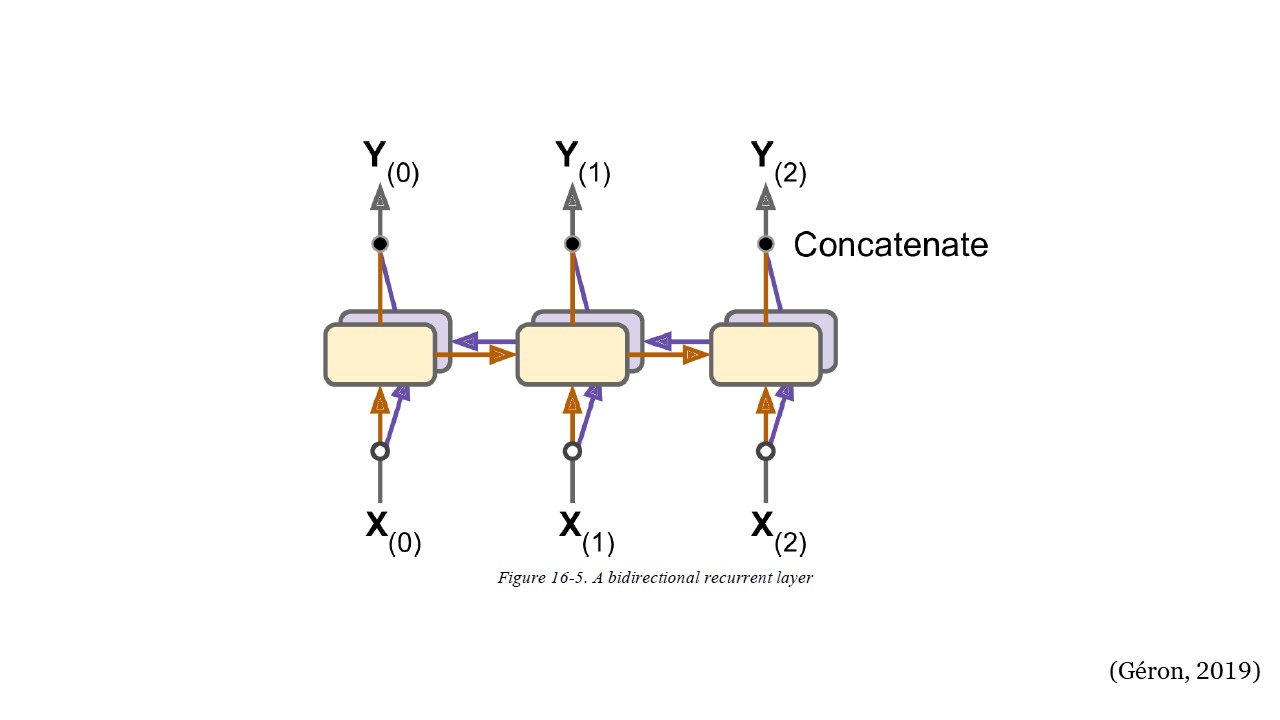
RNN Bidireccional#
En cada paso de tiempo, una capa recurrente regular solo mira las entradas pasadas y presentes antes de generar su salida. En otras palabras, es “causal”, lo que significa que no puede mirar hacia el futuro. A menudo es preferible mirar hacia adelante en las siguientes predicciones antes de codificar una predicción determinada.
Para implementar esto, se ejecutan dos capas recurrentes en las mismas
entradas, una leyendo la información de izquierda a derecha y la otra de
derecha a izquierda. Luego, simplemente combina las salidas en cada paso
de tiempo, generalmente concatenándolas. Esto se denomina capa
recurrente bidireccional (consulte la siguiente figura). Para
implementar una capa recurrente bidireccional en Keras, envuelva una
capa recurrente en una capa Bidirectional.
La capa bidireccional creará un clon de la capa recurrente (RNN, LSTM o RNN), pero en la dirección inversa y ejecutará ambas y concatenará sus salidas. Entonces, aunque la capa recurrente tiene ciertas unidades, la capa bidireccional generará el doble de valores por paso de tiempo.
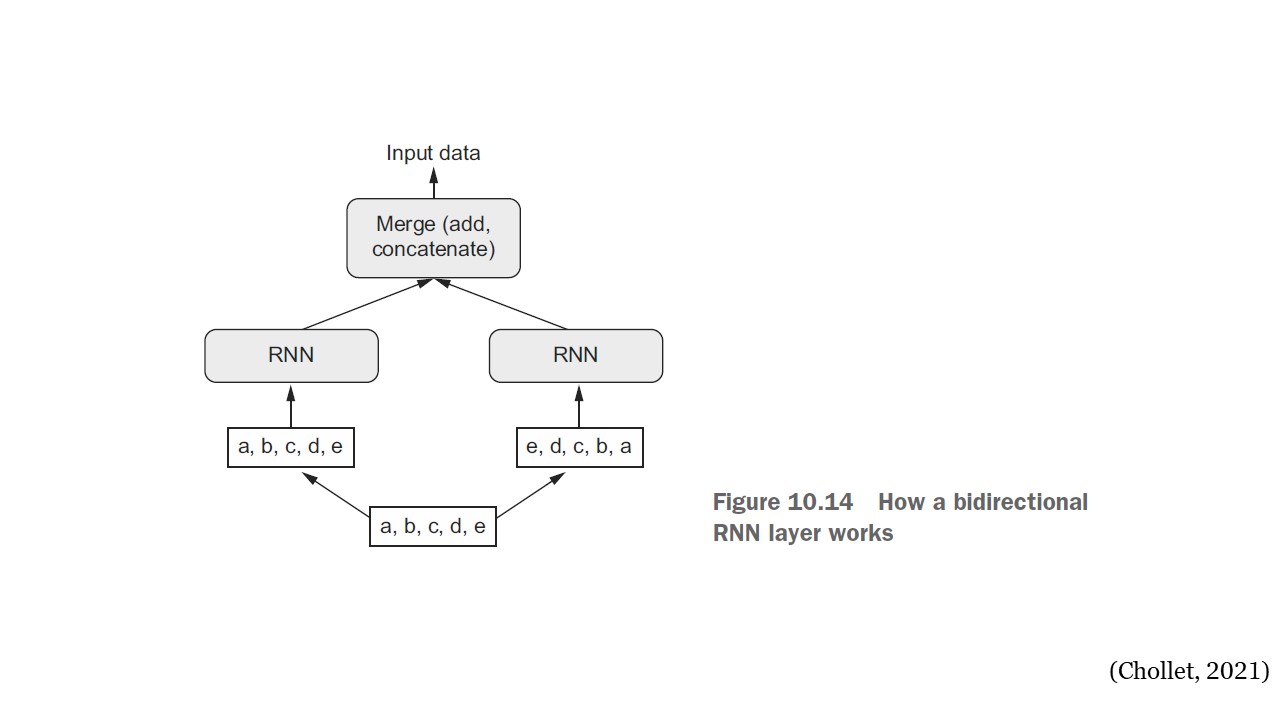
Bidirectional#
Los RNN son dependientes del orden: procesan los pasos de tiempo de sus secuencias de entrada en orden, y mezclar o invertir los pasos de tiempo puede cambiar completamente las representaciones que el RNN extrae de la secuencia. Esta es precisamente la razón por la que funcionan bien en problemas donde el orden es significativo, como en los problemas de pronóstico.
Una RNN bidireccional explota la sensibilidad al orden de las RNN: utiliza dos RNN normales, como las capas GRU y LSTM, cada una de las cuales procesa la secuencia de entrada en una dirección (cronológica y anticronológicamente) y luego fusiona sus representaciones. Al procesar una secuencia en ambos sentidos, un RNN bidireccional puede detectar patrones que un RNN unidireccional puede pasar por alto. Sorprendentemente, el hecho de que las capas RNN en esta sección hayan procesado secuencias en orden cronológico (con los pasos de tiempo más antiguos primero) puede haber sido una decisión arbitraria.
BidirectionalWorks#
Código:#
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import yfinance as yf
from sklearn.preprocessing import StandardScaler
import warnings # Para ignorar mensajes de advertencia
warnings.filterwarnings("ignore")
Descargar datos desde Yahoo Finance:#
tickers = ["ES=F"]
ohlc = yf.download(tickers, period="max")
print(ohlc.tail())
[*******************100%*********************] 1 of 1 completed
Open High Low Close Adj Close Volume
Date
2022-08-25 4148.75 4202.75 4143.00 4201.00 4201.00 1635476
2022-08-26 4198.25 4217.25 4042.75 4059.50 4059.50 2241117
2022-08-29 4024.00 4064.00 4006.75 4031.25 4031.25 1963446
2022-08-30 4035.75 4072.75 3964.50 3987.50 3987.50 1963446
2022-08-31 3987.25 4014.00 3982.25 4010.25 4010.25 57939
df = ohlc["Adj Close"].dropna(how="all")
df.tail()
Date
2022-08-25 4201.00
2022-08-26 4059.50
2022-08-29 4031.25
2022-08-30 3987.50
2022-08-31 4010.25
Name: Adj Close, dtype: float64
df = np.array(df[:, np.newaxis])
df.shape
(5549, 1)
plt.figure(figsize=(10, 6))
plt.plot(df)
plt.show()

Conjunto de train y test:#
time_test = 0.20
train = df[: int(len(df) * (1 - time_test))]
test = df[int(len(df) * (1 - time_test)) :]
plt.plot(train)
plt.xlabel("Tiempo")
plt.ylabel("Precio")
plt.title("Conjunto de train")
plt.show()
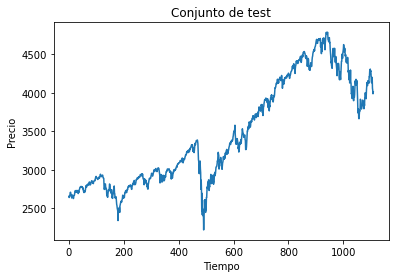
plt.plot(test)
plt.xlabel("Tiempo")
plt.ylabel("Precio")
plt.title("Conjunto de test")
plt.show()
Función para conformar el dataset para datos secuenciales:
def split_sequence(sequence, time_step):
X, y = list(), list()
for i in range(len(sequence)):
end_ix = i + time_step
if end_ix > len(sequence) - 1:
break
seq_x, seq_y = sequence[i:end_ix], sequence[end_ix]
X.append(seq_x)
y.append(seq_y)
return np.array(X), np.array(y)
time_step = 5
X_train, y_train = split_sequence(train, time_step)
X_test, y_test = split_sequence(test, time_step)
Arquitectura de la red RNN bidireccional:#
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import GRU
from keras.layers import LSTM
from keras.layers import Bidirectional
Las capas Bidirectional realizan su proceso sobre las capas RNN, las
cuales hemos visto la SimpleRNN, LSTM y GRU.
RNN Bidireccional en capas LSTM:#
model = Sequential()
model.add(Bidirectional(GRU(10, activation="relu", return_sequences=True)))
model.add(Bidirectional(GRU(4, activation="relu")))
model.add(Dense(1))
model.compile(optimizer="adam", loss="mse")
history = model.fit(
X_train,
y_train,
validation_data=(X_test, y_test),
epochs=30,
batch_size=50,
verbose=0
)
Evaluación del desempeño:#
mse = model.evaluate(X_test, y_test, verbose=0)
mse
1917.8154296875
rmse = mse ** 0.5
rmse
43.79286962152058
plt.plot(range(1, len(history.epoch) + 1), history.history["loss"], label="Train")
plt.plot(range(1, len(history.epoch) + 1), history.history["val_loss"], label="Test")
plt.xlabel("epoch")
plt.ylabel("Loss")
plt.legend();
Predicción del modelo:#
y_pred = model.predict(X_test, verbose=0)
y_pred[0:5]
array([[2680.1423],
[2703.487 ],
[2709.6199],
[2697.1606],
[2677.965 ]], dtype=float32)
plt.figure(figsize=(18, 6))
plt.plot(
range(1, len(X_test) + 1),
test[time_step:, :],
color="b",
marker=".",
linestyle="-",
label="True",
)
plt.plot(
range(1, len(X_test) + 1),
y_pred,
color="g",
marker=".",
linestyle="-",
label="y_pred",
)
plt.legend();
Predicción fuera de la muestra:#
predictions = []
time_prediction = 20 # cantidad de predicciones fuera de la muestra
first_sample = df[-time_step:, 0] # última muestra dentro de la serie de tiempo
current_batch = first_sample[np.newaxis] # Transformación en muestras y time step
current_batch = np.reshape(current_batch, (1, time_step, 1)) # Transformación en 3D
for i in range(time_prediction):
current_pred = model.predict(current_batch, verbose=0)[0]
# Guardar la predicción
predictions.append(current_pred)
# Actualizar el lote para incluir ahora la predicción y soltar el primer valor (primer time step)
current_batch = np.append(current_batch[:, 1:], [[current_pred]])[np.newaxis]
current_batch = np.reshape(current_batch, (1, time_step, 1)) # Transformación en 3D
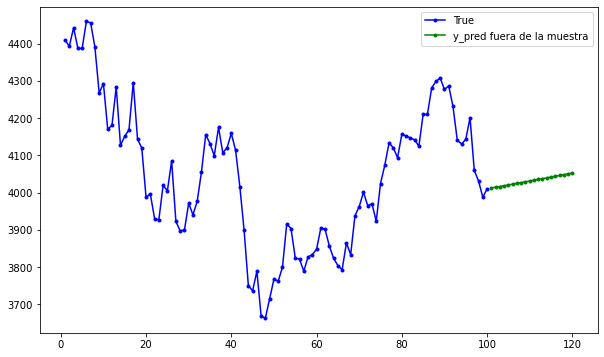
plt.figure(figsize=(10, 6))
plt.plot(
range(1, len(df[-100:, 0]) + 1),
df[-100:, 0],
color="b",
marker=".",
linestyle="-",
label="True",
)
plt.plot(
range(len(df[-100:, 0]) + 1, len(df[-100:, 0]) + len(predictions) + 1),
predictions,
color="g",
marker=".",
linestyle="-",
label="y_pred fuera de la muestra",
)
plt.legend();