Ensemble Learning#
Imagina que haces una pregunta compleja a una gran cantidad de personas elegidas al azar y luego combinas sus respuestas. En muchos casos, la respuesta combinada es más precisa que la de un solo experto. Esto se conoce como la “sabiduría de las multitudes”. De manera similar, si combinas las predicciones de un grupo de modelos predictivos (como clasificadores o regresores), a menudo obtendrás resultados más precisos que utilizando el mejor modelo individual. Un conjunto de modelos se denomina Ensemble, y la técnica que utiliza este enfoque se llama Ensemble Learning (Aprendizaje de Conjunto). Por lo tanto, un algoritmo que implementa esta técnica se conoce como un método de Ensemble.
Ensemble Learning es una técnica en aprendizaje automático que busca mejorar el rendimiento y la precisión de los modelos combinando múltiples modelos individuales, conocidos como predictores o aprendices. La idea principal es que al combinar varios modelos, el modelo conjunto resultante puede capturar mejor la diversidad y complejidad de los datos, lo que generalmente conduce a mejores predicciones que cualquier modelo individual por sí solo.
Conceptos clave:#
1. Diversidad de predictores:
Los métodos de conjunto funcionan mejor cuando los predictores son diversos e independientes entre sí. La diversidad asegura que los errores de un modelo individual se compensen con las predicciones correctas de otros modelos.
Se pueden usar diferentes tipos de modelos, algoritmos de entrenamiento o incluso diferentes subconjuntos de datos para generar esta diversidad.
2. Tipos de Ensemble Learning:
Bagging (Bootstrap Aggregating): Consiste en entrenar múltiples modelos de la misma clase en diferentes subconjuntos aleatorios del conjunto de datos con reemplazo. Cada modelo contribuye de igual manera a la predicción final, que generalmente es el promedio en regresión o la mayoría de votos en clasificación.
Boosting: Entrena modelos secuencialmente, donde cada modelo trata de corregir los errores del modelo anterior. Los modelos se ponderan de acuerdo a su rendimiento, y el conjunto final se forma como una suma ponderada de todos los modelos.
Stacking: Combina diferentes tipos de modelos base en capas. Las predicciones de los modelos en la capa base se utilizan como características de entrada para un modelo de nivel superior (meta-modelo), que realiza la predicción final.
3. Ventajas de Ensemble Learning:
Mejora de precisión: Al combinar múltiples modelos, se logra una mayor precisión en las predicciones.
Robustez: Reduce el riesgo de sobreajuste y varianza en comparación con modelos individuales, especialmente cuando se enfrenta a datos ruidosos o complejos.
Flexibilidad: Permite la utilización de diferentes modelos y técnicas de aprendizaje, adaptándose a las características del problema.
4. Ejemplos de algoritmos de Ensemble:
Random Forest: Un tipo de bagging que utiliza árboles de decisión como modelos base y introduce aleatoriedad adicional en el proceso de construcción de los árboles.
AdaBoost: Un método de boosting que ajusta iterativamente el peso de las instancias de entrenamiento mal clasificadas para mejorar la precisión.
Gradient Boosting: Similar a AdaBoost, pero se centra en ajustar los errores residuales en lugar de cambiar los pesos de las instancias.
XGBoost: es una implementación optimizada de Gradient Boosting que mejora la eficiencia, la escalabilidad y la capacidad de ajuste del modelo. Mientras que el algoritmo subyacente es el mismo (Gradient Boosting), XGBoost incorpora mejoras prácticas y avanzadas que pueden llevar a un mejor rendimiento en la práctica.
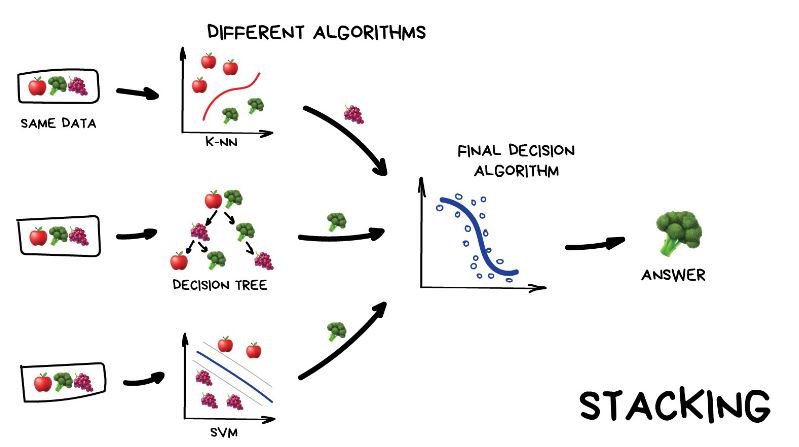
Stacking#
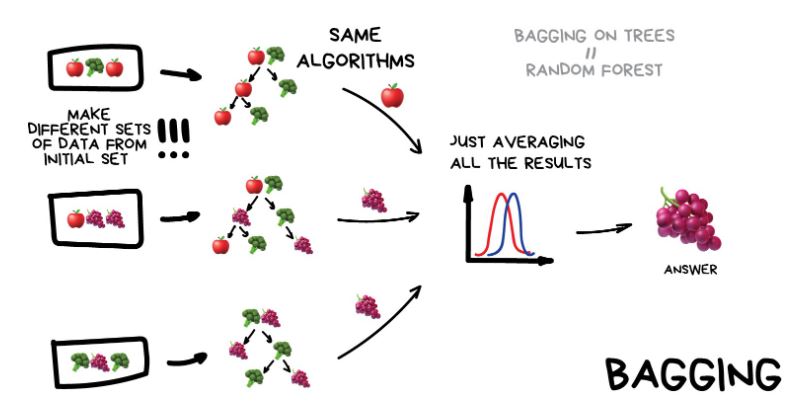
Bagging#
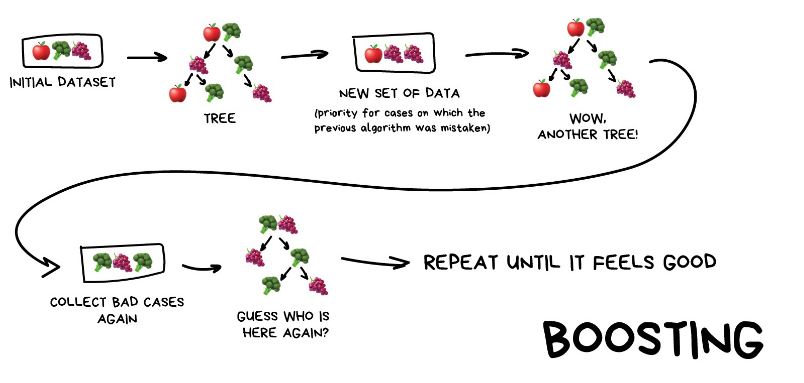
Boosting#
Voting Classifiers:#
Un Voting Classifier es un tipo de ensemble que combina las predicciones de múltiples modelos base para mejorar el rendimiento predictivo. La idea es sencilla: cada modelo base hace una predicción para una instancia dada, y luego se utilizan estas predicciones para determinar la clase final. Existen dos tipos principales de votación:
1. Votación Dura (Hard Voting):
En la votación dura, cada modelo base vota por una clase específica, y la clase que recibe la mayoría de los votos es la predicción final del ensemble.
Es similar a un sistema de mayoría de votos, donde la opción más popular se selecciona como el resultado final.
Este método es útil cuando se tiene una diversidad significativa entre los modelos, ya que cada uno puede capturar diferentes patrones en los datos.
2. Votación Suave (Soft Voting):
En la votación suave, cada modelo base predice una probabilidad para cada clase, y estas probabilidades se promedian para determinar la clase final.
La clase con la mayor probabilidad promedio se selecciona como la predicción final.
La votación suave tiende a ser más precisa que la votación dura, ya que tiene en cuenta la confianza de cada modelo en sus predicciones.
Requiere que los modelos base sean capaces de estimar probabilidades de clase (es decir, tener un método
predict_proba()).
Ventajas de Voting Classifiers:
Mejora del rendimiento: Al combinar varios modelos, los clasificadores de votación pueden lograr una precisión mayor que cualquier modelo individual.
Robustez: Ayuda a mitigar los errores que puedan surgir de cualquier modelo específico, especialmente si los modelos son diversos e independientes.
Flexibilidad: Permite combinar modelos de diferentes tipos (por ejemplo, árboles de decisión, SVM, regresión logística), lo que puede ayudar a capturar diferentes aspectos de los datos.