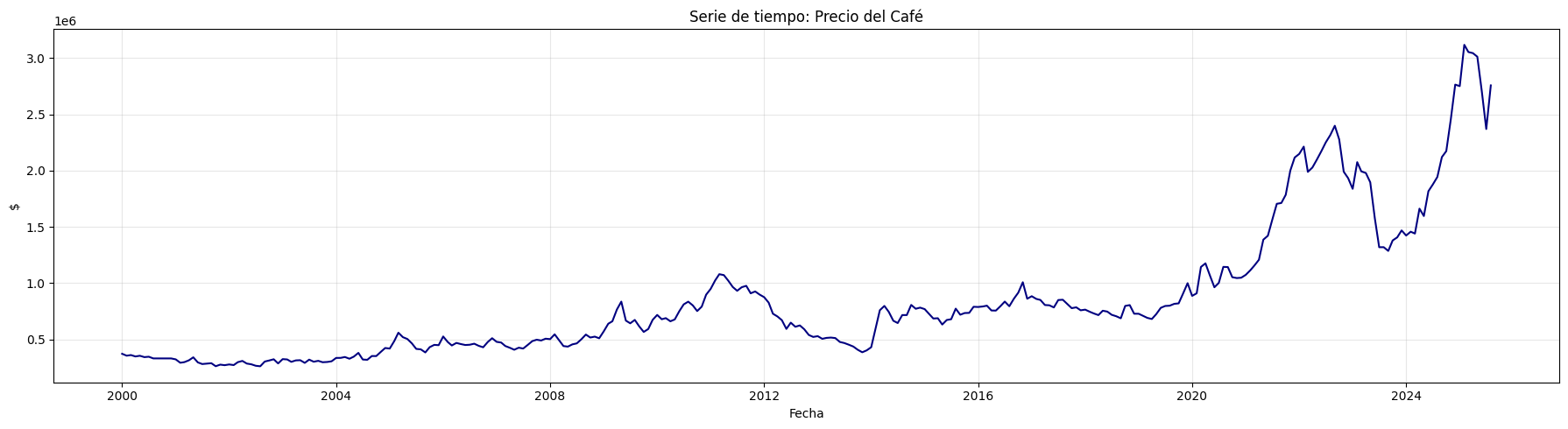
Transformaciones y análisis de estacionariedad#
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib.dates as mdates
from statsmodels.tsa.stattools import adfuller
from statsmodels.graphics.tsaplots import plot_acf, plot_pacf
Precio interno del Café:#
# Cargar el archivo xlsx:
serie_cafe = pd.read_excel('Precio_interno_cafe.xlsx')
# Corregir nombres de columnas si tienen espacios
serie_cafe.columns = serie_cafe.columns.str.strip()
# Convertir 'Fecha' a datetime y usar como índice
serie_cafe['Fecha'] = pd.to_datetime(serie_cafe['Fecha'])
serie_cafe.set_index('Fecha', inplace=True)
# Ordenar por fecha por si acaso
serie_cafe = serie_cafe.sort_index()
# Establecer frecuencia explícita para evitar el warning de statsmodels
serie_cafe.index.freq = serie_cafe.index.inferred_freq
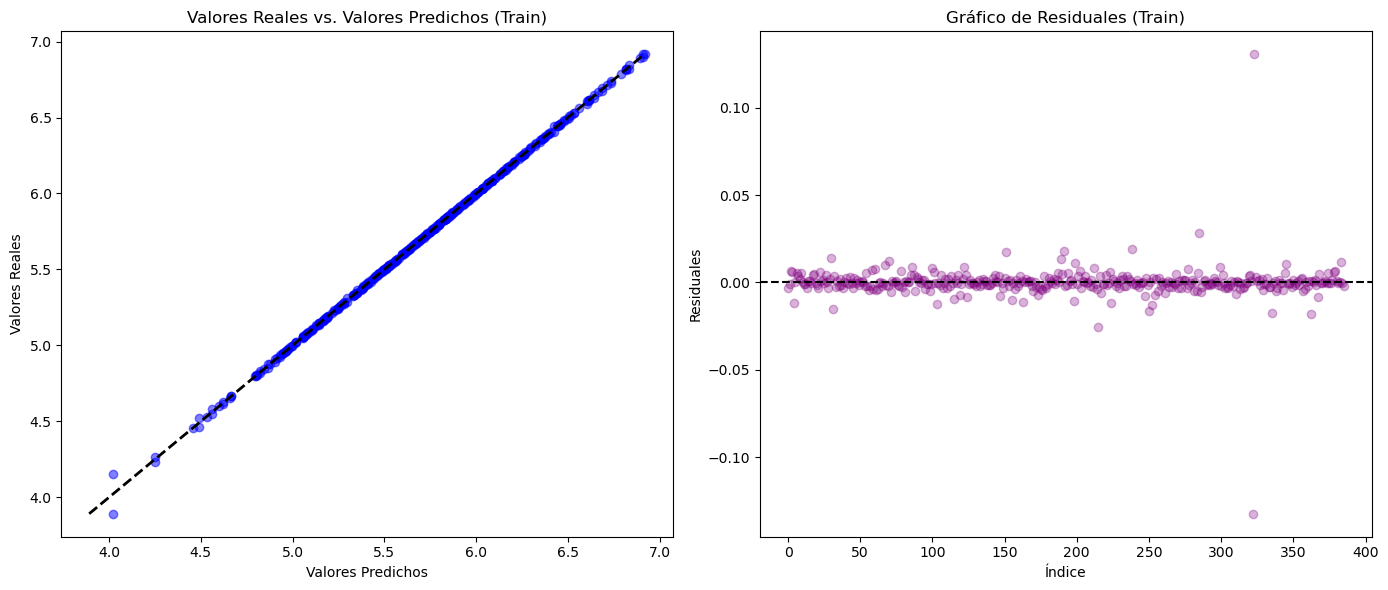
plt.figure(figsize=(18, 5))
plt.plot(serie_cafe, color='navy')
plt.title("Serie de tiempo: Precio del Café")
plt.xlabel("Fecha")
plt.ylabel("$")
plt.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
serie_cafe.head()
| Precio | |
|---|---|
| Fecha | |
| 2000-01-01 | 371375.0 |
| 2000-02-01 | 354297.0 |
| 2000-03-01 | 360016.0 |
| 2000-04-01 | 347538.0 |
| 2000-05-01 | 353750.0 |
serie = "Precio interno del Café"
# Serie original y transformaciones:
serie_1 = serie_cafe.copy()
serie_2 = serie_1.diff().dropna()
serie_3 = np.log(serie_1)
serie_4 = serie_3.diff().dropna()
titulos = [f"Serie original: {serie}",
"Diferenciación",
"Logaritmo",
"Diferenciación del Logaritmo"]
series = [serie_1, serie_2, serie_3, serie_4]
# ADF test y etiquetas de estacionariedad
resultados_adf = []
interpretaciones = []
for i, serie in enumerate(series):
serie_ = serie.dropna()
# Seleccionar el tipo de regresión adecuado:
if i in [0, 2]: # serie_1 y serie_3
adf = adfuller(serie_, regression='ct') # constante y tendencia
else: # serie_2 y serie_4
adf = adfuller(serie_, regression='c') # solo constante
estadistico = adf[0]
pvalue = adf[1]
resultados_adf.append((estadistico, pvalue))
if pvalue < 0.05:
interpretaciones.append("Estacionaria")
else:
interpretaciones.append("No estacionaria")
# Gráfico 4 filas × 3 columnas
fig, axes = plt.subplots(4, 3, figsize=(18, 16))
for fila in range(4):
# Serie
color = 'navy' if fila == 0 else 'forestgreen' if fila == 1 else 'darkgreen'
axes[fila, 0].plot(series[fila], color=color)
axes[fila, 0].set_title(titulos[fila])
axes[fila, 0].set_xlabel("Fecha")
if fila == 0:
axes[fila, 0].set_ylabel("Valor")
elif fila == 1:
axes[fila, 0].set_ylabel("Δ Valor")
elif fila == 2:
axes[fila, 0].set_ylabel("Log(Valor)")
else:
axes[fila, 0].set_ylabel("Δ Log(Valor)")
axes[fila, 0].grid(True, alpha=0.3)
# ACF
plot_acf(series[fila].dropna(), lags=24, ax=axes[fila, 1], zero=False, color='navy')
axes[fila, 1].set_title("ACF")
# PACF
plot_pacf(series[fila].dropna(), lags=24, ax=axes[fila, 2], zero=False, color='navy')
axes[fila, 2].set_title("PACF")
# Indicador estacionariedad
axes[fila, 0].text(
0.02, 0.90,
f"ADF: {resultados_adf[fila][0]:.2f}\np-valor: {resultados_adf[fila][1]:.4f}\n{interpretaciones[fila]}",
transform=axes[fila, 0].transAxes,
fontsize=11, bbox=dict(facecolor='white', alpha=0.85)
)
plt.tight_layout()
plt.show()
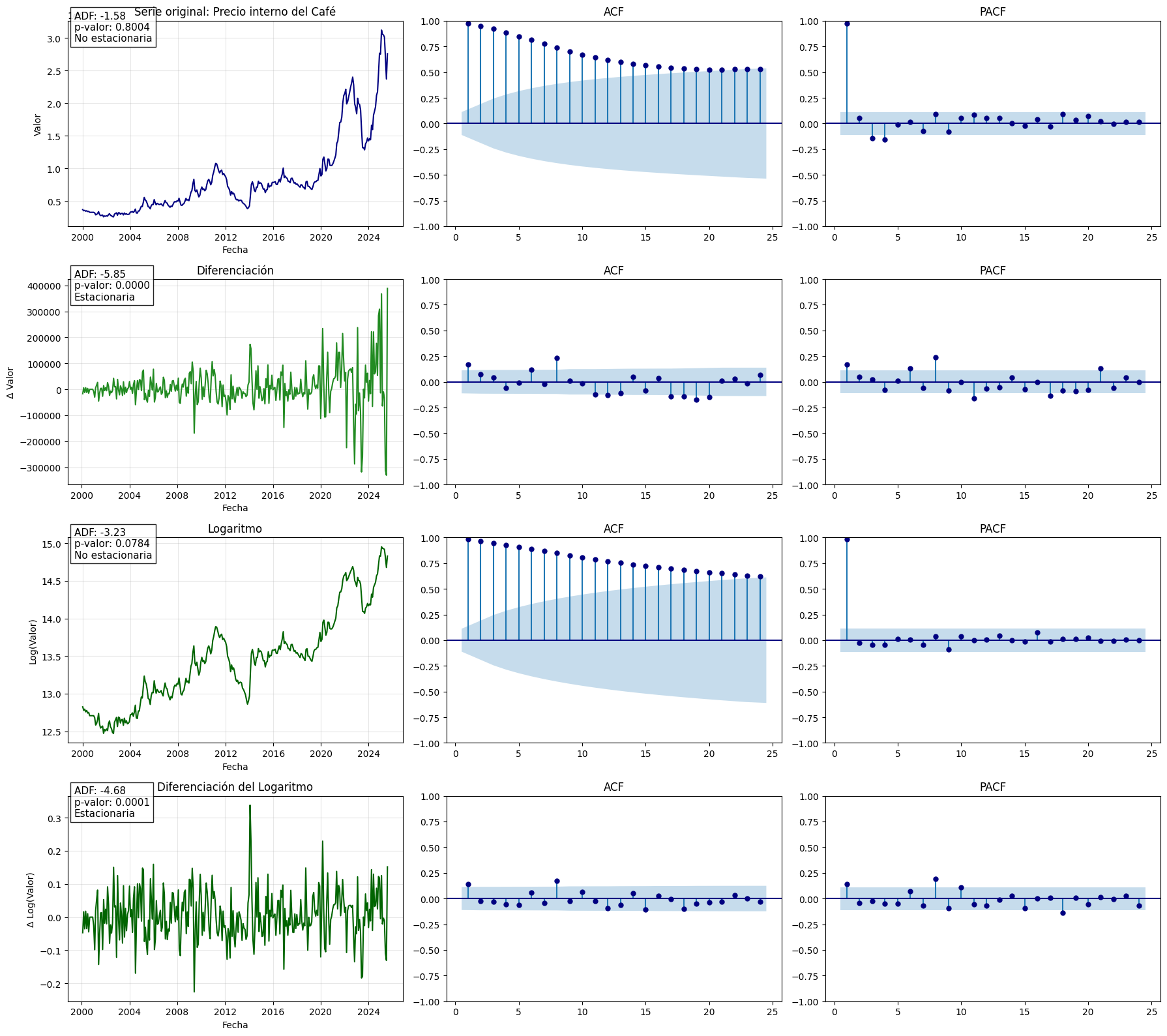
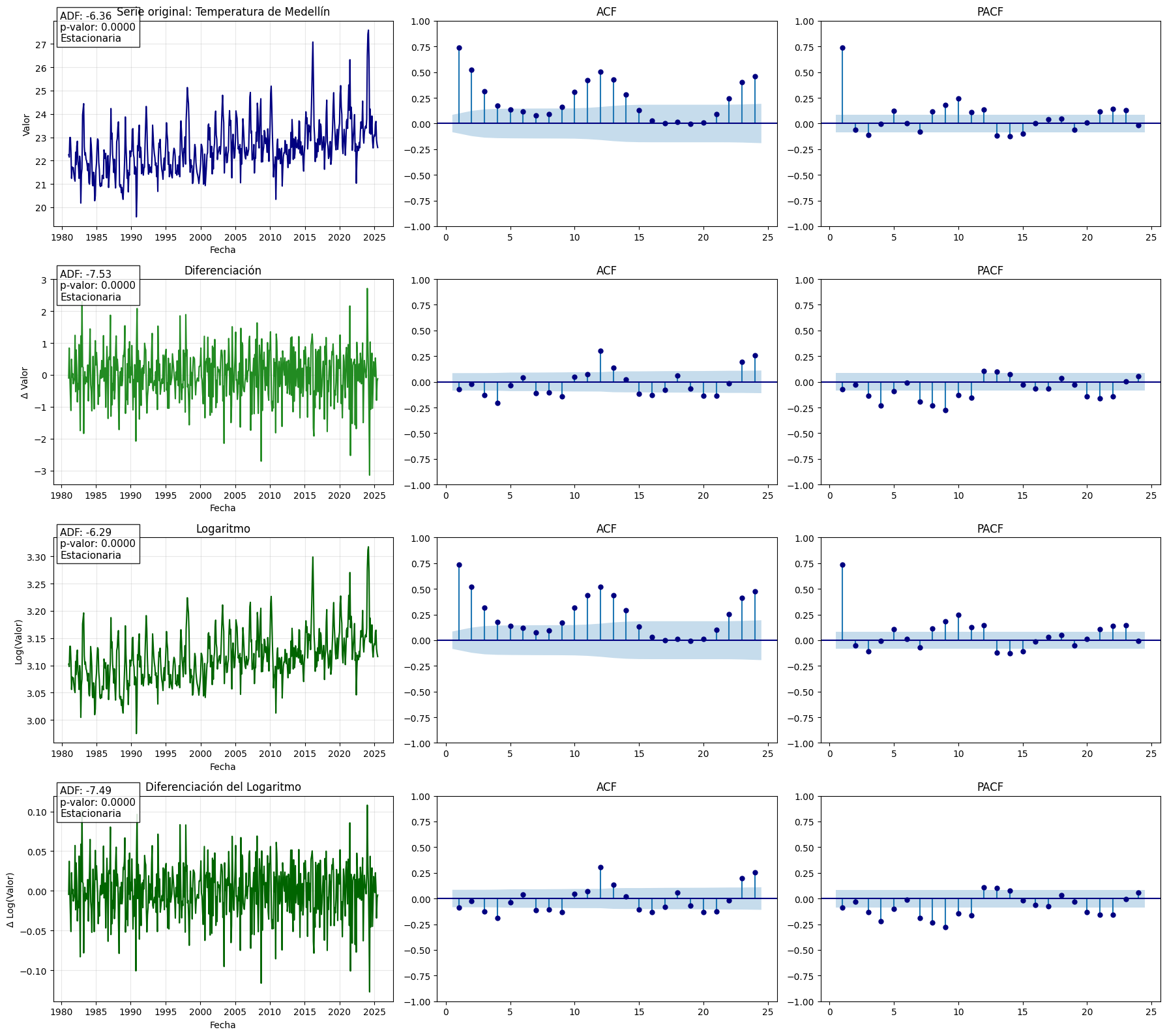
Temperatura de Medellín:#
# Cargar el archivo xlsx:
serie_temperatura = pd.read_excel('Temperatura Medellín.xlsx')
# Corregir nombres de columnas si tienen espacios
serie_temperatura.columns = serie_temperatura.columns.str.strip()
# Convertir 'Fecha' a datetime y usar como índice
serie_temperatura['Fecha'] = pd.to_datetime(serie_temperatura['Fecha'])
serie_temperatura.set_index('Fecha', inplace=True)
# Ordenar por fecha por si acaso
serie_temperatura = serie_temperatura.sort_index()
# Establecer frecuencia explícita para evitar el warning de statsmodels
serie_temperatura.index.freq = serie_temperatura.index.inferred_freq
plt.figure(figsize=(18, 5))
plt.plot(serie_temperatura, color='navy')
plt.title("Serie de tiempo: Temperatura de Medellín")
plt.xlabel("Fecha")
plt.ylabel("$")
plt.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
serie_temperatura.head()
| Temperatura | |
|---|---|
| Fecha | |
| 1981-01-01 | 22.25 |
| 1981-02-01 | 22.15 |
| 1981-03-01 | 22.99 |
| 1981-04-01 | 22.99 |
| 1981-05-01 | 22.36 |
serie = "Temperatura de Medellín"
# Serie original y transformaciones:
serie_1 = serie_temperatura.copy()
serie_2 = serie_1.diff().dropna()
serie_3 = np.log(serie_1)
serie_4 = serie_3.diff().dropna()
titulos = [f"Serie original: {serie}",
"Diferenciación",
"Logaritmo",
"Diferenciación del Logaritmo"]
series = [serie_1, serie_2, serie_3, serie_4]
# ADF test y etiquetas de estacionariedad
resultados_adf = []
interpretaciones = []
for i, serie in enumerate(series):
serie_ = serie.dropna()
# Seleccionar el tipo de regresión adecuado:
if i in [0, 2]: # serie_1 y serie_3
adf = adfuller(serie_, regression='ct') # constante y tendencia
else: # serie_2 y serie_4
adf = adfuller(serie_, regression='c') # solo constante
estadistico = adf[0]
pvalue = adf[1]
resultados_adf.append((estadistico, pvalue))
if pvalue < 0.05:
interpretaciones.append("Estacionaria")
else:
interpretaciones.append("No estacionaria")
# Gráfico 4 filas × 3 columnas
fig, axes = plt.subplots(4, 3, figsize=(18, 16))
for fila in range(4):
# Serie
color = 'navy' if fila == 0 else 'forestgreen' if fila == 1 else 'darkgreen'
axes[fila, 0].plot(series[fila], color=color)
axes[fila, 0].set_title(titulos[fila])
axes[fila, 0].set_xlabel("Fecha")
if fila == 0:
axes[fila, 0].set_ylabel("Valor")
elif fila == 1:
axes[fila, 0].set_ylabel("Δ Valor")
elif fila == 2:
axes[fila, 0].set_ylabel("Log(Valor)")
else:
axes[fila, 0].set_ylabel("Δ Log(Valor)")
axes[fila, 0].grid(True, alpha=0.3)
# ACF
plot_acf(series[fila].dropna(), lags=24, ax=axes[fila, 1], zero=False, color='navy')
axes[fila, 1].set_title("ACF")
# PACF
plot_pacf(series[fila].dropna(), lags=24, ax=axes[fila, 2], zero=False, color='navy')
axes[fila, 2].set_title("PACF")
# Indicador estacionariedad
axes[fila, 0].text(
0.02, 0.90,
f"ADF: {resultados_adf[fila][0]:.2f}\np-valor: {resultados_adf[fila][1]:.4f}\n{interpretaciones[fila]}",
transform=axes[fila, 0].transAxes,
fontsize=11, bbox=dict(facecolor='white', alpha=0.85)
)
plt.tight_layout()
plt.show()
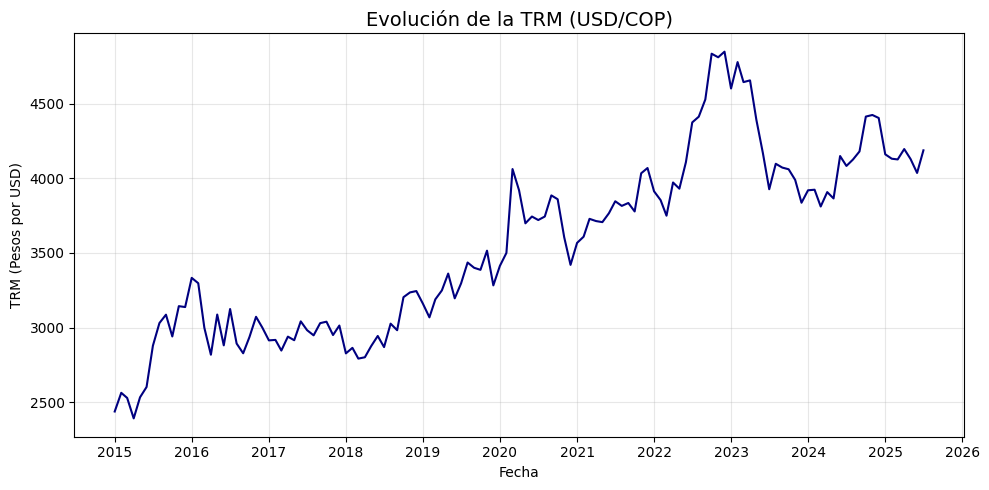
TRM:#
import yfinance as yf
# Descargar datos mensuales desde 2015
start_date = "2015-01-01"
end_date = "2025-07-31"
# TRM de Colombia (USD/COP)
trm = yf.download("USDCOP=X", start=start_date, end=end_date, interval='1mo', auto_adjust=False)['Close']
trm.name = 'TRM (USD/COP)'
# Crear figura
plt.figure(figsize=(10, 5))
plt.plot(trm.index, trm, linestyle='-', color='navy')
# Personalización del gráfico
plt.title("Evolución de la TRM (USD/COP)", fontsize=14)
plt.xlabel("Fecha")
plt.ylabel("TRM (Pesos por USD)")
plt.grid(True, alpha=0.3)
# Formato de fechas en el eje X
plt.gca().xaxis.set_major_locator(mdates.YearLocator())
plt.gca().xaxis.set_major_formatter(mdates.DateFormatter('%Y'))
plt.tight_layout()
plt.show()
[*******************100%*********************] 1 of 1 completed
serie = "TRM"
# Serie original y transformaciones:
serie_1 = trm.copy()
serie_2 = serie_1.diff().dropna()
serie_3 = np.log(serie_1)
serie_4 = serie_3.diff().dropna()
titulos = [f"Serie original: {serie}",
"Diferenciación",
"Logaritmo",
"Diferenciación del Logaritmo"]
series = [serie_1, serie_2, serie_3, serie_4]
# ADF test y etiquetas de estacionariedad
resultados_adf = []
interpretaciones = []
for i, serie in enumerate(series):
serie_ = serie.dropna()
# Seleccionar el tipo de regresión adecuado:
if i in [0, 2]: # serie_1 y serie_3
adf = adfuller(serie_, regression='ct') # constante y tendencia
else: # serie_2 y serie_4
adf = adfuller(serie_, regression='c') # solo constante
estadistico = adf[0]
pvalue = adf[1]
resultados_adf.append((estadistico, pvalue))
if pvalue < 0.05:
interpretaciones.append("Estacionaria")
else:
interpretaciones.append("No estacionaria")
# Gráfico 4 filas × 3 columnas
fig, axes = plt.subplots(4, 3, figsize=(18, 16))
for fila in range(4):
# Serie
color = 'navy' if fila == 0 else 'forestgreen' if fila == 1 else 'darkgreen'
axes[fila, 0].plot(series[fila], color=color)
axes[fila, 0].set_title(titulos[fila])
axes[fila, 0].set_xlabel("Fecha")
if fila == 0:
axes[fila, 0].set_ylabel("Valor")
elif fila == 1:
axes[fila, 0].set_ylabel("Δ Valor")
elif fila == 2:
axes[fila, 0].set_ylabel("Log(Valor)")
else:
axes[fila, 0].set_ylabel("Δ Log(Valor)")
axes[fila, 0].grid(True, alpha=0.3)
# ACF
plot_acf(series[fila].dropna(), lags=24, ax=axes[fila, 1], zero=False, color='navy')
axes[fila, 1].set_title("ACF")
# PACF
plot_pacf(series[fila].dropna(), lags=24, ax=axes[fila, 2], zero=False, color='navy')
axes[fila, 2].set_title("PACF")
# Indicador estacionariedad
axes[fila, 0].text(
0.02, 0.90,
f"ADF: {resultados_adf[fila][0]:.2f}\np-valor: {resultados_adf[fila][1]:.4f}\n{interpretaciones[fila]}",
transform=axes[fila, 0].transAxes,
fontsize=11, bbox=dict(facecolor='white', alpha=0.85)
)
plt.tight_layout()
plt.show()

Precio de electricidad:#
# Cargar el archivo
precio_electricidad = pd.read_csv("Precio_electricidad.csv")
# Corregir nombres de columnas si tienen espacios
precio_electricidad.columns = precio_electricidad.columns.str.strip()
# Convertir 'Fecha' a datetime y usar como índice
precio_electricidad['Fecha'] = pd.to_datetime(precio_electricidad['Fecha'])
precio_electricidad.set_index('Fecha', inplace=True)
# Ordenar por fecha por si acaso
precio_electricidad = precio_electricidad.sort_index()
plt.figure(figsize=(12, 5))
plt.plot(precio_electricidad.index, precio_electricidad['Precio'], color='navy')
plt.title("Serie de tiempo: Precio de electricidad")
plt.xlabel("Fecha")
plt.ylabel("Precio")
plt.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()

serie = "Precio de electricidad"
# Serie original y transformaciones:
serie_1 = precio_electricidad.copy()
serie_2 = serie_1.diff().dropna()
serie_3 = np.log(serie_1)
serie_4 = serie_3.diff().dropna()
titulos = [f"Serie original: {serie}",
"Diferenciación",
"Logaritmo",
"Diferenciación del Logaritmo"]
series = [serie_1, serie_2, serie_3, serie_4]
# ADF test y etiquetas de estacionariedad
resultados_adf = []
interpretaciones = []
for i, serie in enumerate(series):
serie_ = serie.dropna()
# Seleccionar el tipo de regresión adecuado:
if i in [0, 2]: # serie_1 y serie_3
adf = adfuller(serie_, regression='ct') # constante y tendencia
else: # serie_2 y serie_4
adf = adfuller(serie_, regression='c') # solo constante
estadistico = adf[0]
pvalue = adf[1]
resultados_adf.append((estadistico, pvalue))
if pvalue < 0.05:
interpretaciones.append("Estacionaria")
else:
interpretaciones.append("No estacionaria")
# Gráfico 4 filas × 3 columnas
fig, axes = plt.subplots(4, 3, figsize=(18, 16))
for fila in range(4):
# Serie
color = 'navy' if fila == 0 else 'forestgreen' if fila == 1 else 'darkgreen'
axes[fila, 0].plot(series[fila], color=color)
axes[fila, 0].set_title(titulos[fila])
axes[fila, 0].set_xlabel("Fecha")
if fila == 0:
axes[fila, 0].set_ylabel("Valor")
elif fila == 1:
axes[fila, 0].set_ylabel("Δ Valor")
elif fila == 2:
axes[fila, 0].set_ylabel("Log(Valor)")
else:
axes[fila, 0].set_ylabel("Δ Log(Valor)")
axes[fila, 0].grid(True, alpha=0.3)
# ACF
plot_acf(series[fila].dropna(), lags=24, ax=axes[fila, 1], zero=False, color='navy')
axes[fila, 1].set_title("ACF")
# PACF
plot_pacf(series[fila].dropna(), lags=24, ax=axes[fila, 2], zero=False, color='navy')
axes[fila, 2].set_title("PACF")
# Indicador estacionariedad
axes[fila, 0].text(
0.02, 0.90,
f"ADF: {resultados_adf[fila][0]:.2f}\np-valor: {resultados_adf[fila][1]:.4f}\n{interpretaciones[fila]}",
transform=axes[fila, 0].transAxes,
fontsize=11, bbox=dict(facecolor='white', alpha=0.85)
)
plt.tight_layout()
plt.show()