Stacking#
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
from sklearn.ensemble import StackingClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import classification_report, confusion_matrix
import yfinance as yf
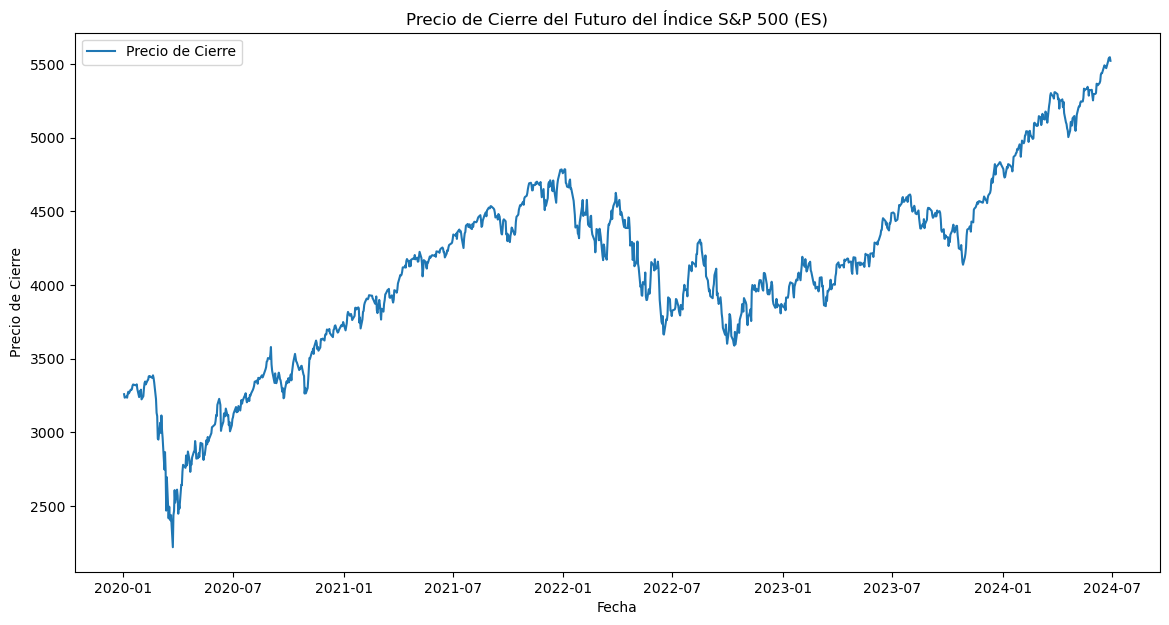
Descargar precios del Futuro ES:#
# Descargar datos históricos del futuro del índice S&P 500 (ES)
ticker = "ES=F"
data = yf.download(ticker, start="2020-01-01", end="2024-06-30", interval="1d")
# Graficar el precio de cierre
plt.figure(figsize=(14, 7))
plt.plot(data["Close"], label="Precio de Cierre")
plt.title("Precio de Cierre del Futuro del Índice S&P 500 (ES)")
plt.xlabel("Fecha")
plt.ylabel("Precio de Cierre")
plt.legend()
plt.show()
[*******************100%*********************] 1 of 1 completed
Creación de las características:#
# Crear características adicionales
data["PriceChange"] = data["Close"].shift(-1) - data["Close"]
data["Label"] = np.where(data["PriceChange"] > 0, 1, 0)
data["DailyPctChange"] = ((data["Close"] - data["Open"]) / data["Open"]) * 100
data["Range"] = data["High"] - data["Low"]
data["Volatility"] = (data["High"] - data["Low"]) / data["Close"]
# Seleccionar características y etiqueta
features = [
"Open",
"High",
"Low",
"Close",
"Volume",
"Volatility",
"DailyPctChange",
"Range",
]
X = data[features]
y = data["Label"]
print("Cantidad precios positivos y negativos:\n", data["Label"].value_counts())
print(X.head())
Cantidad precios positivos y negativos:
1 602
0 529
Name: Label, dtype: int64
Open High Low Close Volume Volatility Date
2020-01-02 3237.00 3261.75 3234.25 3259.00 1416241 0.008438
2020-01-03 3261.00 3263.50 3206.75 3235.50 1755057 0.017540
2020-01-06 3220.25 3249.50 3208.75 3243.50 1502748 0.012564
2020-01-07 3243.50 3254.50 3226.00 3235.25 1293494 0.008809
2020-01-08 3231.75 3267.75 3181.00 3260.25 2279138 0.026608
DailyPctChange Range
Date
2020-01-02 0.679642 27.50
2020-01-03 -0.781969 56.75
2020-01-06 0.721994 40.75
2020-01-07 -0.254355 28.50
2020-01-08 0.881875 86.75
Stacking:#
Stacking (también conocido como stacked generalization) es una técnica de ensemble learning que combina las predicciones de múltiples modelos base (llamados level-0 models o base learners) mediante un modelo de nivel superior (conocido como meta learner o blender). La idea principal detrás de stacking es que el modelo meta aprende a corregir las debilidades y errores de los modelos base, aprovechando las fortalezas de cada uno para mejorar la precisión global del ensemble.
Definición de Modelos Base:
Definimos varios modelos base (level-0 models) que serán entrenados en el conjunto de datos de entrenamiento. En este ejemplo, utilizamos un SVC con un kernel gaussiano, un Random Forest y un Árbol de Decisión.
Definición del Modelo Meta:
El modelo meta o blender es un regresor logístico
(LogisticRegression) que tomará las predicciones de los modelos base
como características de entrada para hacer la predicción final.
El modelo meta aprende a corregir los errores de los modelos base y a combinar sus fortalezas.
# Dividir el conjunto de datos en entrenamiento y prueba
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.3, random_state=34
)
# Definir los modelos base
base_learners = [
("svc", SVC(probability=True, kernel="rbf", random_state=34)),
("rf", RandomForestClassifier(n_estimators=100, random_state=34)),
("dt", DecisionTreeClassifier(random_state=34)),
]
# Definir el modelo meta
meta_learner = LogisticRegression()
# Crear el clasificador de Stacking
stacking_clf = StackingClassifier(
estimators=base_learners, final_estimator=meta_learner, cv=5
)
# Entrenar el clasificador de Stacking
stacking_clf.fit(X_train, y_train)
# Realizar predicciones
y_pred = stacking_clf.predict(X_test)
Evaluación del modelo:#
# Calcular las métricas de evaluación
conf_matrix = confusion_matrix(y_test, y_pred)
class_report = classification_report(y_test, y_pred)
# Mostrar las métricas de evaluación
print("Classification Report:\n", class_report)
# Crear un mapa de calor para la matriz de confusión con etiquetas
plt.figure(figsize=(8, 6))
sns.heatmap(
conf_matrix,
annot=True,
fmt="d",
cmap="Blues",
xticklabels=["Predicho 0", "Predicho 1"],
yticklabels=["Real 0", "Real 1"],
)
plt.xlabel("Etiqueta Predicha")
plt.ylabel("Etiqueta Real")
plt.title("Matriz de Confusión")
plt.show()
Classification Report:
precision recall f1-score support
0 0.50 0.25 0.33 154
1 0.56 0.80 0.66 186
accuracy 0.55 340
macro avg 0.53 0.52 0.49 340
weighted avg 0.53 0.55 0.51 340