SVM riesgo de crédito#
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.svm import SVC
from sklearn.metrics import classification_report, confusion_matrix, accuracy_score
# Cargar el archivo CSV (ya lo hemos cargado y limpiado previamente)
credit_risk_data = pd.read_csv("../credit_risk_data.csv")
credit_risk_data = credit_risk_data.drop(columns=["ID"])
# Dividir los datos en características (X) y etiqueta (y)
X = credit_risk_data.drop(columns=["Estado del Préstamo"])
y = credit_risk_data["Estado del Préstamo"]
# 1. Dividir el conjunto de datos en entrenamiento y prueba
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=34
)
# 2. Estandarizar los datos
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
print(
"Cantidad de precios positivos y negativos en el conjunto de entrenamiento:\n",
y_train.value_counts(),
)
print(
"Cantidad de precios positivos y negativos en el conjunto de test:\n",
y_test.value_counts(),
)
Cantidad de precios positivos y negativos en el conjunto de entrenamiento:
1 633
0 167
Name: Estado del Préstamo, dtype: int64
Cantidad de precios positivos y negativos en el conjunto de test:
1 145
0 55
Name: Estado del Préstamo, dtype: int64
Para obtener las probabilidades se debe indicar antes del ajuste del modelo.
probability=True
# 3. Crear un modelo de SVM
svm = SVC(kernel="rbf", probability=True, random_state=34)
# 4. Entrenar el modelo
svm.fit(X_train, y_train)
# 5. Hacer predicciones.
y_pred = svm.predict(X_test)
y_pred_prob = svm.predict_proba(X_test)[:, 1]
# Resultados de la clasificación
print("Valores reales en el conjunto de prueba:\n", y_test[:15].values)
print("Predicciones en el conjunto de prueba:\n", y_pred[:15])
print("Probabilidades de predicción en el conjunto de prueba:\n", y_pred_prob[:15])
Valores reales en el conjunto de prueba:
[1 1 1 1 1 1 1 1 1 1 1 1 0 0 0]
Predicciones en el conjunto de prueba:
[1 1 1 1 1 1 1 1 1 1 1 1 0 0 0]
Probabilidades de predicción en el conjunto de prueba:
[9.99988856e-01 9.52632723e-01 9.99999781e-01 9.23438769e-01
9.99999996e-01 9.89170651e-01 9.73024036e-01 7.63229498e-01
8.78832466e-01 9.99992469e-01 9.35181847e-01 9.99999989e-01
9.31468416e-02 4.74194478e-02 8.58150654e-04]
# 6. Calcular las métricas de evaluación
accuracy = accuracy_score(y_test, y_pred)
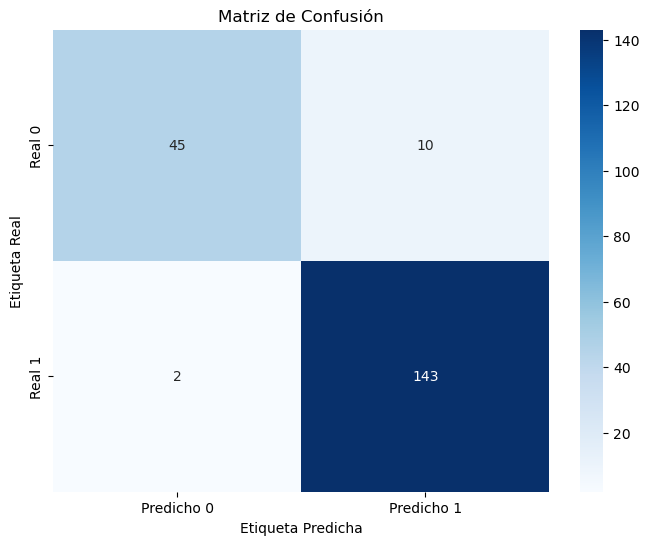
conf_matrix = confusion_matrix(y_test, y_pred)
class_report = classification_report(y_test, y_pred)
# Mostrar las métricas de evaluación
print("Accuracy:", accuracy)
print("Classification Report:\n", class_report)
# Crear un mapa de calor para la matriz de confusión con etiquetas
plt.figure(figsize=(8, 6))
sns.heatmap(
conf_matrix,
annot=True,
fmt="d",
cmap="Blues",
xticklabels=["Predicho 0", "Predicho 1"],
yticklabels=["Real 0", "Real 1"],
)
plt.xlabel("Etiqueta Predicha")
plt.ylabel("Etiqueta Real")
plt.title("Matriz de Confusión")
plt.show()
Accuracy: 0.94
Classification Report:
precision recall f1-score support
0 0.96 0.82 0.88 55
1 0.93 0.99 0.96 145
accuracy 0.94 200
macro avg 0.95 0.90 0.92 200
weighted avg 0.94 0.94 0.94 200