Ejemplo métodos de clasificación sobre Estados Financieros#
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import BaggingClassifier, RandomForestClassifier, AdaBoostClassifier, GradientBoostingClassifier, StackingClassifier
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import accuracy_score
import xgboost as xgb
# Cargar los archivos de Excel
file_1 = "../310030_Estado de resultado integral, resultado del periodo, por funcion de gasto_PYMES.xlsx"
file_2 = "../210030_Estado de situación financiera, corriente_no corriente_PYMES.xlsx"
# Leer todas las hojas de los archivos
sheets_file_1 = pd.read_excel(file_1, sheet_name=None)
sheets_file_2 = pd.read_excel(file_2, sheet_name=None)
# Función para separar las empresas según 'EN REORGANIZACION'
def separate_companies(sheets):
reorganizacion = [] # Lista para almacenar las empresas en reorganización
not_reorganizacion = (
[]
) # Lista para almacenar las empresas que no están en reorganización
for sheet_name, df in sheets.items():
# Filtrar por 'Periodo Actual'
df_periodo_actual = df[df["Periodo"] == "Periodo Actual"]
# Filtrar las empresas que terminan con 'EN REORGANIZACION'
reorganizacion.append(
df_periodo_actual[
df_periodo_actual["Razón social de la sociedad"].str.endswith(
"EN REORGANIZACION", na=False
)
]
)
# Filtrar las empresas que no terminan con 'EN REORGANIZACION'
not_reorganizacion.append(
df_periodo_actual[
~df_periodo_actual["Razón social de la sociedad"].str.endswith(
"EN REORGANIZACION", na=False
)
]
)
# Concatenar los resultados de todas las hojas
return pd.concat(reorganizacion), pd.concat(not_reorganizacion)
# Separar las empresas en ambos archivos
reorganizacion_1, not_reorganizacion_1 = separate_companies(sheets_file_1)
reorganizacion_2, not_reorganizacion_2 = separate_companies(sheets_file_2)
# Combinar los resultados de ambos archivos
reorganizacion = pd.concat([reorganizacion_1, reorganizacion_2])
not_reorganizacion = pd.concat([not_reorganizacion_1, not_reorganizacion_2])
# Filtrar las empresas donde 'Ingresos de actividades ordinarias (Revenue)' fueron positivos
reorganizacion = reorganizacion[
reorganizacion["Ingresos de actividades ordinarias (Revenue)"] > 0
]
not_reorganizacion = not_reorganizacion[
not_reorganizacion["Ingresos de actividades ordinarias (Revenue)"] > 0
]
print("Empresas en reorganización: ", len(reorganizacion))
print("Empresas que no están en reorganización: ", len(not_reorganizacion))
Empresas en reorganización: 424
Empresas que no están en reorganización: 21969
from sklearn.utils import resample
# Submuestrear las empresas que no están en reorganización utilizando resample de sklearn
subsample_not_reorganizacion = resample(
not_reorganizacion,
replace=False, # muestreo sin reemplazo
n_samples=len(reorganizacion), # mismo tamaño que las empresas en reorganización
random_state=34,
) # para reproducibilidad
# Crear una nueva columna 'label' para identificar las empresas en reorganización (1) y las que no están en reorganización (0)
reorganizacion["label"] = 1
subsample_not_reorganizacion["label"] = 0
# Combinar las empresas en reorganización y la submuestra de las que no están en reorganización
combined = pd.concat([reorganizacion, subsample_not_reorganizacion])
# Contar cuántas hay de cada tipo
combined["label"].value_counts()
1 424
0 424
Name: label, dtype: int64
# Combinar las empresas en reorganización y la submuestra de las que no están en reorganización
combined = pd.concat([reorganizacion, subsample_not_reorganizacion])
# Crear el DataFrame 'df' combinando las columnas necesarias de filtered_BG y filtered_ER
df = pd.DataFrame()
# Calcular los indicadores financieros y agregarlos al DataFrame 'df'
df["Margen Bruto"] = (
combined["Ganancia bruta (GrossProfit)"]
/ combined["Ingresos de actividades ordinarias (Revenue)"]
)
df["Margen Operacional"] = (
combined[
"Ganancia (pérdida) por actividades de operación (GananciaPerdidaPorActividadesDeOperacion)"
]
/ combined["Ingresos de actividades ordinarias (Revenue)"]
)
df["Margen Neto"] = (
combined["Ganancia (pérdida) (ProfitLoss)"]
/ combined["Ingresos de actividades ordinarias (Revenue)"]
)
df["label"] = combined["label"]
# Eliminar filas con valores nulos o infinitos
df.replace([np.inf, -np.inf], np.nan, inplace=True)
df.dropna(inplace=True)
# Mostrar los primeros resultados del DataFrame 'df' para verificación
print(df.head())
# Contar cuántas hay de cada tipo
df["label"].value_counts()
Margen Bruto Margen Operacional Margen Neto label
120 0.182169 -0.139234 -0.110590 1
206 0.145285 0.021016 -0.074642 1
302 1.000000 1.595930 1.077714 1
306 0.568611 0.077610 0.059090 1
432 0.149503 0.026351 0.026905 1
1 424
0 424
Name: label, dtype: int64
Análisis de los datos:#
indicadores = df.columns[:-1]
# Calcular estadísticas descriptivas por etiqueta
descriptive_stats = df.groupby("label")[indicadores].describe()
# Mostrar las estadísticas descriptivas
print(descriptive_stats)
Margen Bruto count mean std min 25% 50%
label
0 424.0 0.470579 0.440547 -3.989035 0.187012 0.358174
1 424.0 0.353629 0.423258 -3.786625 0.179082 0.314670
Margen Operacional ... 75% max count mean ... 75% max
label ...
0 0.949685 1.0 424.0 -0.404545 ... 0.179070 16.825625
1 0.505105 1.0 424.0 -0.120398 ... 0.091547 29.476177
Margen Neto count mean std min 25% 50%
label
0 424.0 -0.484004 10.374411 -212.235702 0.002675 0.036420
1 424.0 -0.206236 3.322487 -23.506586 -0.087183 0.010214
75% max
label
0 0.105156 11.793688
1 0.049940 43.647336
[2 rows x 24 columns]
# Crear diagramas de violín para cada variable por etiqueta
plt.figure(figsize=(15, 10))
for i, variable in enumerate(indicadores, 1):
plt.subplot(2, 2, i)
sns.violinplot(x="label", y=variable, data=df, palette="Set1")
plt.title(f"Diagrama de Violín de {variable}")
plt.xlabel("Label (1: En Reorganización, 0: No en Reorganización)")
plt.ylabel(variable)
plt.tight_layout()
plt.show()
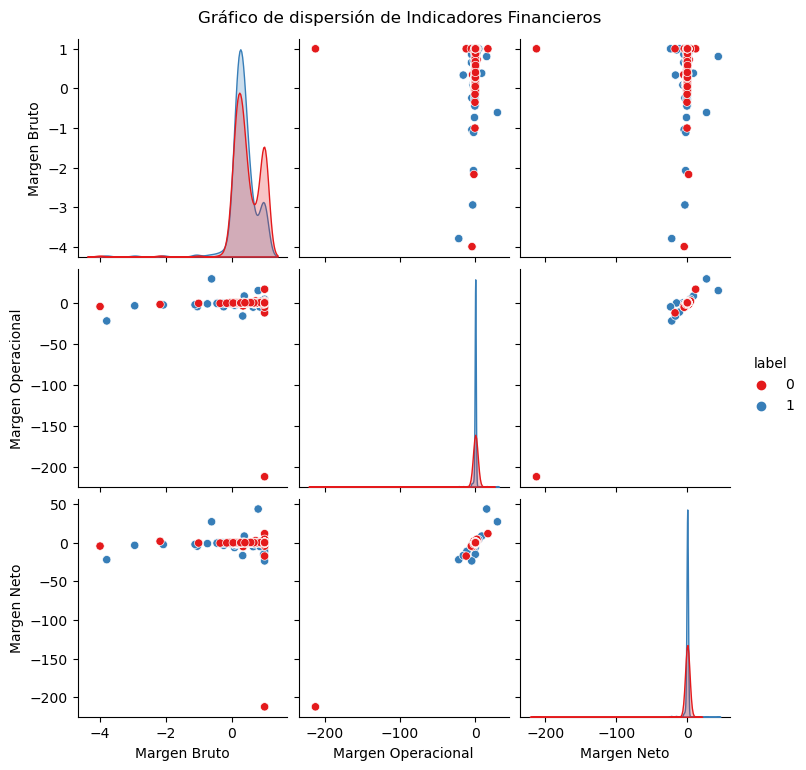
# Gráfico de dispersión para algunas combinaciones de indicadores financieros
plt.figure(figsize=(15, 10))
sns.pairplot(df, hue="label", vars=indicadores, palette="Set1")
plt.suptitle("Gráfico de dispersión de Indicadores Financieros", y=1.02)
plt.show()
<Figure size 1500x1000 with 0 Axes>
Ajuste de los modelos de clasificación:#
# Seleccionar las características (indicadores financieros) y la etiqueta
X = df[indicadores]
y = df["label"]
# Dividir el conjunto de datos en entrenamiento y prueba
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.3, random_state=34
)
# Estandarizar los datos
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
# Crear y entrenar modelos
# Regresión Logística (escala necesaria)
log_clf = LogisticRegression(max_iter=1000)
log_clf.fit(X_train, y_train)
log_pred = log_clf.predict(X_test)
log_accuracy = accuracy_score(y_test, log_pred)
# SVM (escala necesaria)
svm_clf = SVC(probability=True)
svm_clf.fit(X_train, y_train)
svm_pred = svm_clf.predict(X_test)
svm_accuracy = accuracy_score(y_test, svm_pred)
# Árbol de Decisión (no es necesario escalar)
tree_clf = DecisionTreeClassifier()
tree_clf.fit(X_train, y_train)
tree_pred = tree_clf.predict(X_test)
tree_accuracy = accuracy_score(y_test, tree_pred)
# Bagging con Árbol de Decisión (no es necesario escalar)
bagging_clf = BaggingClassifier(
base_estimator=DecisionTreeClassifier(),
n_estimators=100,
max_samples=0.8,
bootstrap=True,
n_jobs=-1,
random_state=34
)
bagging_clf.fit(X_train, y_train)
bagging_pred = bagging_clf.predict(X_test)
bagging_accuracy = accuracy_score(y_test, bagging_pred)
# Random Forest (no es necesario escalar)
rf_clf = RandomForestClassifier(
n_estimators=100,
max_depth=3,
max_features='sqrt',
random_state=34,
n_jobs=-1
)
rf_clf.fit(X_train, y_train)
rf_pred = rf_clf.predict(X_test)
rf_accuracy = accuracy_score(y_test, rf_pred)
# AdaBoost (no es necesario escalar)
adaboost_clf = AdaBoostClassifier(
base_estimator=DecisionTreeClassifier(max_depth=1),
n_estimators=100,
learning_rate=0.1,
random_state=34
)
adaboost_clf.fit(X_train, y_train)
adaboost_pred = adaboost_clf.predict(X_test)
adaboost_accuracy = accuracy_score(y_test, adaboost_pred)
# Gradient Boosting (no es necesario escalar)
gb_clf = GradientBoostingClassifier(
n_estimators=100,
max_depth=3,
learning_rate=0.1,
random_state=34
)
gb_clf.fit(X_train, y_train)
gb_pred = gb_clf.predict(X_test)
gb_accuracy = accuracy_score(y_test, gb_pred)
# XGBoost (no es necesario escalar)
xgb_clf = xgb.XGBClassifier(
n_estimators=100,
max_depth=3,
learning_rate=0.1,
subsample=0.8,
colsample_bytree=0.8,
random_state=34
)
xgb_clf.fit(X_train, y_train)
xgb_pred = xgb_clf.predict(X_test)
xgb_accuracy = accuracy_score(y_test, xgb_pred)
# Stacking (los modelos base que lo requieren usan los datos escalados)
stacking_clf = StackingClassifier(
estimators=[
('svc', SVC(probability=True)),
('rf', RandomForestClassifier(n_estimators=100, random_state=34)),
('dt', DecisionTreeClassifier(random_state=34)),
('log_reg', LogisticRegression(max_iter=1000))
],
final_estimator=LogisticRegression(),
cv=5
)
stacking_clf.fit(X_train, y_train)
stacking_pred = stacking_clf.predict(X_test)
stacking_accuracy = accuracy_score(y_test, stacking_pred)
# Comparar las precisiones
model_names = [
"Logistic Regression",
"SVM",
"Decision Tree",
"Bagging",
"Random Forest",
"AdaBoost",
"Gradient Boosting",
"XGBoost",
"Stacking"
]
accuracies = [
log_accuracy,
svm_accuracy,
tree_accuracy,
bagging_accuracy,
rf_accuracy,
adaboost_accuracy,
gb_accuracy,
xgb_accuracy,
stacking_accuracy
]
# Mostrar las precisiones
for model, accuracy in zip(model_names, accuracies):
print(f"{model}: {accuracy:.2f}")
Logistic Regression: 0.53
SVM: 0.55
Decision Tree: 0.52
Bagging: 0.56
Random Forest: 0.58
AdaBoost: 0.57
Gradient Boosting: 0.57
XGBoost: 0.61
Stacking: 0.54