Ejercicio Clustering acciones#
import yfinance as yf
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from scipy.cluster.hierarchy import dendrogram, linkage, fcluster, cophenet
from sklearn.cluster import AgglomerativeClustering
from scipy.spatial.distance import pdist
import seaborn as sns
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import silhouette_score
from sklearn.cluster import KMeans
from sklearn.cluster import DBSCAN
# Lista de tickers de Yahoo Finance
tickers = [
"AAPL",
"MSFT",
"GOOGL",
"META",
"AMZN",
"TSLA",
"NVDA",
"AMD",
"NFLX",
"WMT",
"COST",
"KO",
"PEP",
"JPM",
"V",
"BAC",
"XOM",
"CVX",
]
# Descargar datos históricos para cada ticker
data = {}
for ticker in tickers:
data[ticker] = yf.download(ticker, start="2023-06-30", end="2024-07-01")
# Crear un DataFrame que contenga los precios de cierre de todas las acciones
closing_prices = pd.DataFrame({ticker: data[ticker]["Close"] for ticker in tickers})
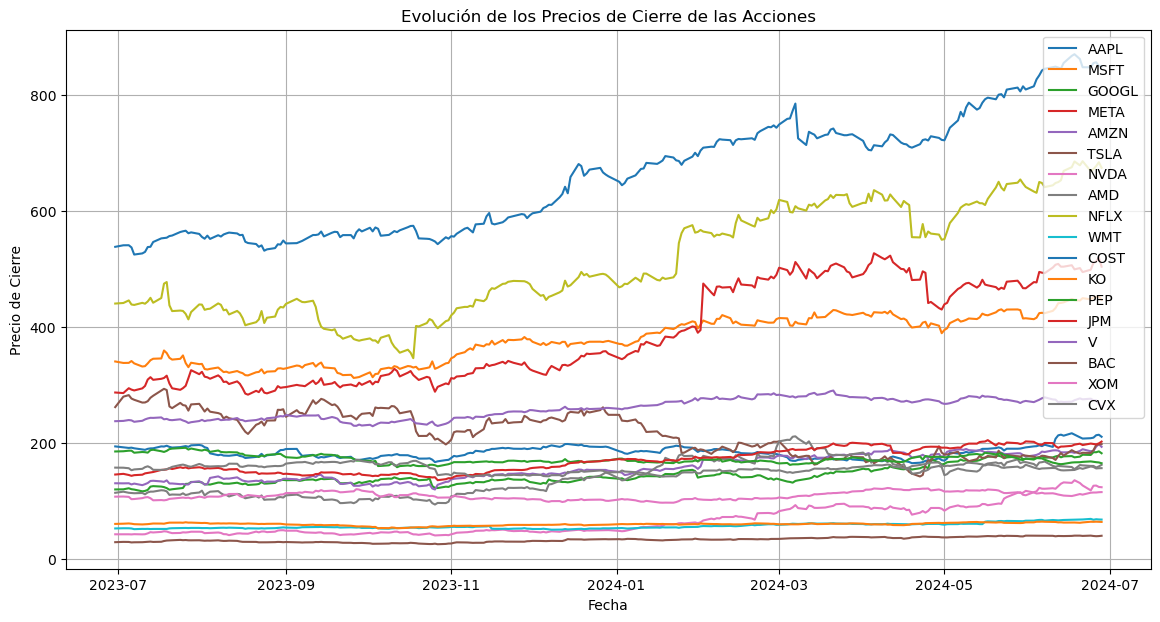
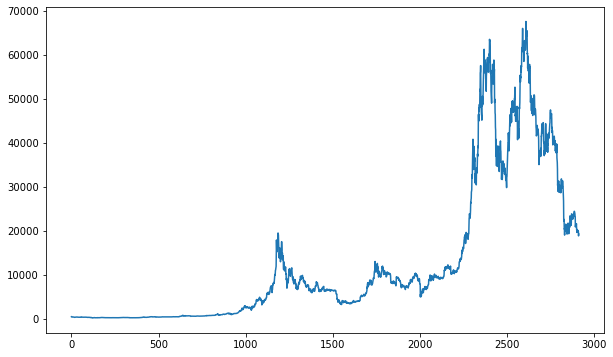
# Graficar los precios de cierre
plt.figure(figsize=(14, 7))
for ticker in tickers:
plt.plot(closing_prices.index, closing_prices[ticker], label=ticker)
plt.xlabel("Fecha")
plt.ylabel("Precio de Cierre")
plt.title("Evolución de los Precios de Cierre de las Acciones")
plt.legend()
plt.grid(True)
plt.show()
[*******************100%*********************] 1 of 1 completed [*******************100%*********************] 1 of 1 completed [*******************100%*********************] 1 of 1 completed [*******************100%*********************] 1 of 1 completed [*******************100%*********************] 1 of 1 completed [*******************100%*********************] 1 of 1 completed [*******************100%*********************] 1 of 1 completed [*******************100%*********************] 1 of 1 completed [*******************100%*********************] 1 of 1 completed [*******************100%*********************] 1 of 1 completed [*******************100%*********************] 1 of 1 completed [*******************100%*********************] 1 of 1 completed [*******************100%*********************] 1 of 1 completed [*******************100%*********************] 1 of 1 completed [*******************100%*********************] 1 of 1 completed [*******************100%*********************] 1 of 1 completed [*******************100%*********************] 1 of 1 completed [*******************100%*********************] 1 of 1 completed
# Calcular características (media y desviación estándar del retorno diario)
features = []
for ticker in tickers:
df = data[ticker]
df["Rendimiento diario"] = df["Adj Close"].pct_change()
mean_return = df["Rendimiento diario"].mean()
std_return = df["Rendimiento diario"].std()
features.append([ticker, mean_return, std_return])
# Crear un DataFrame con las características
features_df = pd.DataFrame(
features, columns=["Ticker", "Media rendimientos", "Desviación estándar"]
)
print(features_df)
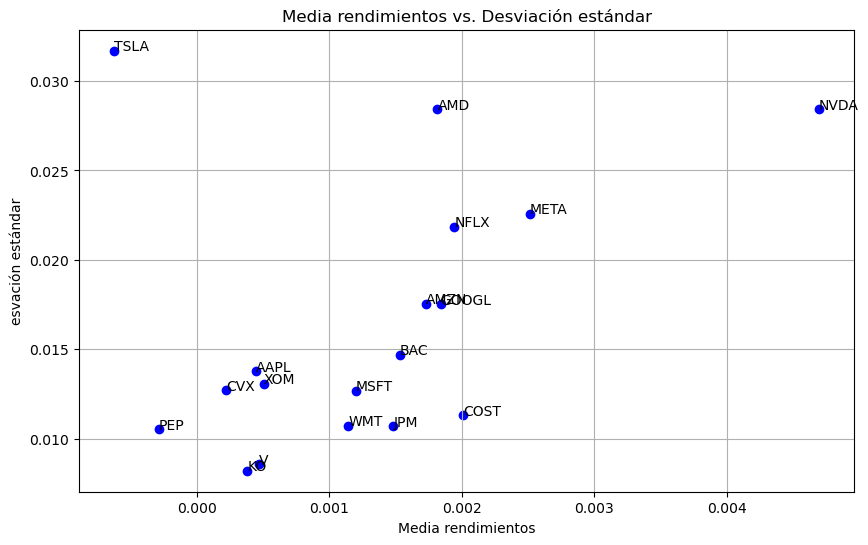
# Graficar los datos
plt.figure(figsize=(10, 6))
plt.scatter(
features_df["Media rendimientos"], features_df["Desviación estándar"], color="blue"
)
# Añadir etiquetas a cada punto
for i in range(features_df.shape[0]):
plt.text(
features_df["Media rendimientos"][i],
features_df["Desviación estándar"][i],
features_df["Ticker"][i],
)
plt.xlabel("Media rendimientos")
plt.ylabel("esvación estándar")
plt.title("Media rendimientos vs. Desviación estándar")
plt.grid(True)
plt.show()
Ticker Media rendimientos Desviación estándar
0 AAPL 0.000445 0.013786
1 MSFT 0.001200 0.012674
2 GOOGL 0.001838 0.017509
3 META 0.002511 0.022573
4 AMZN 0.001728 0.017548
5 TSLA -0.000623 0.031697
6 NVDA 0.004694 0.028430
7 AMD 0.001815 0.028429
8 NFLX 0.001942 0.021858
9 WMT 0.001140 0.010716
10 COST 0.002010 0.011295
11 KO 0.000381 0.008206
12 PEP -0.000288 0.010535
13 JPM 0.001482 0.010693
14 V 0.000468 0.008557
15 BAC 0.001532 0.014706
16 XOM 0.000507 0.013064
17 CVX 0.000221 0.012696
df = features_df[["Media rendimientos", "Desviación estándar"]]
print(df)
Media rendimientos Desviación estándar
0 0.000445 0.013786
1 0.001200 0.012674
2 0.001838 0.017509
3 0.002511 0.022573
4 0.001728 0.017548
5 -0.000623 0.031697
6 0.004694 0.028430
7 0.001815 0.028429
8 0.001942 0.021858
9 0.001140 0.010716
10 0.002010 0.011295
11 0.000381 0.008206
12 -0.000288 0.010535
13 0.001482 0.010693
14 0.000468 0.008557
15 0.001532 0.014706
16 0.000507 0.013064
17 0.000221 0.012696
Ajuste Cluster K-Means:#
wcss = []
silhouette_scores = []
K = range(2, 11)
for k in K:
kmeans = KMeans(n_clusters=k, random_state=34)
kmeans.fit(df)
wcss.append(kmeans.inertia_)
labels = kmeans.labels_
score = silhouette_score(df, labels)
silhouette_scores.append(score)
# Visualizar los resultados del método del codo y de la silueta
plt.figure(figsize=(16, 6))
plt.subplot(1, 2, 1)
plt.plot(K, wcss, "bo-")
plt.xlabel("Número de clústeres (K)")
plt.ylabel("WCSS")
plt.title("Método del Codo")
plt.subplot(1, 2, 2)
plt.plot(K, silhouette_scores, "bo-")
plt.xlabel("Número de clústeres (K)")
plt.ylabel("Puntuación de la Silueta")
plt.title("Método de la Silueta")
plt.tight_layout()
plt.show()
k = 4
# Ajustar K-Means con el número óptimo de clústeres
kmeans = KMeans(n_clusters=k, random_state=34)
kmeans.fit(df)
labels = kmeans.labels_
# Agregar los clusters al DataFrame
df["cluster"] = labels
print("Cantidad de acciones por cluster:\n", df["cluster"].value_counts().sort_index())
Cantidad de acciones por cluster:
0 5
1 3
2 4
3 6
Name: cluster, dtype: int64
# Generar colores dinámicamente
cmap = plt.get_cmap("tab10")
colors = [cmap(i) for i in range(k)]
# Graficar los datos
plt.figure(figsize=(10, 6))
for cluster in range(k):
clustered = df[df["cluster"] == cluster]
plt.scatter(
clustered["Media rendimientos"],
clustered["Desviación estándar"],
color=colors[cluster],
label=f"Cluster {cluster}",
)
# Añadir etiquetas a cada punto
for i in range(features_df.shape[0]):
plt.text(
features_df["Media rendimientos"][i],
features_df["Desviación estándar"][i],
features_df["Ticker"][i],
)
plt.xlabel("Media rendimientos")
plt.ylabel("Desviación estándar")
plt.title("Media rendimientos vs. Desviación estándar")
plt.legend()
plt.grid(True)
plt.show()
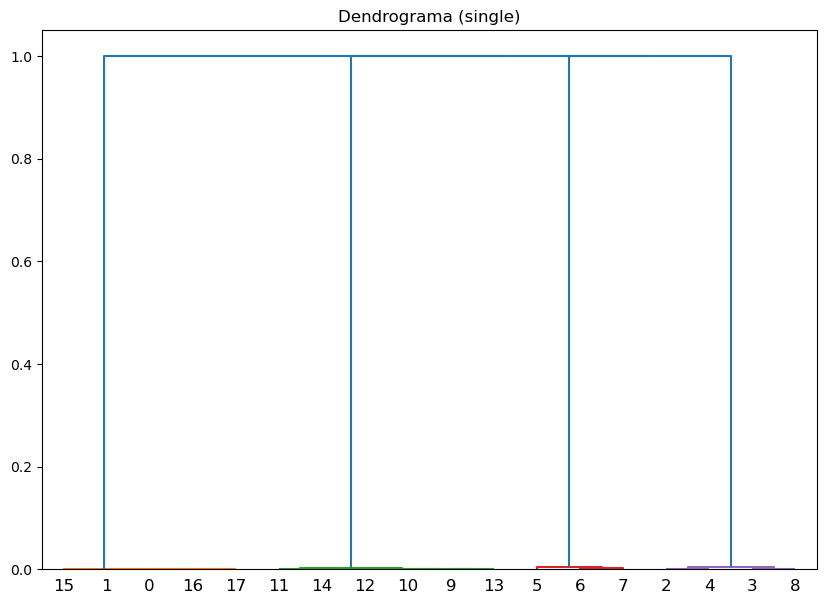
Ajuste Cluster jerárquico:#
# Métodos de vinculación a probar
linkage_methods = ["single", "complete", "average", "ward"]
for method in linkage_methods:
# Crear la matriz de enlaces
Z = linkage(df, method=method)
# Calcular la correlación coefénica
c, coph_dists = cophenet(Z, pdist(df))
print(f"Método de vinculación: {method}, Correlación cofenética: {c:.4f}")
# Plot del dendrograma
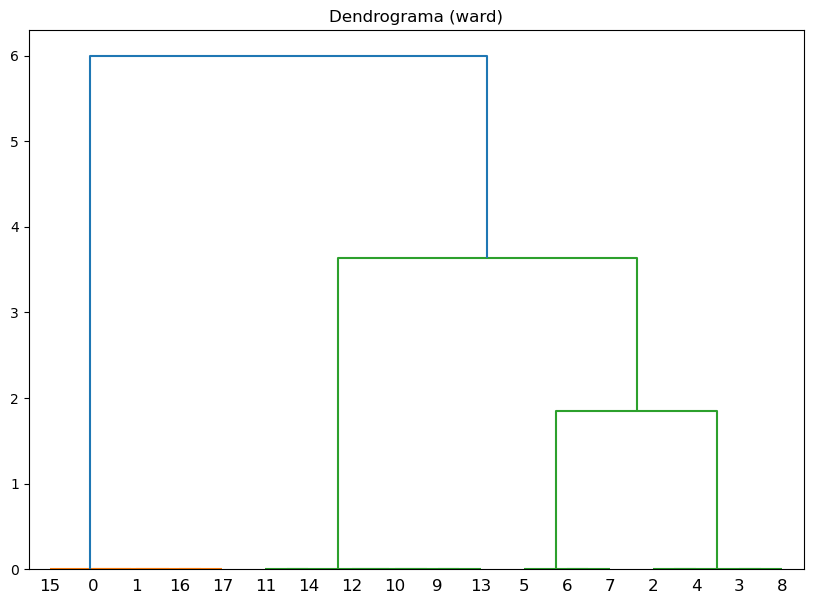
plt.figure(figsize=(10, 7))
plt.title(f"Dendrograma ({method})")
dendrogram(Z)
plt.show()
Método de vinculación: single, Correlación cofenética: 0.7292
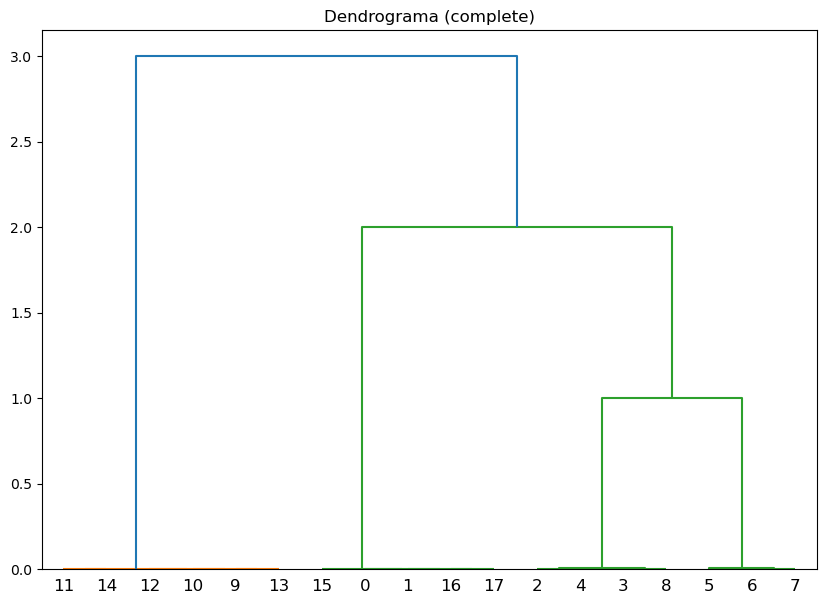
Método de vinculación: complete, Correlación cofenética: 0.7838
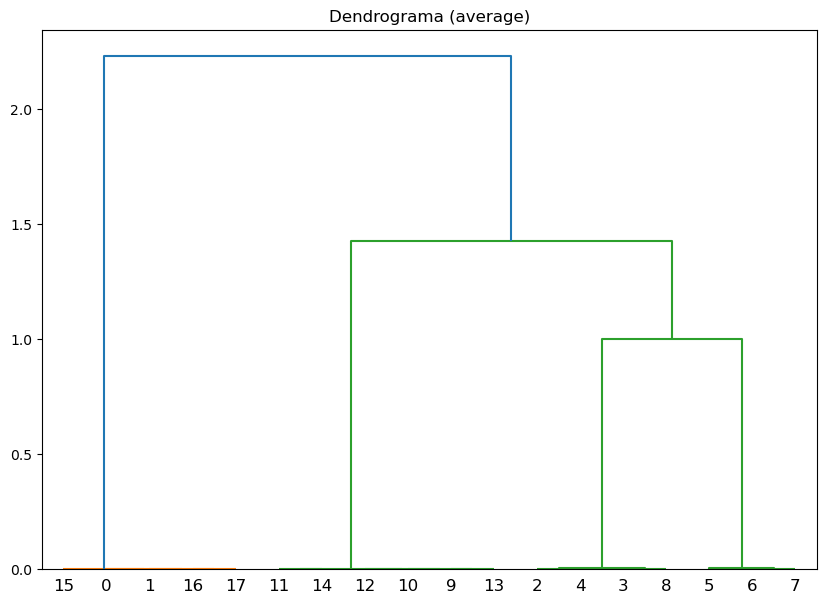
Método de vinculación: average, Correlación cofenética: 0.8282
Método de vinculación: ward, Correlación cofenética: 0.8245
range_n_clusters = range(2, 11)
silhouette_avg_values = []
for n_clusters in range_n_clusters:
# Agrupar los datos con AgglomerativeClustering
clusterer = AgglomerativeClustering(n_clusters=n_clusters, linkage="average")
cluster_labels = clusterer.fit_predict(df)
# Calcular el silhouette score medio
silhouette_avg = silhouette_score(df, cluster_labels)
silhouette_avg_values.append(silhouette_avg)
# Graficar el silhouette score para cada número de clusters
plt.figure(figsize=(10, 6))
plt.plot(range_n_clusters, silhouette_avg_values, "bo-")
plt.xlabel("Número de clusters")
plt.ylabel("Silhouette Score promedio")
plt.title("Silhouette Score para diferentes números de clusters")
plt.show()
# Asignar clusters
k = 4 # Definir el número de clusters
metodo = "average"
model = AgglomerativeClustering(n_clusters=k, linkage=metodo)
labels = model.fit_predict(df)
# Agregar los clusters al DataFrame
df["cluster"] = labels
print("Cantidad de acciones por cluster:\n", df["cluster"].value_counts().sort_index())
Cantidad de acciones por cluster:
0 3
1 4
2 6
3 5
Name: cluster, dtype: int64
# Generar colores dinámicamente
cmap = plt.get_cmap("tab10")
colors = [cmap(i) for i in range(k)]
# Graficar los datos
plt.figure(figsize=(10, 6))
for cluster in range(k):
clustered = df[df["cluster"] == cluster]
plt.scatter(
clustered["Media rendimientos"],
clustered["Desviación estándar"],
color=colors[cluster],
label=f"Cluster {cluster}",
)
# Añadir etiquetas a cada punto
for i in range(features_df.shape[0]):
plt.text(
features_df["Media rendimientos"][i],
features_df["Desviación estándar"][i],
features_df["Ticker"][i],
)
plt.xlabel("Media rendimientos")
plt.ylabel("Desviación estándar")
plt.title("Media rendimientos vs. Desviación estándar")
plt.legend()
plt.grid(True)
plt.show()
Ajuste Cluster DBSCAN:#
# Definir los valores de eps y min_samples para evaluar
eps_values = np.arange(0.1, 2, 0.1)
min_samples_values = range(1, 20, 2)
# Almacenar las puntuaciones de silueta
results = []
for eps in eps_values:
for min_samples in min_samples_values:
db = DBSCAN(eps=eps, min_samples=min_samples)
dbscan_labels = db.fit_predict(df)
if len(set(dbscan_labels)) > 1: # Asegurarse de que hay más de un cluster
silhouette_avg = silhouette_score(df, dbscan_labels)
results.append((eps, min_samples, silhouette_avg))
else:
results.append((eps, min_samples, -1))
# Convertir los resultados a un DataFrame
import pandas as pd
results_df = pd.DataFrame(results, columns=["eps", "min_samples", "silhouette_score"])
# Visualizar los resultados en un heatmap
pivot_table = results_df.pivot(index='eps', columns='min_samples', values='silhouette_score')
plt.figure(figsize=(10, 7))
sns.heatmap(pivot_table, annot=True, fmt=".4f", cmap="viridis")
plt.title("Puntuación de Silueta para diferentes combinaciones de eps y min_samples")
plt.show()
eps = 1
min_samples = 3
# Aplicar DBSCAN
db = DBSCAN(eps=eps, min_samples=min_samples).fit(df)
labels = db.labels_
print(set(labels))
# Número de clusters en las etiquetas, ignorando el ruido si está presente.
n_clusters_ = len(set(labels)) - (1 if -1 in labels else 0) # Tener en cuenta que el cluster -1 es el ruido.
n_noise_ = list(labels).count(-1)
print(f"Número de clusters: {n_clusters_}")
print(f"Número de puntos de ruido: {n_noise_}")
labels = db.fit_predict(df)
# Agregar los clusters al DataFrame
df["cluster"] = labels
# Calcular el índice de silueta
silhouette_scores = silhouette_score(df, labels)
print(f"Puntuación de Silueta: {silhouette_scores:.4f}")
print("Cantidad de acciones por cluster:\n", df["cluster"].value_counts().sort_index())
{0, 1, 2, 3}
Número de clusters: 4
Número de puntos de ruido: 0
Puntuación de Silueta: 0.9975
Cantidad de acciones por cluster:
0 5
1 4
2 3
3 6
Name: cluster, dtype: int64
# Generar colores dinámicamente
cmap = plt.get_cmap("tab10")
colors = [cmap(i) for i in range(k)]
# Graficar los datos
plt.figure(figsize=(10, 6))
for cluster in range(k):
clustered = df[df["cluster"] == cluster]
plt.scatter(
clustered["Media rendimientos"],
clustered["Desviación estándar"],
color=colors[cluster],
label=f"Cluster {cluster}",
)
# Añadir etiquetas a cada punto
for i in range(features_df.shape[0]):
plt.text(
features_df["Media rendimientos"][i],
features_df["Desviación estándar"][i],
features_df["Ticker"][i],
)
plt.xlabel("Media rendimientos")
plt.ylabel("Desviación estándar")
plt.title("Media rendimientos vs. Desviación estándar")
plt.legend()
plt.grid(True)
plt.show()