Ejemplo clustering DBSCAN Estados Financieros#
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.cluster import DBSCAN
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import silhouette_score
import seaborn as sns
# Cargar los datos
data_pymes = pd.read_excel("../210030_Estado de situación financiera, corriente_no corriente_PYMES.xlsx")
data_grandes = pd.read_excel("../210030_Estado de situación financiera, corriente_no corriente.xlsx")
G4631 - Comercio al por mayor de productos alimenticios:#
# Función para filtrar, calcular indicadores y eliminar outliers
def filtrar_y_calcular(data, ciiu):
filtered_data = data[
(data['Clasificación Industrial Internacional Uniforme Versión 4 A.C (CIIU)'] == ciiu) &
(data['Periodo'] == 'Periodo Actual')
].copy()
# Calcular los indicadores de liquidez y endeudamiento utilizando los nombres exactos de las columnas
filtered_data.loc[:, 'Liquidez'] = filtered_data['Activos corrientes totales (CurrentAssets)'] / filtered_data['Pasivos corrientes totales (CurrentLiabilities)']
filtered_data.loc[:, 'Endeudamiento'] = filtered_data['Total pasivos (Liabilities)'] / filtered_data['Total de activos (Assets)']
filtered_data.loc[:, 'UtilidadesAcumuladas'] = filtered_data['Ganancias acumuladas (RetainedEarnings)']
filtered_data.replace([np.inf, -np.inf], np.nan, inplace=True)
variables = ['Liquidez', 'Endeudamiento', 'UtilidadesAcumuladas']
filtered_data = filtered_data[variables].dropna().copy()
# Identificar y eliminar valores atípicos usando el IQR
numeric_cols = filtered_data.select_dtypes(include=[np.number]).columns
Q1 = filtered_data[numeric_cols].quantile(0.25)
Q3 = filtered_data[numeric_cols].quantile(0.75)
IQR = Q3 - Q1
lower_bound = Q1 - 1.5 * IQR
upper_bound = Q3 + 1.5 * IQR
filtered_data = filtered_data[~((filtered_data[numeric_cols] < lower_bound) | (filtered_data[numeric_cols] > upper_bound)).any(axis=1)]
return filtered_data
# Filtrar y calcular indicadores
CIIU = "G4631 - Comercio al por mayor de productos alimenticios"
data_pymes_filtered = filtrar_y_calcular(data_pymes, CIIU)
data_grandes_filtered = filtrar_y_calcular(data_grandes, CIIU)
# Agregar etiquetas
data_pymes_filtered['Tipo'] = 'Pyme'
data_grandes_filtered['Tipo'] = 'Grande'
# Unir los datos
combined_data = pd.concat([data_pymes_filtered, data_grandes_filtered], ignore_index=True)
print("Industria: ", CIIU)
print("Cantidad empresas grandes: ", data_grandes_filtered.shape[0])
print("Cantidad empresas pymes: ", data_pymes_filtered.shape[0])
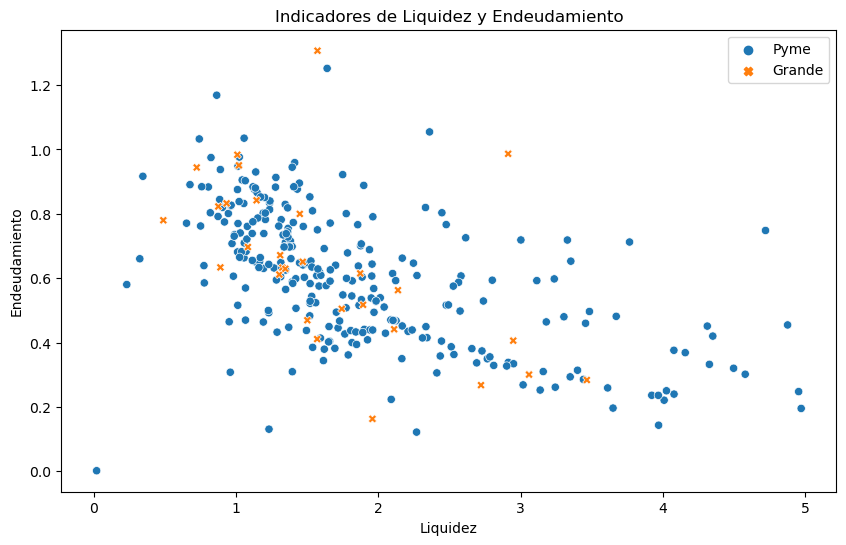
# Graficar los resultados en 2D
plt.figure(figsize=(10, 6))
sns.scatterplot(data=combined_data, x='Liquidez', y='Endeudamiento', hue='Tipo', style='Tipo')
plt.title('Indicadores de Liquidez y Endeudamiento')
plt.xlabel('Liquidez')
plt.ylabel('Endeudamiento')
plt.legend()
plt.show()
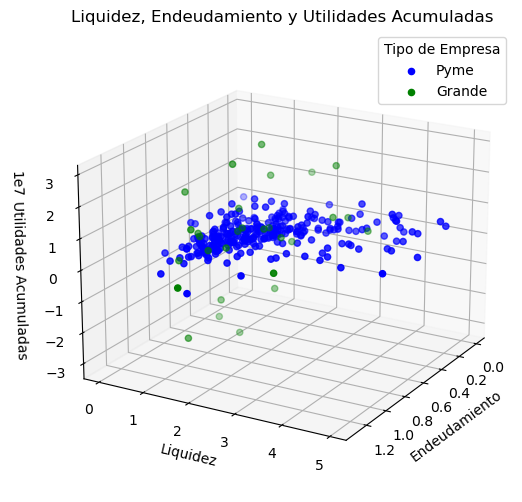
# Graficar los resultados en 3D
fig = plt.figure(figsize=(12, 6))
ax1 = fig.add_subplot(projection='3d')
# Filtrar los datos por tipo de empresa para graficar con colores diferentes
pymes = combined_data[combined_data['Tipo'] == 'Pyme']
grandes = combined_data[combined_data['Tipo'] == 'Grande']
# Graficar puntos para cada tipo
ax1.scatter(pymes['Endeudamiento'], pymes['Liquidez'], pymes['UtilidadesAcumuladas'], color='blue', label='Pyme')
ax1.scatter(grandes['Endeudamiento'], grandes['Liquidez'], grandes['UtilidadesAcumuladas'], color='green', label='Grande')
# Ajustes adicionales de la gráfica
ax1.set_xlabel('Endeudamiento')
ax1.set_ylabel('Liquidez')
ax1.set_zlabel('Utilidades Acumuladas')
ax1.set_title('Liquidez, Endeudamiento y Utilidades Acumuladas')
ax1.view_init(elev=20, azim=30)
# Crear leyenda
ax1.legend(title="Tipo de Empresa")
plt.show()
print(combined_data.head())
Industria: G4631 - Comercio al por mayor de productos alimenticios
Cantidad empresas grandes: 29
Cantidad empresas pymes: 282
Liquidez Endeudamiento UtilidadesAcumuladas Tipo
0 1.236270 0.833611 554338.0 Pyme
1 1.386163 0.660544 2181803.0 Pyme
2 1.366260 0.754717 9824698.0 Pyme
3 1.532488 0.543482 793405.0 Pyme
4 1.012583 0.515712 3113417.0 Pyme
Ajuste del modelo:#
df = combined_data.iloc[:, :-1]
df.head()
| Liquidez | Endeudamiento | UtilidadesAcumuladas | |
|---|---|---|---|
| 0 | 1.236270 | 0.833611 | 554338.0 |
| 1 | 1.386163 | 0.660544 | 2181803.0 |
| 2 | 1.366260 | 0.754717 | 9824698.0 |
| 3 | 1.532488 | 0.543482 | 793405.0 |
| 4 | 1.012583 | 0.515712 | 3113417.0 |
scaler = StandardScaler()
df_scaled = scaler.fit_transform(df)
# Aplicar DBSCAN
db = DBSCAN(eps=0.3, min_samples=10).fit(df_scaled)
labels = db.labels_
print(set(labels))
# Número de clusters en las etiquetas, ignorando el ruido si está presente.
n_clusters_ = len(set(labels)) - (1 if -1 in labels else 0) # Tener en cuenta que el cluster -1 es el ruido.
n_noise_ = list(labels).count(-1)
print(f"Número de clusters: {n_clusters_}")
print(f"Número de puntos de ruido: {n_noise_}")
dbscan_labels = db.fit_predict(df_scaled)
# Calcular el índice de silueta
silhouette_scores = silhouette_score(df_scaled, dbscan_labels)
print(f"Puntuación de Silueta: {silhouette_scores:.4f}")
# Crear el gráfico 3D
fig = plt.figure(figsize=(10, 7))
ax = fig.add_subplot(111, projection="3d")
# Colores para los diferentes clusters
unique_labels = set(labels)
colors = [plt.cm.Spectral(each) for each in np.linspace(0, 1, len(unique_labels))]
for k, col in zip(unique_labels, colors):
class_member_mask = labels == k
xyz = df_scaled[class_member_mask]
ax.scatter(
xyz[:, 0],
xyz[:, 1],
xyz[:, 2],
c=[tuple(col)],
label=f"Cluster {k}",
s=20,
edgecolor="k",
)
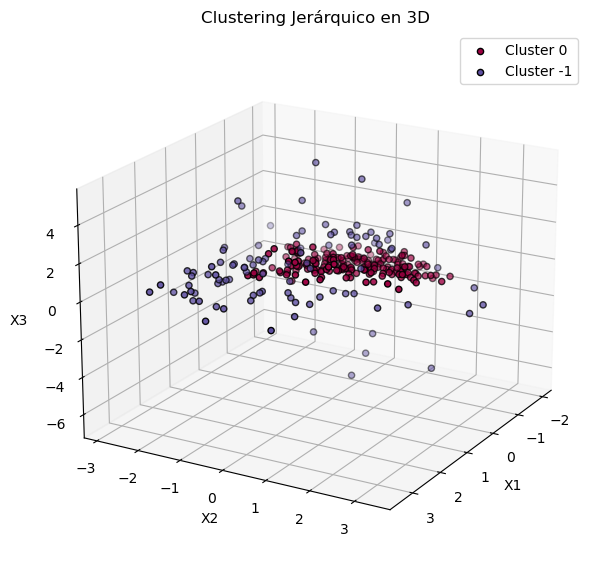
ax.view_init(elev=20, azim=30)
plt.title("Clustering Jerárquico en 3D")
ax.set_xlabel("X1")
ax.set_ylabel("X2")
ax.set_zlabel("X3")
plt.legend()
plt.show()
{0, 1, -1}
Número de clusters: 2
Número de puntos de ruido: 198
Puntuación de Silueta: -0.1010
Determinar los valores de eps y min_samples:#
# Definir los valores de eps y min_samples para evaluar
eps_values = np.arange(0.1, 0.6, 0.1)
min_samples_values = range(5, 16, 5)
# Almacenar las puntuaciones de silueta
results = []
for eps in eps_values:
for min_samples in min_samples_values:
db = DBSCAN(eps=eps, min_samples=min_samples)
dbscan_labels = db.fit_predict(df_scaled)
if len(set(dbscan_labels)) > 1: # Asegurarse de que hay más de un cluster
silhouette_avg = silhouette_score(df_scaled, dbscan_labels)
results.append((eps, min_samples, silhouette_avg))
print(
f"eps: {eps}, min_samples: {min_samples}, Puntuación de Silueta: {silhouette_avg:.4f}"
)
else:
results.append((eps, min_samples, -1))
print(
f"eps: {eps}, min_samples: {min_samples}, Puntuación de Silueta: No aplicable"
)
# Convertir los resultados a un DataFrame
import pandas as pd
results_df = pd.DataFrame(results, columns=["eps", "min_samples", "silhouette_score"])
# Visualizar los resultados en un heatmap
pivot_table = results_df.pivot(index='eps', columns='min_samples', values='silhouette_score')
plt.figure(figsize=(10, 7))
sns.heatmap(pivot_table, annot=True, fmt=".4f", cmap="viridis")
plt.title("Puntuación de Silueta para diferentes combinaciones de eps y min_samples")
plt.show()
eps: 0.1, min_samples: 5, Puntuación de Silueta: -0.3286
eps: 0.1, min_samples: 10, Puntuación de Silueta: No aplicable
eps: 0.1, min_samples: 15, Puntuación de Silueta: No aplicable
eps: 0.2, min_samples: 5, Puntuación de Silueta: -0.2815
eps: 0.2, min_samples: 10, Puntuación de Silueta: No aplicable
eps: 0.2, min_samples: 15, Puntuación de Silueta: No aplicable
eps: 0.30000000000000004, min_samples: 5, Puntuación de Silueta: -0.1728
eps: 0.30000000000000004, min_samples: 10, Puntuación de Silueta: -0.1010
eps: 0.30000000000000004, min_samples: 15, Puntuación de Silueta: -0.2203
eps: 0.4, min_samples: 5, Puntuación de Silueta: 0.1426
eps: 0.4, min_samples: 10, Puntuación de Silueta: 0.2692
eps: 0.4, min_samples: 15, Puntuación de Silueta: 0.2073
eps: 0.5, min_samples: 5, Puntuación de Silueta: 0.1548
eps: 0.5, min_samples: 10, Puntuación de Silueta: 0.3236
eps: 0.5, min_samples: 15, Puntuación de Silueta: 0.3060
Mejor modelo:#
eps=0.5
min_samples=10:
eps = 0.5
min_samples = 10
# Aplicar DBSCAN
db = DBSCAN(eps=eps, min_samples=min_samples).fit(df_scaled)
labels = db.labels_
print(set(labels))
# Número de clusters en las etiquetas, ignorando el ruido si está presente.
n_clusters_ = len(set(labels)) - (1 if -1 in labels else 0) # Tener en cuenta que el cluster -1 es el ruido.
n_noise_ = list(labels).count(-1)
print(f"Número de clusters: {n_clusters_}")
print(f"Número de puntos de ruido: {n_noise_}")
dbscan_labels = db.fit_predict(df_scaled)
# Calcular el índice de silueta
silhouette_scores = silhouette_score(df_scaled, dbscan_labels)
print(f"Puntuación de Silueta: {silhouette_scores:.4f}")
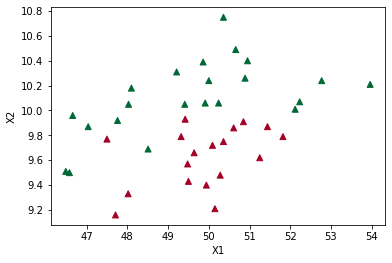
# Crear el gráfico 3D
fig = plt.figure(figsize=(10, 7))
ax = fig.add_subplot(111, projection="3d")
# Colores para los diferentes clusters
unique_labels = set(labels)
colors = [plt.cm.Spectral(each) for each in np.linspace(0, 1, len(unique_labels))]
for k, col in zip(unique_labels, colors):
class_member_mask = labels == k
xyz = df_scaled[class_member_mask]
ax.scatter(
xyz[:, 0],
xyz[:, 1],
xyz[:, 2],
c=[tuple(col)],
label=f"Cluster {k}",
s=20,
edgecolor="k",
)
ax.view_init(elev=20, azim=30)
plt.title("Clustering Jerárquico en 3D")
ax.set_xlabel("X1")
ax.set_ylabel("X2")
ax.set_zlabel("X3")
plt.legend()
plt.show()
{0, -1}
Número de clusters: 1
Número de puntos de ruido: 98
Puntuación de Silueta: 0.3236