Auto-ARIMA precio de electricidad#
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib.dates as mdates
from statsmodels.tsa.stattools import adfuller
from statsmodels.graphics.tsaplots import plot_acf, plot_pacf
from scipy.stats import boxcox
from statsmodels.tsa.statespace.sarimax import SARIMAX
import statsmodels.api as sm
from scipy.stats import norm
Funciones#
def plot_serie_tiempo(
serie: pd.DataFrame,
nombre: str,
unidades: str = None,
columna: str = None,
fecha_inicio: str = None,
fecha_fin: str = None,
color: str = 'navy',
linewidth: float = 2,
num_xticks: int = 12,
estacionalidad: str = None, # 'diciembre', 'enero', 'semana', 'semestre', 'custom_month'
custom_month: int = None, # Si quieres marcar otro mes (ejemplo: 3 para marzo)
vline_label: str = None, # Etiqueta para la(s) línea(s) vertical(es)
hlines: list = None, # lista de valores horizontales a marcar
hlines_labels: list = None, # lista de etiquetas para líneas horizontales
color_estacion: str = 'darkgray', # color de las líneas estacionales
alpha_estacion: float = 0.3, # transparencia de líneas estacionales
color_hline: str = 'gray', # color de las líneas horizontales
alpha_hline: float = 0.7 # transparencia de líneas horizontales
):
"""
Gráfico elegante de serie de tiempo.
- Eje X alineado con la primera fecha real de la serie.
- Opcional: marcar estacionalidades (diciembres, semanas, semestres, mes personalizado) con etiqueta.
- Líneas horizontales con etiqueta opcional (legend).
"""
df = serie.copy()
if columna is None:
columna = df.columns[0]
if fecha_inicio:
df = df[df.index >= fecha_inicio]
if fecha_fin:
df = df[df.index <= fecha_fin]
# Asegura que el índice sea datetime y esté ordenado
df = df.sort_index()
df.index = pd.to_datetime(df.index)
plt.style.use('ggplot')
fig, ax = plt.subplots(figsize=(14, 6))
# Gráfica principal
ax.plot(df.index, df[columna], color=color, linewidth=linewidth, label=nombre)
ax.set_title(f"Serie de tiempo: {nombre}", fontsize=20, weight='bold',
color='black')
ax.set_xlabel("Fecha", fontsize=15, color='black')
ax.set_ylabel(unidades, fontsize=15, color='black')
ax.tick_params(axis='both', colors='black', labelsize=13)
for label in ax.get_xticklabels() + ax.get_yticklabels():
label.set_color('black')
# Limita el rango del eje X exactamente al rango de fechas de la serie (no corrido)
ax.set_xlim(df.index.min(), df.index.max())
# Ticks equidistantes en eje X, asegurando que empieza en la primera fecha
idx = df.index
if len(idx) > num_xticks:
ticks = np.linspace(0, len(idx)-1, num_xticks, dtype=int)
ticks[0] = 0 # asegúrate que arranque en la primera fecha
ticklabels = [idx[i] for i in ticks]
ax.set_xticks(ticklabels)
ax.set_xticklabels([pd.to_datetime(t).strftime('%b %Y') for t in ticklabels], rotation=0, color='black')
else:
ax.xaxis.set_major_formatter(mdates.DateFormatter('%b %Y'))
fig.autofmt_xdate(rotation=0)
# ==============================
# LÍNEAS VERTICALES: Estacionalidad (con etiqueta en leyenda si se desea)
# ==============================
vlines_plotted = False
if estacionalidad is not None:
if estacionalidad == 'diciembre':
fechas_mark = df[df.index.month == 12].index
elif estacionalidad == 'enero':
fechas_mark = df[df.index.month == 1].index
elif estacionalidad == 'semana':
fechas_mark = df[df.index.weekday == 0].index
elif estacionalidad == 'semestre':
fechas_mark = df[df.index.month.isin([6, 12])].index
elif estacionalidad == 'custom_month' and custom_month is not None:
fechas_mark = df[df.index.month == custom_month].index
else:
fechas_mark = []
for i, f in enumerate(fechas_mark):
# Solo pone la etiqueta una vez (la primera línea)
if not vlines_plotted and vline_label is not None:
ax.axvline(f, color=color_estacion, alpha=alpha_estacion, linewidth=2, linestyle='--', zorder=0, label=vline_label)
vlines_plotted = True
else:
ax.axvline(f, color=color_estacion, alpha=alpha_estacion, linewidth=2, linestyle='--', zorder=0)
# ==============================
# LÍNEAS HORIZONTALES OPCIONALES, con leyenda
# ==============================
if hlines is not None:
if hlines_labels is None:
hlines_labels = [None] * len(hlines)
for i, h in enumerate(hlines):
if hlines_labels[i] is not None:
ax.axhline(h, color=color_hline, alpha=alpha_hline, linewidth=1.5, linestyle='--', zorder=0, label=hlines_labels[i])
else:
ax.axhline(h, color=color_hline, alpha=alpha_hline, linewidth=1.5, linestyle='--', zorder=0)
# Coloca la leyenda solo si hay etiquetas
handles, labels = ax.get_legend_handles_labels()
if any(labels):
ax.legend(loc='best', fontsize=13, frameon=True)
ax.grid(True, alpha=0.4)
plt.tight_layout()
plt.show()
##################################################################################
def analisis_estacionariedad_full(
serie: pd.Series,
nombre: str = None,
lags: int = 24,
xtick_interval: int = 3
):
"""
Gráfica y análisis de estacionariedad para una serie de tiempo con múltiples transformaciones:
- Serie original
- Diferenciación
- Logaritmo
- Diferenciación del Logaritmo
- Raíz cuadrada
- Diferenciación de la raíz cuadrada
- Box-Cox (con corrimiento si hay valores <= 0)
- Diferenciación del Box-Cox
Para cada transformación se grafica:
- Serie transformada en el tiempo
- ACF
- PACF
- Resultado de la prueba ADF con interpretación
Args:
serie: Serie de tiempo (índice datetime, pandas.Series)
nombre: Nombre de la serie (para títulos)
lags: Número de rezagos para ACF/PACF
xtick_interval: Mostrar ticks en X cada este número de lags, incluyendo siempre el lag 1
Return:
dict con los resultados de la ADF para cada transformación
"""
if nombre is None:
nombre = serie.name if serie.name is not None else "Serie"
serie = serie.astype(float).copy()
serie_orig = serie.copy()
serie_diff = serie_orig.diff().dropna()
# Logaritmo
if (serie_orig <= 0).any():
log_ok = False
serie_log = pd.Series([np.nan]*len(serie_orig), index=serie_orig.index)
serie_log_diff = pd.Series([np.nan]*len(serie_orig), index=serie_orig.index)
else:
log_ok = True
serie_log = np.log(serie_orig)
serie_log_diff = serie_log.diff().dropna()
# Raíz cuadrada
if (serie_orig < 0).any():
sqrt_ok = False
serie_sqrt = pd.Series([np.nan]*len(serie_orig), index=serie_orig.index)
serie_sqrt_diff = pd.Series([np.nan]*len(serie_orig), index=serie_orig.index)
else:
sqrt_ok = True
serie_sqrt = np.sqrt(serie_orig)
serie_sqrt_diff = serie_sqrt.diff().dropna()
# Box–Cox
if (serie_orig <= 0).any():
shift_bc = 1 - serie_orig.min()
else:
shift_bc = 0.0
serie_bc_input = serie_orig + shift_bc
if (serie_bc_input <= 0).any():
bc_ok = False
serie_boxcox = pd.Series([np.nan]*len(serie_orig), index=serie_orig.index)
serie_boxcox_diff = pd.Series([np.nan]*len(serie_orig), index=serie_orig.index)
lambda_bc = np.nan
else:
bc_ok = True
bc_vals, lambda_bc = boxcox(serie_bc_input.values)
serie_boxcox = pd.Series(bc_vals, index=serie_orig.index)
serie_boxcox_diff = serie_boxcox.diff().dropna()
# --- Títulos actualizados ---
titulos = [
f"Serie original: {nombre}",
"Diferenciación",
"Logaritmo" + ("" if log_ok else " (no aplicable)"),
"Diferenciación del Logaritmo" + ("" if log_ok else " (no aplicable)"),
"Raíz cuadrada" + ("" if sqrt_ok else " (no aplicable)"),
"Diferenciación de la raíz cuadrada" + ("" if sqrt_ok else " (no aplicable)"),
"Box-Cox" + (f" (λ = {lambda_bc:.4f})" if bc_ok else " (no aplicable)"),
"Diferenciación del Box-Cox" + ("" if bc_ok else " (no aplicable)")
]
series = [
serie_orig,
serie_diff,
serie_log,
serie_log_diff,
serie_sqrt,
serie_sqrt_diff,
serie_boxcox,
serie_boxcox_diff
]
# --- ADF ---
resultados_adf = []
interpretaciones = []
for i, s in enumerate(series):
s_ = s.dropna()
if len(s_) < 5:
resultados_adf.append((np.nan, np.nan))
interpretaciones.append("No evaluable")
continue
regression_type = 'ct' if i in [0, 2, 4, 6] else 'c'
try:
adf_res = adfuller(s_, regression=regression_type, autolag='AIC')
estadistico = adf_res[0]
pvalue = adf_res[1]
except Exception:
estadistico = np.nan
pvalue = np.nan
resultados_adf.append((estadistico, pvalue))
interpretaciones.append("Estacionaria" if (pvalue is not None and pvalue < 0.05) else "No estacionaria")
# --- Gráficos ---
filas = len(series)
fig, axes = plt.subplots(filas, 3, figsize=(18, 4*filas), squeeze=False)
colores = ['black'] * filas
for fila in range(filas):
serie_fila = series[fila]
# Serie temporal
axes[fila, 0].plot(serie_fila, color=colores[fila], lw=1)
axes[fila, 0].set_title(titulos[fila], color='black')
axes[fila, 0].set_xlabel("Fecha", color='black')
if fila == 0:
ylabel = "Valor"
elif fila == 1:
ylabel = "Δ Valor"
elif fila == 2:
ylabel = "Log(Valor)"
elif fila == 3:
ylabel = "Δ Log(Valor)"
elif fila == 4:
ylabel = "√Valor"
elif fila == 5:
ylabel = "Δ √Valor"
elif fila == 6:
ylabel = "Box-Cox"
else:
ylabel = "Δ Box-Cox"
axes[fila, 0].set_ylabel(ylabel, color='black')
axes[fila, 0].grid(True, alpha=0.3)
axes[fila, 0].tick_params(axis='both', labelsize=11, colors='black')
adf_est, adf_p = resultados_adf[fila]
axes[fila, 0].text(
0.02, 0.85,
f"ADF: {adf_est:.2f}\np-valor: {adf_p:.4f}\n{interpretaciones[fila]}",
transform=axes[fila, 0].transAxes,
fontsize=11,
bbox=dict(facecolor='white', alpha=0.85),
color='black'
)
# ACF
try:
plot_acf(serie_fila.dropna(), lags=lags, ax=axes[fila, 1], zero=False, color=colores[fila])
except Exception:
axes[fila, 1].text(0.5, 0.5, "ACF no disponible", ha='center', va='center')
axes[fila, 1].set_title("ACF", color='black')
xticks = [1] + list(range(xtick_interval, lags + 1, xtick_interval))
axes[fila, 1].set_xticks(sorted(set(xticks)))
axes[fila, 1].tick_params(axis='both', labelsize=11, colors='black')
axes[fila, 1].set_xlabel("Lag", color='black')
# PACF
try:
plot_pacf(serie_fila.dropna(), lags=lags, ax=axes[fila, 2], zero=False, color=colores[fila])
except Exception:
axes[fila, 2].text(0.5, 0.5, "PACF no disponible", ha='center', va='center')
axes[fila, 2].set_title("PACF", color='black')
axes[fila, 2].set_xticks(sorted(set(xticks)))
axes[fila, 2].tick_params(axis='both', labelsize=11, colors='black')
axes[fila, 2].set_xlabel("Lag", color='black')
plt.tight_layout()
plt.show()
# --- Resumen ADF ---
adf_dict = {
titulos[i]: {
"estadístico ADF": resultados_adf[i][0],
"p-valor": resultados_adf[i][1],
"interpretación": interpretaciones[i],
"nota_boxcox": (
f"lambda Box-Cox = {lambda_bc:.4f}, shift aplicado = {shift_bc:.4f}"
if ("Box-Cox" in titulos[i] and bc_ok)
else ("Box-Cox no aplicable" if "Box-Cox" in titulos[i] and not bc_ok else None)
)
}
for i in range(filas)
}
return adf_dict
##################################################################################
def analisis_residuales(
residuals,
nombre: str = "Serie de tiempo",
lags: int = 24,
color_resid: str = "navy",
color_qq: str = "navy",
color_acf_pacf: str = "navy"
):
"""
Análisis gráfico de residuales:
- Residuales en el tiempo (toda la fila superior)
- Histograma + curva normal (izq), QQ-plot (der)
- ACF (izq), PACF (der) con bandas y barras color navy
"""
residuals = residuals[1:].dropna()
mu = residuals.mean()
sigma = residuals.std(ddof=1)
x = np.linspace(residuals.min(), residuals.max(), 400)
pdf = norm.pdf(x, loc=mu, scale=sigma)
fig = plt.figure(constrained_layout=True, figsize=(14, 11))
gs = fig.add_gridspec(3, 2, height_ratios=[1, 1, 1])
# 1. Residuales en el tiempo
ax_time = fig.add_subplot(gs[0, :])
ax_time.scatter(residuals.index, residuals, color=color_resid, alpha=0.7, s=20)
ax_time.axhline(0, ls="--", color="black")
ax_time.set_title(f"Residuales en el tiempo: {nombre}", color='black')
ax_time.set_xlabel("Tiempo", color='black')
ax_time.set_ylabel("Residual", color='black')
ax_time.tick_params(axis='both', labelsize=11, colors='black')
# 2. Histograma + curva Normal
ax_hist = fig.add_subplot(gs[1, 0])
ax_hist.hist(residuals, bins="auto", density=True, alpha=0.6, edgecolor="k", color="royalblue")
ax_hist.plot(x, pdf, lw=2, label=f"N({mu:.3f}, {sigma:.3f}²)", color="darkred")
ax_hist.set_title("Histograma residuaes y ajuste Normal", color='black')
ax_hist.set_xlabel("Residual", color='black')
ax_hist.set_ylabel("Densidad", color='black')
ax_hist.legend(fontsize=9)
ax_hist.grid(alpha=0.18)
ax_hist.tick_params(axis='both', labelsize=10, colors='black')
# 3. QQ-plot
ax_qq = fig.add_subplot(gs[1, 1])
qq = sm.qqplot(residuals, line='45', fit=True, ax=ax_qq, markerfacecolor=color_qq, markeredgecolor=color_qq, marker='o')
lines = ax_qq.get_lines()
if len(lines) >= 1:
lines[0].set_color(color_qq)
lines[0].set_marker('o')
lines[0].set_linestyle('None')
if len(lines) >= 2:
lines[1].set_color("black")
lines[1].set_linestyle("--")
ax_qq.set_title("Q-Q Plot de los residuales", color='black')
ax_qq.set_xlabel("Cuantiles teóricos (Normal)", color='black')
ax_qq.set_ylabel("Cuantiles de los residuales", color='black')
ax_qq.tick_params(axis='both', labelsize=10, colors='black')
for l in ax_qq.get_xticklabels() + ax_qq.get_yticklabels():
l.set_color('black')
# 4. ACF (usando color navy en barras y bandas)
ax_acf = fig.add_subplot(gs[2, 0])
sm.graphics.tsa.plot_acf(residuals, lags=lags, ax=ax_acf, zero=False, color=color_acf_pacf)
ax_acf.set_title("ACF de los residuales", color='black')
ax_acf.set_xlabel("Rezagos", color='black')
ax_acf.set_ylabel("Autocorrelación", color='black')
ax_acf.tick_params(axis='both', labelsize=10, colors='black')
# 5. PACF (usando color navy en barras y bandas)
ax_pacf = fig.add_subplot(gs[2, 1])
sm.graphics.tsa.plot_pacf(residuals, lags=lags, ax=ax_pacf, zero=False, color=color_acf_pacf)
ax_pacf.set_title("PACF de los residuales", color='black')
ax_pacf.set_xlabel("Rezagos", color='black')
ax_pacf.set_ylabel("Autocorrelación parcial", color='black')
ax_pacf.tick_params(axis='both', labelsize=10, colors='black')
plt.show()
return
##################################################################################
def analizar_ajuste_serie(
serie_original,
fitted_values,
results,
test,
n_forecast,
transformacion=None, # 'log', 'boxcox', 'sqrt', o None
lambda_bc=None, # solo si boxcox
nombre="Serie"
):
"""
Analiza el ajuste de un modelo y grafica ajuste+pronóstico sobre la serie original,
devolviendo predicciones revertidas a la escala original.
Args:
serie_original: Serie original (sin transformar, index datetime)
fitted_values: Serie de fittedvalues (en escala transformada)
results: Modelo ajustado de statsmodels (debe soportar .append, .get_forecast)
test: Serie de test (index datetime)
n_forecast: Períodos a pronosticar por fuera de la muestra
transformacion: 'log', 'boxcox', 'sqrt' o None
lambda_bc: Valor de lambda para boxcox (si aplica)
nombre: Nombre para los ejes y leyenda
Returns:
Diccionario con:
- y_pred_train, y_pred_test, forecasting_orig, lower_bt, upper_bt
- Fechas de pronóstico futuro: future_dates
"""
# Alinear índices por seguridad
fitted_values = fitted_values.reindex(serie_original.index.intersection(fitted_values.index))
test = test.copy()
# ----------- PRONÓSTICO EN TEST (fuera de muestra, recursivo) -----------
current_results = results
forecasted_test = []
lower_ci_test = []
upper_ci_test = []
for i in range(len(test)):
forecaster = current_results.get_forecast(steps=1)
forecast_mean_test = forecaster.predicted_mean.iloc[0]
ci_i_test = forecaster.conf_int(alpha=0.05).iloc[0]
forecasted_test.append(forecast_mean_test)
lower_ci_test.append(ci_i_test.iloc[0])
upper_ci_test.append(ci_i_test.iloc[1])
# Recursivo: alimentar el modelo con el valor real observado
current_results = current_results.append(endog=[test.iloc[i]], refit=False)
forecasted_test = pd.Series(forecasted_test, index=test.index, name='forecast_test')
lower_ci_test = pd.Series(lower_ci_test, index=test.index, name='lower_test')
upper_ci_test = pd.Series(upper_ci_test, index=test.index, name='upper_test')
# ----------- PRONÓSTICO FUTURO (n_forecast meses) -----------
current_results = results.append(endog=test, refit=False)
forecasting = []
lower_ci = []
upper_ci = []
for i in range(n_forecast):
forecaster = current_results.get_forecast(steps=1)
forecast_mean = forecaster.predicted_mean.iloc[0]
ci_i = forecaster.conf_int(alpha=0.05).iloc[0]
forecasting.append(forecast_mean)
lower_ci.append(ci_i.iloc[0])
upper_ci.append(ci_i.iloc[1])
current_results = current_results.append(endog=[forecast_mean], refit=False)
# Fechas futuras mensuales (puedes personalizar)
last_date = test.index[-1]
future_dates = pd.date_range(start=last_date + pd.offsets.MonthBegin(1),
periods=n_forecast, freq='MS')
forecasting = pd.Series(forecasting, index=future_dates, name='forecast')
lower_ci = pd.Series(lower_ci, index=future_dates, name='lower')
upper_ci = pd.Series(upper_ci, index=future_dates, name='upper')
# ----------- REVERSIÓN DE TRANSFORMACIÓN -----------
if transformacion == "log":
y_pred_train = np.exp(fitted_values)
y_pred_test = np.exp(forecasted_test)
forecasting_orig = np.exp(forecasting)
lower_bt = np.exp(lower_ci)
upper_bt = np.exp(upper_ci)
elif transformacion == "boxcox":
if lambda_bc is None:
raise ValueError("Debes indicar lambda_bc para la transformación Box-Cox")
y_pred_train = np.power((lambda_bc * fitted_values + 1), 1 / lambda_bc)
y_pred_test = np.power((lambda_bc * forecasted_test + 1), 1 / lambda_bc)
forecasting_orig = np.power((lambda_bc * forecasting + 1), 1 / lambda_bc)
lower_bt = np.power((lambda_bc * lower_ci + 1), 1 / lambda_bc)
upper_bt = np.power((lambda_bc * upper_ci + 1), 1 / lambda_bc)
elif transformacion == "sqrt":
y_pred_train = fitted_values ** 2
y_pred_test = forecasted_test ** 2
forecasting_orig = forecasting ** 2
lower_bt = lower_ci ** 2
upper_bt = upper_ci ** 2
elif transformacion is None or transformacion == "none":
y_pred_train = fitted_values
y_pred_test = forecasted_test
forecasting_orig = forecasting
lower_bt = lower_ci
upper_bt = upper_ci
else:
raise ValueError("Transformación no soportada. Usa 'log', 'boxcox', 'sqrt' o None.")
# ----------- GRÁFICO -----------
plt.figure(figsize=(12,6))
# Serie original
plt.plot(serie_original, label=nombre, color='black')
# Ajuste en train
plt.plot(y_pred_train, label='Ajuste en train', color='tab:blue')
# Ajuste en test
plt.plot(y_pred_test, label='Pronóstico en test', color='tab:green')
# Pronóstico futuro + IC
plt.plot(forecasting_orig, label='Pronóstico futuro', color='tab:red', linestyle='--')
plt.fill_between(future_dates, lower_bt.values, upper_bt.values, color='tab:red', alpha=0.2, label='IC 95%')
plt.title(f'Ajuste y pronóstico - {nombre}')
plt.xlabel('Tiempo')
plt.ylabel('Valor')
plt.legend()
plt.tight_layout()
plt.show()
# ----------- Devuelve resultados clave -----------
return {
'y_pred_train': y_pred_train,
'y_pred_test': y_pred_test,
'forecasting_orig': forecasting_orig,
'lower_bt': lower_bt,
'upper_bt': upper_bt,
'future_dates': future_dates
}
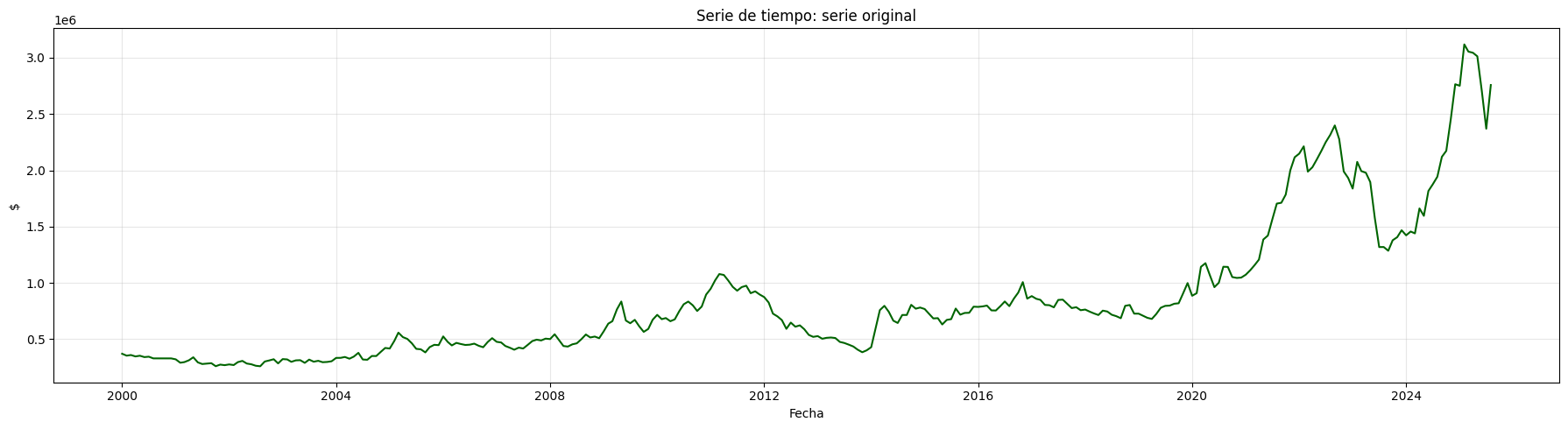
Precio de electricidad#
# Cargar el archivo
precio_electricidad = pd.read_csv("Precio_electricidad.csv")
# Corregir nombres de columnas si tienen espacios
precio_electricidad.columns = precio_electricidad.columns.str.strip()
# Convertir 'Fecha' a datetime y usar como índice
precio_electricidad['Fecha'] = pd.to_datetime(precio_electricidad['Fecha'])
precio_electricidad.set_index('Fecha', inplace=True)
# Ordenar por fecha por si acaso
precio_electricidad = precio_electricidad.sort_index()
# Establecer frecuencia explícita para evitar el warning de statsmodels
precio_electricidad.index.freq = precio_electricidad.index.inferred_freq
precio_electricidad.head()
| Precio | |
|---|---|
| Fecha | |
| 2000-01-01 | 36.539729 |
| 2000-02-01 | 39.885205 |
| 2000-03-01 | 35.568126 |
| 2000-04-01 | 44.957443 |
| 2000-05-01 | 33.848903 |
plot_serie_tiempo(
precio_electricidad,
nombre="Precio de electricidad",
columna='Precio',
unidades='COP/kWh',
estacionalidad='diciembre',
vline_label="Diciembre",
num_xticks = 14
)
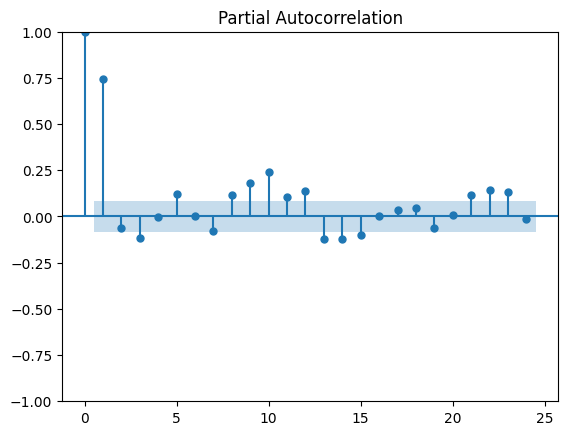
adf_resultados = analisis_estacionariedad_full(
precio_electricidad['Precio'],
nombre="Precio de electricidad",
lags=36,
xtick_interval=3
)
Transformación Box–Cox#
# Aplicar la transformación Box–Cox:
y_boxcox, lambda_bc = boxcox(precio_electricidad.iloc[:, 0])
# Convertir el resultado en pandas.Series
y_boxcox = pd.DataFrame(y_boxcox, index=precio_electricidad.index, columns=['Precio_boxcox'])
print(f"Lambda Box–Cox óptimo: {lambda_bc:.4f}")
print(y_boxcox.head())
Lambda Box–Cox óptimo: -0.3692
Precio_boxcox
Fecha
2000-01-01 1.991101
2000-02-01 2.013932
2000-03-01 1.983928
2000-04-01 2.043960
2000-05-01 1.970553
Conjunto de train y test:#
# Dividir en train y test (por ejemplo, 80% train, 20% test)
split = int(len(y_boxcox) * 0.8)
train, test = y_boxcox[:split], y_boxcox[split:]
# Graficar train y test:
plt.figure(figsize=(12, 5))
plt.plot(train, label='Train', color='navy')
plt.plot(test, label='Test', color='orange')
plt.title("Conjunto de train y test")
plt.xlabel("Fecha")
plt.ylabel("Valor")
plt.legend()
plt.grid(True, alpha=0.3)
plt.tight_layout()
Auto-ARIMA#
Si queremos probar varios valores de p, d y q, debemos
generar todas las combinaciones posibles de esos valores. Para esto se
usa pdq = list(itertools.product(p, d, q)) que genera todas las
combinaciones posibles de (p, d, q).
De acuerdo con la PACF, inicialmente se podrían considerar combinaciones hasta un modelo AR(4), y según la ACF, hasta un MA(3). No obstante, estos valores constituyen únicamente una guía inicial.
Mediante el uso del auto-ARIMA, es posible evaluar modelos con mayores rezagos. Dado que se observan rezagos significativos hasta el lag 13, se probarán todas las combinaciones posibles de ARIMA(p,1,q) con p y q entre 0 y 13, es decir, hasta un ARIMA(13,1,13).
La aplicación del método auto-ARIMA con órdenes de rezago altos puede implicar un tiempo de ejecución considerable, ya que el número de combinaciones de parámetros a evaluar crece de forma exponencial con los valores de p y q. El siguiente ajuste puede tardar varios minutos.
import itertools
from statsmodels.tsa.statespace.sarimax import SARIMAX
Silenciar solo los warning:
import warnings
from statsmodels.tools.sm_exceptions import ConvergenceWarning
warnings.filterwarnings("ignore",
message="Non-invertible starting MA parameters",
category=UserWarning)
warnings.filterwarnings("ignore",
message="Non-stationary starting autoregressive parameters",
category=UserWarning)
warnings.filterwarnings("ignore", category=ConvergenceWarning)
p = q = range(0, 14) # range no toma el último, por tanto se debe indicar un valor adicional.
q = range(0, 14)
d = [1] # para evaluar d = 0 poner d = [0, 1]
pdq = list(itertools.product(p, d, q)) # Todas las combinaciones posibles
trend = 'n' # 'c' = constante, 't' = tendencia, 'ct' = constante + tendencia, 'n' = sin tendencia
best_aic = float("inf")
best_order = None
for order in pdq:
try:
model = SARIMAX(train, order=order, trend=trend)
results = model.fit(disp=False)
if results.aic < best_aic:
best_aic = results.aic
best_order = order
except:
continue
print(f"Mejor modelo ARIMA{best_order} con AIC={best_aic}")
Mejor modelo ARIMA(3, 1, 3) con AIC=-809.5817154695276
Modelo seleccionado#
# Definir los parámetros del modelo ARIMA (p, d, q)
order = (3, 1, 3) # Puedes ajustar según el análisis de ACF y PACF
trend = 'n' # 'c' = constante, 't' = tendencia, 'ct' = constante + tendencia, 'n' = sin tendencia
# Ajustar el modelo con los datos de entrenamiento
model = SARIMAX(train, order=order, trend=trend)
results = model.fit()
# Mostrar resumen del modelo
print(results.summary())
SARIMAX Results
==============================================================================
Dep. Variable: Precio_boxcox No. Observations: 232
Model: SARIMAX(3, 1, 3) Log Likelihood 411.791
Date: Wed, 12 Nov 2025 AIC -809.582
Time: 16:20:12 BIC -785.485
Sample: 01-01-2000 HQIC -799.863
- 04-01-2019
Covariance Type: opg
==============================================================================
coef std err z P>|z| [0.025 0.975]
------------------------------------------------------------------------------
ar.L1 1.8312 0.078 23.456 0.000 1.678 1.984
ar.L2 -1.7993 0.080 -22.546 0.000 -1.956 -1.643
ar.L3 0.8285 0.066 12.556 0.000 0.699 0.958
ma.L1 -1.9453 0.078 -25.071 0.000 -2.097 -1.793
ma.L2 1.8455 0.112 16.538 0.000 1.627 2.064
ma.L3 -0.8616 0.061 -14.227 0.000 -0.980 -0.743
sigma2 0.0016 0.000 10.728 0.000 0.001 0.002
===================================================================================
Ljung-Box (L1) (Q): 0.27 Jarque-Bera (JB): 2.15
Prob(Q): 0.60 Prob(JB): 0.34
Heteroskedasticity (H): 1.61 Skew: 0.19
Prob(H) (two-sided): 0.04 Kurtosis: 3.27
===================================================================================
Warnings:
[1] Covariance matrix calculated using the outer product of gradients (complex-step).
Ajuste y pronóstico en la serie original#
fitted_values = results.fittedvalues
y_pred_train = np.power((lambda_bc * fitted_values + 1), 1 / lambda_bc)
y_pred = y_pred_train[1:]
y_real = precio_electricidad["Precio"][1:split]
resultados = analizar_ajuste_serie(
precio_electricidad, # Serie original (sin transformar)
fitted_values, # Ajuste en train
results, # Modelo ajustado
test, # Datos test
n_forecast=12, # Periodos futuros
transformacion='boxcox', # 'log', 'boxcox', 'sqrt' o None
lambda_bc=lambda_bc, # Solo si es boxcox
nombre="Precio de electricidad"
)
### Gráfico de valores predichos vs. valores reales
plt.figure(figsize=(6,6))
plt.scatter(y_real, y_pred, color='blue', alpha=0.6, edgecolor='k')
# Línea de identidad (y = x)
min_val = min(y_real.min(), y_pred.min())
max_val = max(y_real.max(), y_pred.max())
plt.plot([min_val, max_val], [min_val, max_val], color='black', lw=2)
plt.title("Valores predichos vs. valores reales", fontsize=12)
plt.xlabel("Valores reales")
plt.ylabel("Valores predichos")
plt.axis("equal") # asegura proporciones iguales para la diagonal
plt.grid(alpha=0.3)
plt.tight_layout()
plt.show()
Análisis de los residuales#
analisis_residuales(
results.resid, # Agregar los residuales
nombre="Precio de electricidad",
)