Ejemplo DBSCAN precio electricidad#
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.preprocessing import StandardScaler
from sklearn.cluster import DBSCAN
from sklearn.metrics import silhouette_score
import seaborn as sns
# Cargar los datos omitiendo la primera fila como encabezado y asignando nombres a las columnas
data_precio = pd.read_csv(
"promedios_mensuales_2024.csv", skiprows=1, header=None, names=["Fecha", "Precio"]
)
# Convertir la columna 'Fecha' a datetime
data_precio["Fecha"] = pd.to_datetime(data_precio["Fecha"], format="%Y-%m")
# Set 'Fecha' as the index
data_precio.set_index("Fecha", inplace=True)
plt.figure(figsize=(20, 5))
plt.plot(data_precio.index, data_precio["Precio"], label="Precio", color="blue")
plt.title("Precio electricidad mensual") # Título del gráfico
plt.xlabel("Tiempo") # Etiqueta del eje X
plt.ylabel("Precio") # Etiqueta del eje Y
plt.legend() # Añadir leyenda para identificar las líneas
plt.show()
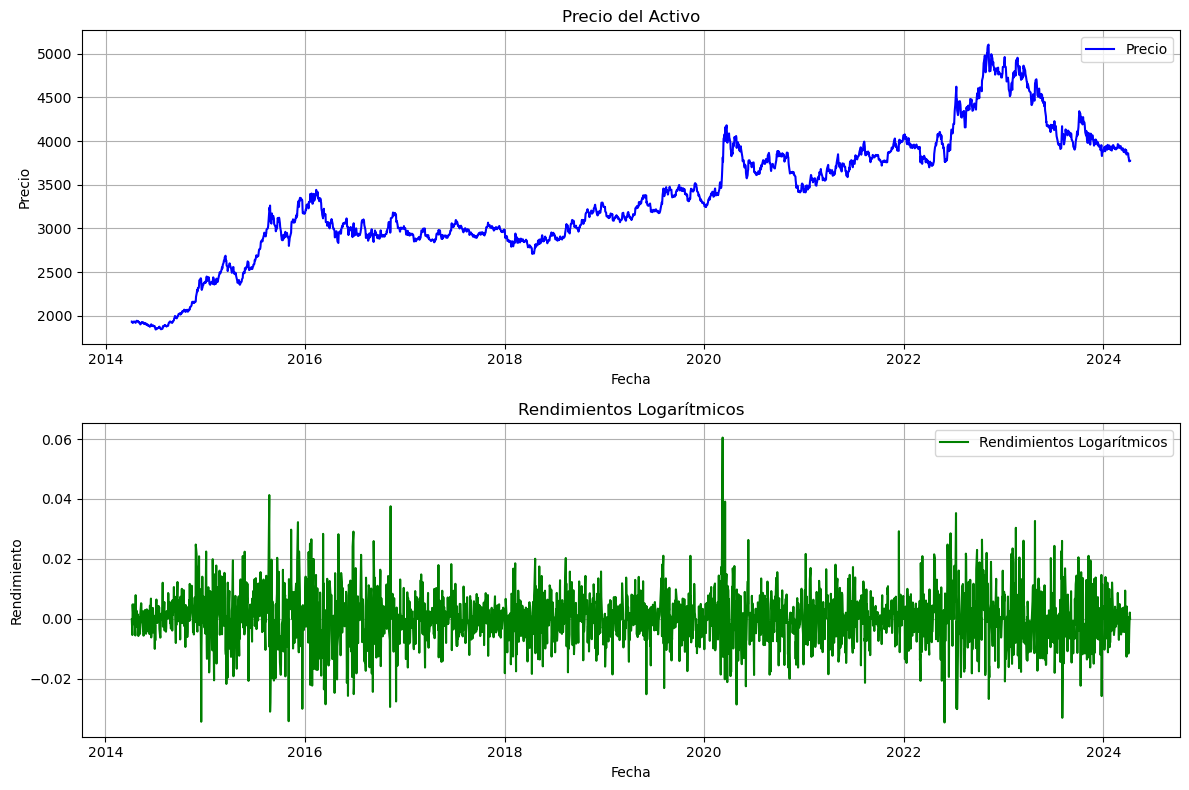
Rendimientos:
# Calcular los rendimientos (diferencias en los precios)
returns = np.diff(data_precio["Precio"])
# Escalar los rendimientos
scaler = StandardScaler()
returns_scaled = scaler.fit_transform(returns.reshape(-1, 1))
# Visualizar los rendimientos
plt.figure(figsize=(14, 7))
plt.plot(returns, label="Rendimientos")
plt.xlabel("Tiempo")
plt.ylabel("Rendimientos")
plt.title("Rendimientos")
plt.legend()
plt.show()

Ajuste modelo DBSCAN:
# Aplicar DBSCAN para identificar saltos
db = DBSCAN(eps=1, min_samples=5)
db_labels = db.fit_predict(returns_scaled)
# Identificar los índices de los saltos
jump_points = np.where(db_labels == -1)[0]
print("Cantidad de saltos identificados:", len(jump_points))
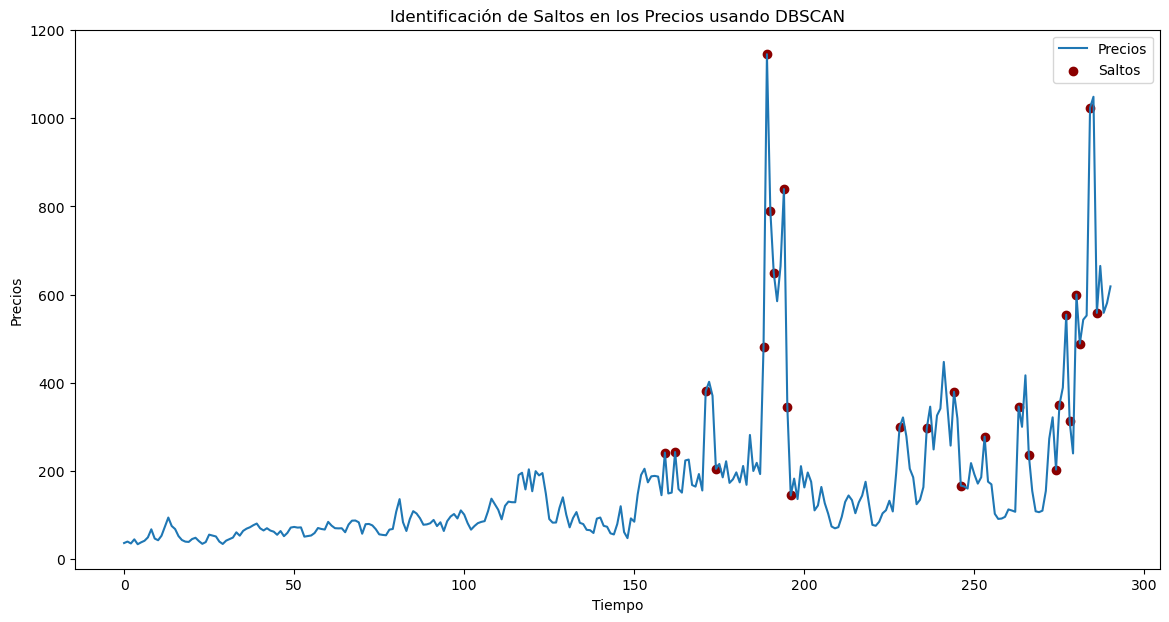
# Visualizar los precios y los saltos identificados
plt.figure(figsize=(14, 7))
plt.plot(data_precio["Precio"].values, label="Precios")
plt.scatter(
jump_points + 1,
data_precio["Precio"][
jump_points + 1
], # +1 para compensar la diferencia de rendimientos
color="darkred",
label="Saltos",
marker="o",
)
plt.xlabel("Tiempo")
plt.ylabel("Precios")
plt.title("Identificación de Saltos en los Precios usando DBSCAN")
plt.legend()
plt.show()
Cantidad de saltos identificados: 6
Determinar los valores de eps y min_samples:#
# Definir los valores de eps y min_samples para evaluar
eps_values = np.arange(0.1, 2, 0.1)
min_samples_values = range(1, 20, 2)
# Almacenar las puntuaciones de silueta
results = []
for eps in eps_values:
for min_samples in min_samples_values:
db = DBSCAN(eps=eps, min_samples=min_samples)
dbscan_labels = db.fit_predict(returns_scaled)
if len(set(dbscan_labels)) > 1: # Asegurarse de que hay más de un cluster
silhouette_avg = silhouette_score(returns_scaled, dbscan_labels)
results.append((eps, min_samples, silhouette_avg))
else:
results.append((eps, min_samples, -1))
# Convertir los resultados a un DataFrame
import pandas as pd
results_df = pd.DataFrame(results, columns=["eps", "min_samples", "silhouette_score"])
# Visualizar los resultados en un heatmap
pivot_table = results_df.pivot(index='eps', columns='min_samples', values='silhouette_score')
plt.figure(figsize=(10, 7))
sns.heatmap(pivot_table, annot=True, fmt=".4f", cmap="viridis")
plt.title("Puntuación de Silueta para diferentes combinaciones de eps y min_samples")
plt.show()
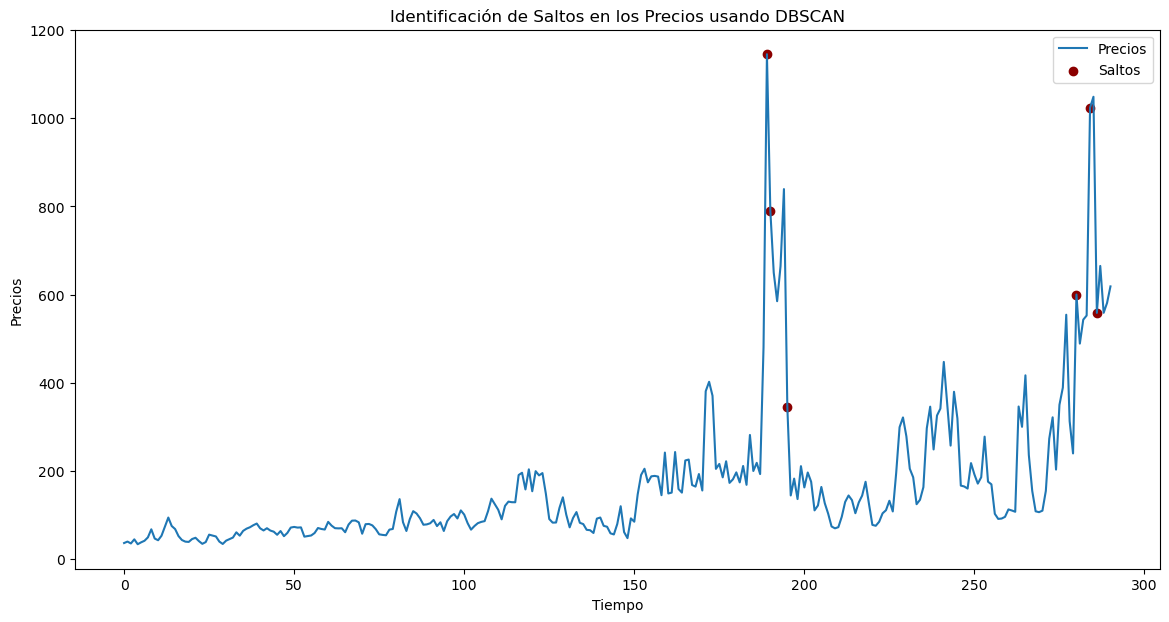
Ajuste del mejor modelo:#
Nota:
El objetivo es identificar los datos atípicos y no los clusters. Por lo tanto, se busca que el modelo no agrupe la totalidad de los datos, sino que deje algunos sin agrupar. Es decir, se seleccionan los peores ajustes porque contendrán la mayor cantidad de datos atípicos.
Se seleccionan los modelos con los peores valores de la puntuación de la Silueta.
eps = 0.1
min_samples = 5
# Aplicar DBSCAN para identificar saltos
db = DBSCAN(eps=eps, min_samples=min_samples)
db_labels = db.fit_predict(returns_scaled)
# Identificar los índices de los saltos
jump_points = np.where(db_labels == -1)[0]
print("Cantidad de saltos identificados:", len(jump_points))
# Visualizar los precios y los saltos identificados
plt.figure(figsize=(14, 7))
plt.plot(data_precio["Precio"].values, label="Precios")
plt.scatter(
jump_points + 1,
data_precio["Precio"][
jump_points + 1
], # +1 para compensar la diferencia de rendimientos
color="darkred",
label="Saltos",
marker="o",
)
plt.xlabel("Tiempo")
plt.ylabel("Precios")
plt.title("Identificación de Saltos en los Precios usando DBSCAN")
plt.legend()
plt.show()
Cantidad de saltos identificados: 26