K-Means#
K-Means es un algoritmo de clustering popular en aprendizaje no supervisado. Su objetivo es dividir un conjunto de datos en \(K\) clústeres predefinidos, donde cada punto de datos pertenece al clúster con el centroide más cercano.
Este método agrupa los datos en \(K\) número de grupos o clústeres en un espacio de muestra dado. Las similitudes de los datos en un clúster se miden en términos de distancia de los puntos desde el centro de la agrupación. El centro del clúster se conoce como centroide. Generalmente, antes de aplicar este método, se asigna el valor de \(K\) y el algoritmo K-Means intenta minimizar la suma de las distancias entre los puntos de datos y el centroide del grupo al que pertenecen.
En el agrupamiento de K-Means, cada grupo está representado por su centro (es decir, centroide) que corresponde a la media de los puntos asignados al grupo.
La distancia de cada punto al centroide se mide generalmente usando la distancia euclidiana. La fórmula para la distancia euclidiana en un espacio n-dimensional es:
donde:
\(d(x, c)\) es la distancia entre el punto \(x\) y el centroide \(c\).
\(x_i\) es la coordenada del punto \(x_i\) en la dimensión \(i\).
\(c_i\) es la coordenada del centroide \(c_i\) en la dimensión \(i\).
\(n\): cantidad de observaciones.
Pasos en el K-Means:#
Iniciar el modelo con un número de \(k\) cluters.
Aleatoriamente ubicar los \(k\) centroides entre los puntos de datos.
Calcular los distancias entre todos los puntos de datos con cada centroide y asignar los puntos al centroide más cercano.
Volver a calcular los centroides de los nuevos grupos.
Repetir los pasos 3 y 4 hasta que se cumplan los criterios para parar las iteraciones.
Para terminar y dejar de iterar el modelo se puede aplicar alguno de los siguientes criterios:
Si los nuevos centros de los clusters son iguales a los anteriores.
Si los puntos de datos de los clusters siguen siendo los mismos.
Cuando se alcanza el número máximo de iteraciones. Este criterio lo define el analista.
Ejemplo:
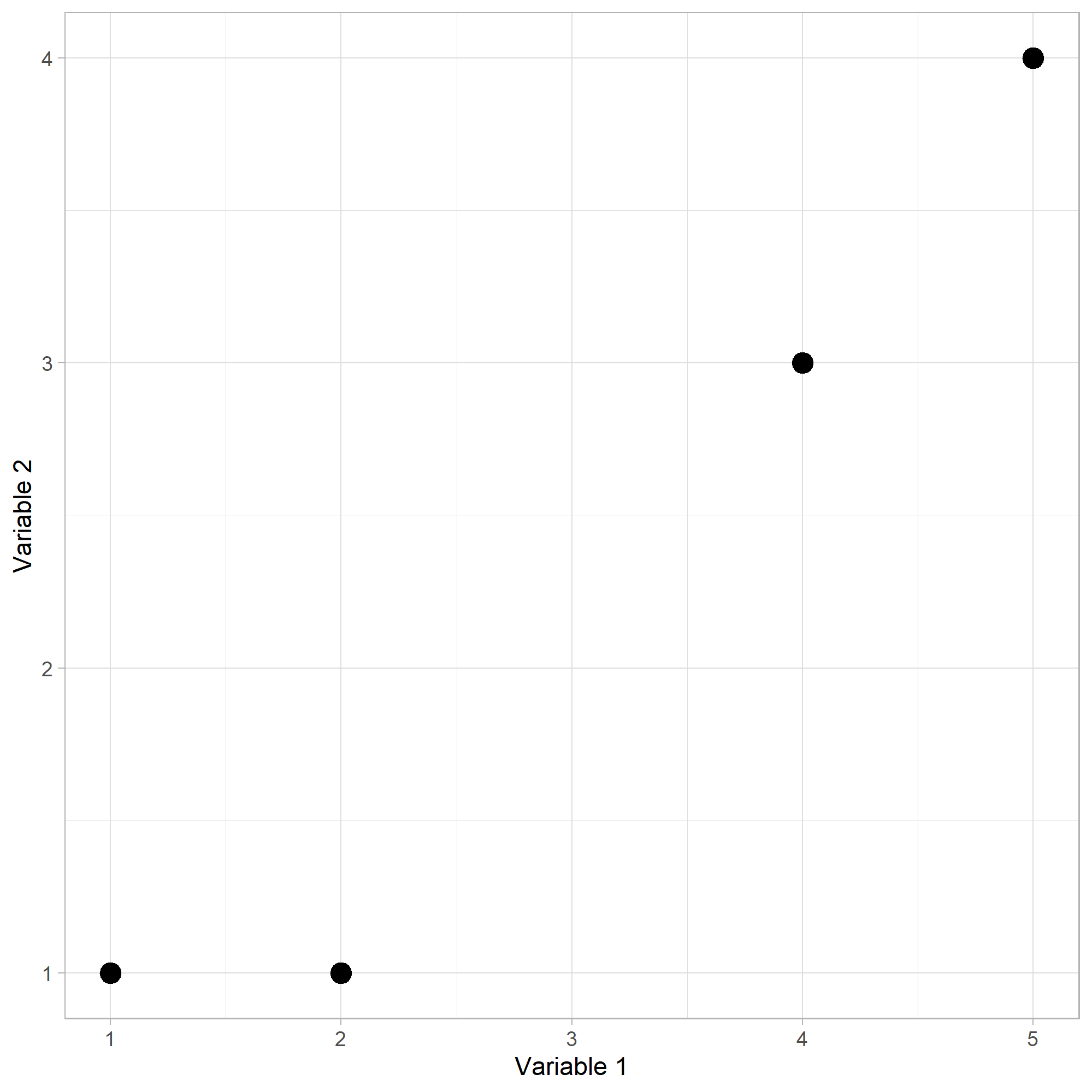
Puntos#
La anterior figura se representa por la siguiente matriz:
Tenemos \(n = 4\) individuos u observaciones y cada uno con \(p = 2\) variables.
Iteración # 1:
Para \(k=2\) clusters, se inicializarán aleatoriamente. Supongamos que el centroide 1 se ubica en \(C1 = (1,1)\) y el centroide 2 en \(C2 = (2,1)\). La siguiente figura muestra los puntos con los dos centroides.
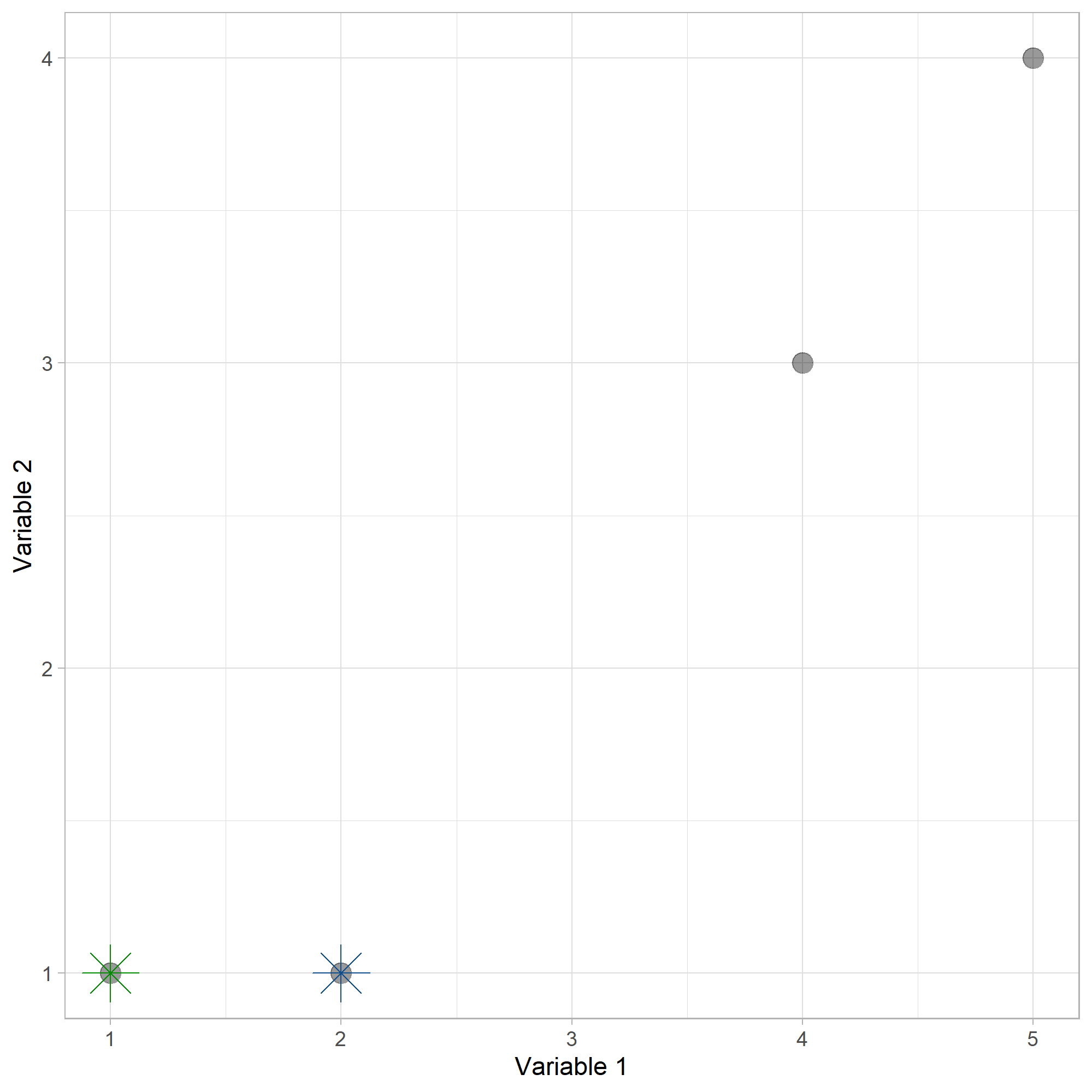
Centroides#
Distancias de todos los puntos al centroide 1 \(C1 = (1,1)\)
\(D1:\sqrt{(1-1)^2+(1-1)^2}=0\)
\(D2:\sqrt{(2-1)^2+(1-1)^2}=1\)
\(D3:\sqrt{(4-1)^2+(3-1)^2}=3,61\)
\(D4:\sqrt{(5-1)^2+(4-1)^2}=5\)
Distancias de todos los puntos al centroide 2 \(C2 = (2,1)\)
\(D1:\sqrt{(1-2)^2+(1-1)^2}=1\)
\(D2:\sqrt{(2-2)^2+(1-1)^2}=0\)
\(D3:\sqrt{(4-2)^2+(3-1)^2}=2,83\)
\(D4:\sqrt{(5-2)^2+(4-1)^2}=4,24\)
Resumiendo:
Con el criterio de asignar el centroide más cercano a cada punto, solo el punto (1,1) pertenece a C1, los demás puntos pertenecen a C2.
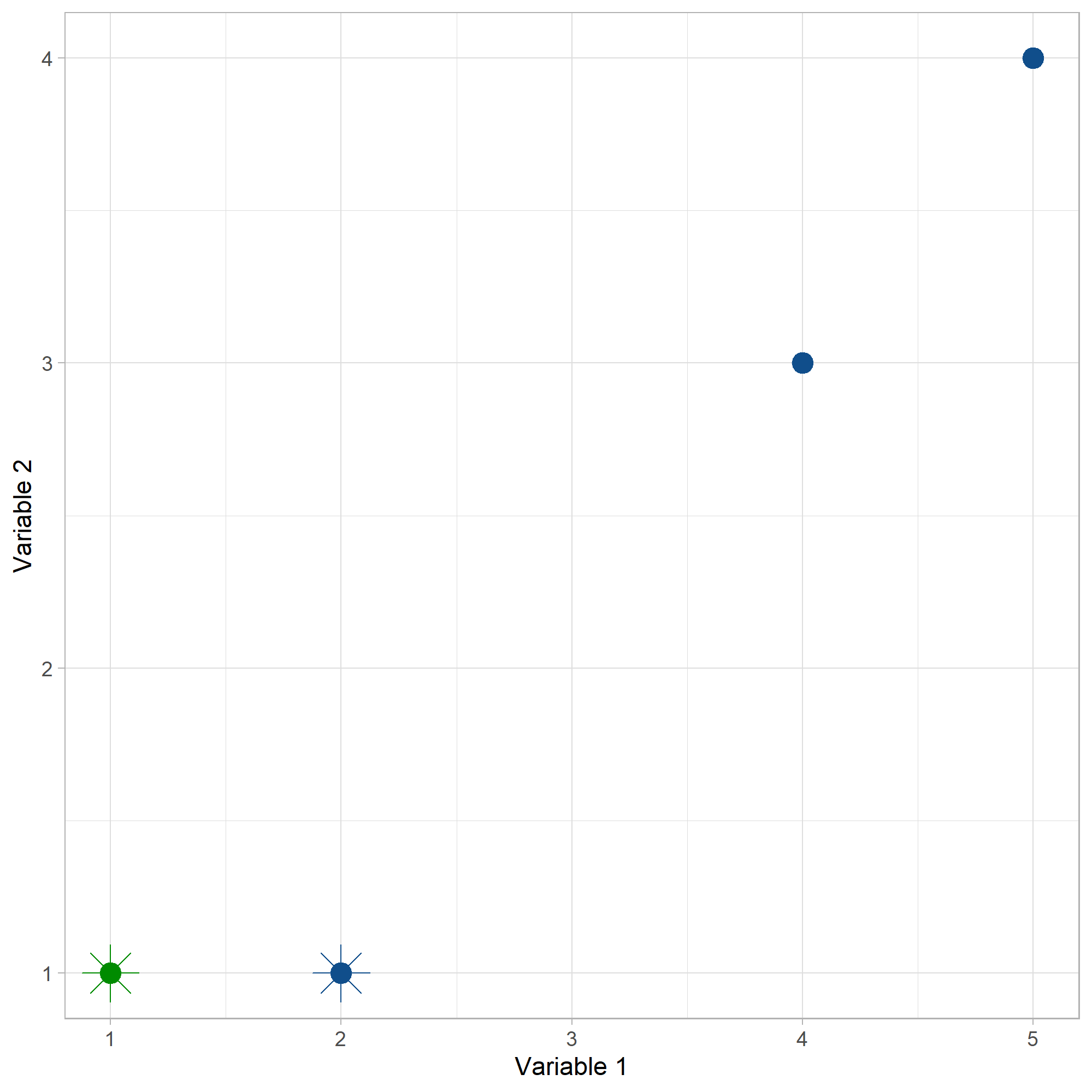
Iteracion1#
Iteración # 2:
Luego, se determinan los nuevos centroides. Como el cluster 1 solo tiene un solo individuo, el centroide 1 sigue siendo el mismo. Para el cluster 2, el nuevo centroide se calcula como la media (means) de los puntos así:
El centroide 2 cambia de posición al punto \(C2 = (3,67; 2,67)\)
Nuevamente, la matriz de distancias sería:
Con el criterio de la mínima distancia al centroide, ahora los puntos (1,1) y (2,1) pertenecen al cluster 1 y los puntos (4,3) y (5,4) pertenecen al cluster 2.
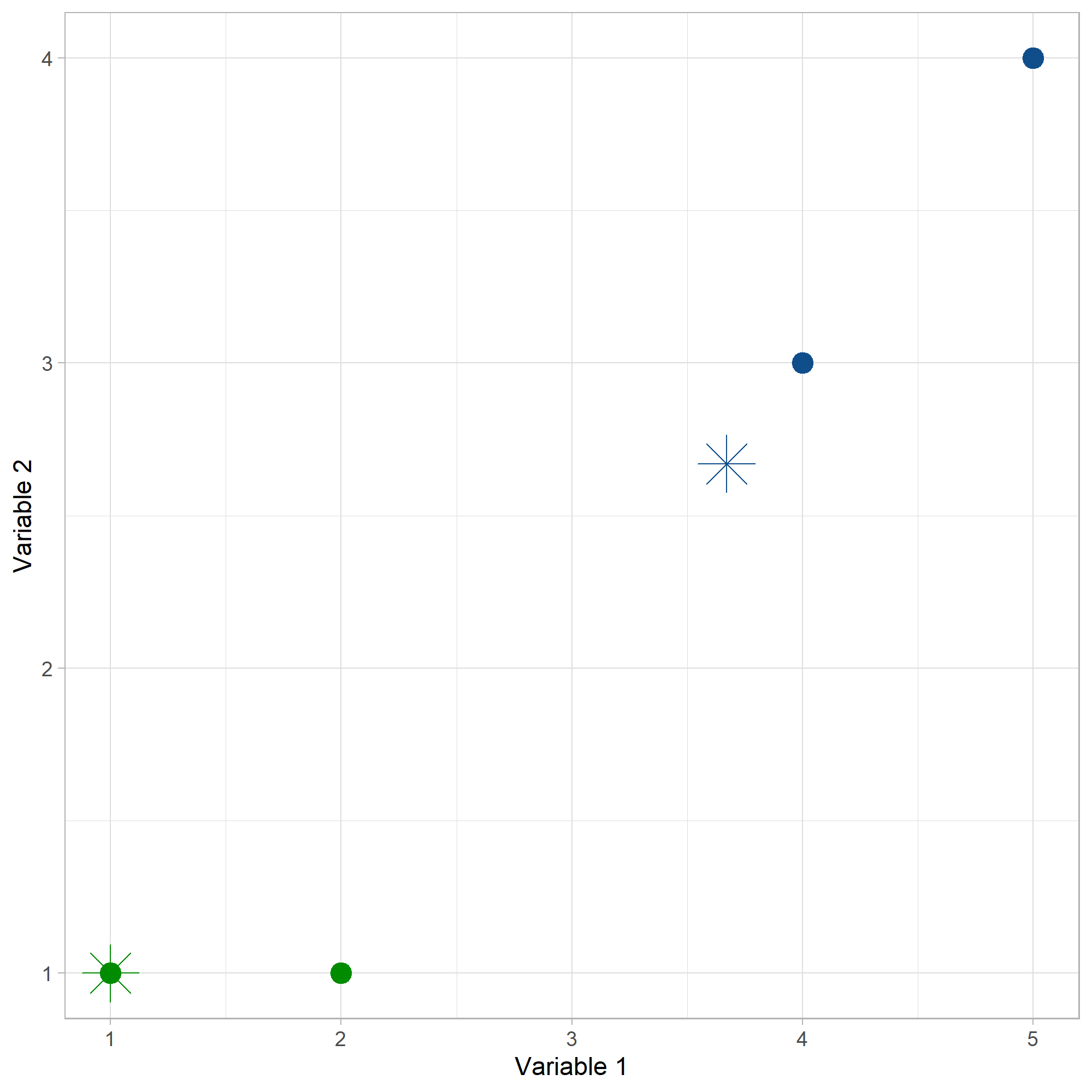
Iteracion2#
Iteración # 3:
Los dos nuevos centroides serán:
Para estos nuevos centroides la matriz de distancias es:
Nuevamente con el criterio de distancia mínima a los centroides, los puntos (1,1) y (2,1) siguen perteneciendo al cluster 1 y los puntos (4,3) y (5,4) al cluster 2. Como no hay cambios en los individuos en los clusters, por tanto, el algoritmo K-Means converge en este punto.
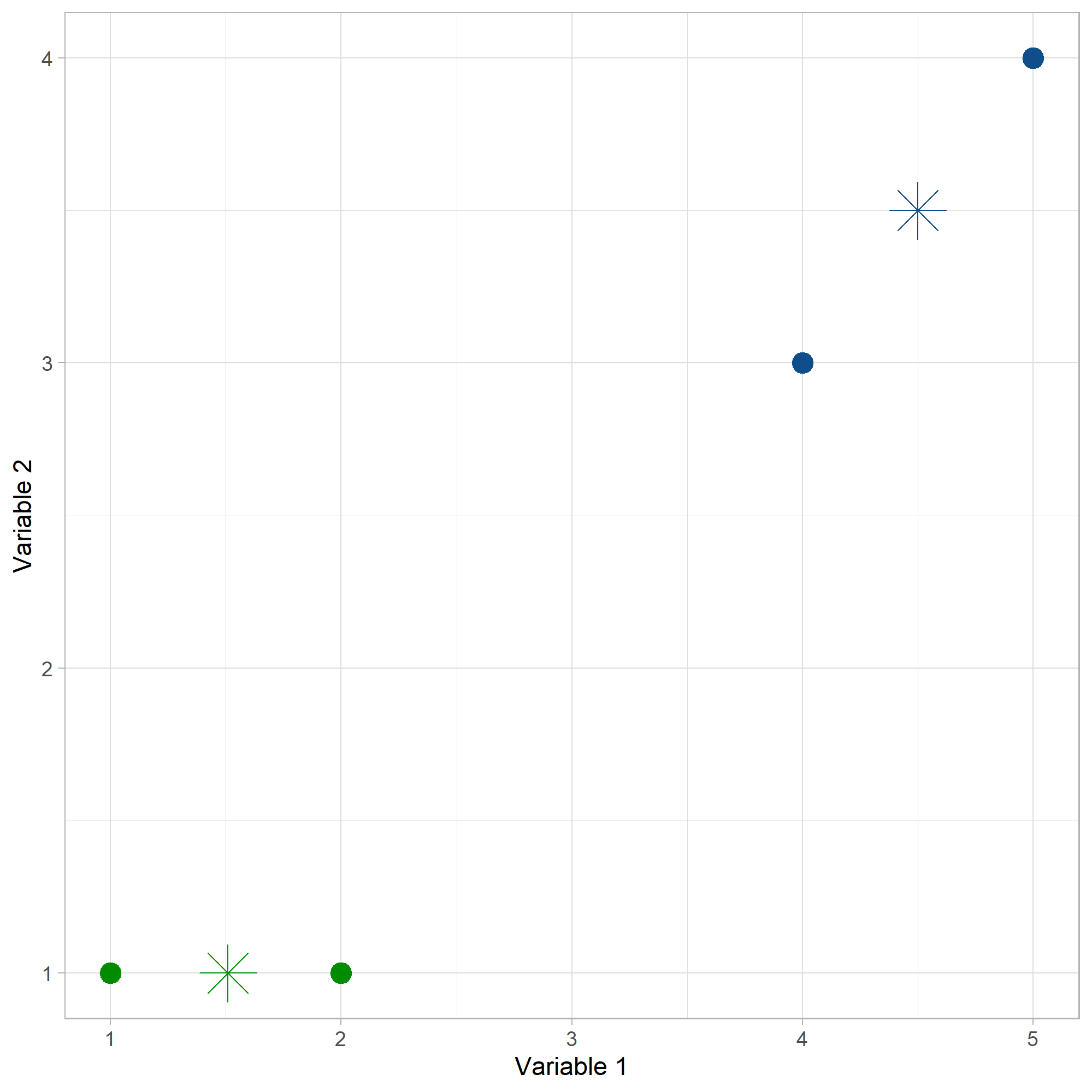
Iteracion3#
Resultado:
La clasificación queda de la siguiente manera:
Individuos |
Variable 1 |
Variable 2 |
Cluster |
|---|---|---|---|
Individuo 1 |
1 |
1 |
1 |
Individuo 2 |
2 |
1 |
1 |
Individuo 3 |
4 |
3 |
2 |
Individuo 4 |
5 |
4 |
2 |
Distancias:#
Veremos las distancias Euclidiana, Manhattan y Minkowsky.
Tenemos \(n\) individuos u observaciones y cada uno con \(p\) variables.
Un individuo será el vector: \(x_i = \begin{bmatrix} x_{i1}, & x_{i2}, & x_{i3} & ..., & x_{ip} \end{bmatrix}\)
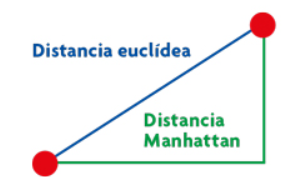
Distancia Euclidiana:#
La distancia euclidiana es la raíz cuadrada de la suma de las diferencias al cuadrado entre las coordenadas correspondientes de dos puntos.
La usamos en el ejemplo anterior y es la única distancia que usa
scikit-learn en sklearn.cluster.
donde:
\(d(x, c)\) es la distancia entre el punto \(x\) y el centroide \(c\).
\(x_i\) es la coordenada del punto \(x_i\) en la dimensión \(i\).
\(c_i\) es la coordenada del centroide \(c_i\) en la dimensión \(i\).
\(n\): cantidad de observaciones.
Distancia Manhattan:#
La distancia Manhattan entre el individuo \(x_i\) y el centroide \(c_j\) se calcula con el valor absoluto de la resta entre las filas \(i\) y \(j\). Cada variable del individual \(i\) se resta con las de individuo \(j\), la sumatoria de estas restas en valor absoluto es el cálculo de la distancia Manhattan.
Distancias#
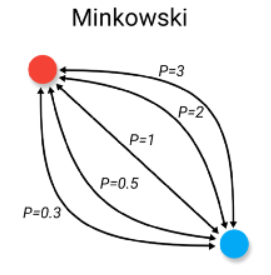
Distancia Minkowski:#
La distancia de Minkowski es una métrica de distancia que generaliza tanto la distancia euclidiana como la distancia de Manhattan, y se define de la siguiente manera:
Si \(p = 1\): Distancia Manhattan.
Si \(p = 2\): Distancia Euclídea.
Minkowski#
Escalamiento de variables:#
El escalamiento de las variables es un paso crucial antes de aplicar algoritmos de clustering como K-Means. El escalamiento asegura que todas las variables contribuyan equitativamente al cálculo de distancias. Las técnicas más comunes para escalar variables son la normalización y la estandarización.
Se recomienda estandarizar o normalizar las variables antes de calcular las distancias, especialmente cuando tenemos grandes diferencias en las unidades de las variables.
En la mayoría de los casos, se recomienda la estandarización, especialmente cuando las variables tienen diferentes unidades o escalas.
Número óptimo de clusters:#
Se emplean técnicas subjetivas.
Determinar el número óptimo de clústeres es un paso crucial en el proceso de clustering. Una de las técnicas más comunes para determinar el número óptimo de clústeres es el método del codo. Este método evalúa la inercia (Within-Cluster Sum of Squares, WCSS) para diferentes valores de \(𝐾\) y busca el punto donde la disminución de la inercia se vuelve menos pronunciada, formando un “codo” (elbow).
El valor máximo de WCSS es cuando solo se hace con un cluster, cuando \(k = 1\).
Donde,
\(P_i\): puntos dentro de un Cluster.
\(C_k\): centroide del Cluster \(k\).
\(n\): cantidad de observaciones.
Se corre el algoritmo para diferentes \(k\) clusters, por ejemplo, variando entre 1 y 10.
Para cada cluster calcular el WCSS.
Trazar una curva de WCSS con el número de clusters \(k\).
La ubicación de la curva (codo) se considera como un indicador apropiado para el agrupamiento.
Método de la silueta (Average silhouette method):#
El método de la silueta es una técnica utilizada para determinar la calidad del clustering y, por lo tanto, para ayudar a identificar el número óptimo de clústeres. La análisis de silueta proporciona una medida de cuán similares son los puntos dentro de un clúster en comparación con los puntos de otros clústeres. La puntuación de la silueta varía de -1 a 1:
Un valor cercano a 1 indica que los puntos están bien agrupados dentro de su clúster y alejados de otros clústeres.
Un valor cercano a 0 indica que los puntos están en el límite o superposición de dos clústeres.
Un valor negativo indica que los puntos pueden estar mal agrupados.
Para calcular la puntuación de la silueta, se utilizan dos valores para cada punto:
\(a(i)\): La distancia promedio entre el punto \(i\) y todos los demás puntos del mismo clúster.
\(b(i)\): La distancia promedio entre el punto \(i\) y todos los puntos del clúster más cercano al que no pertenece.
La puntuación de la silueta para un punto \(i\) se define como:
Desventajas del K-Means:#
El algoritmo K-Means es ampliamente utilizado debido a su simplicidad y eficiencia, pero también tiene varias desventajas y limitaciones que es importante considerar. Aquí se detallan algunas de las principales desventajas del K-Means:
1. Número de Clústeres (K) predefinido:
Requiere que el usuario especifique el número de clústeres \(k\) de antemano. Elegir el valor correcto de \(k\) puede ser complicado y a menudo requiere experimentación y validación.
2. Sensibilidad a la inicialización:
El resultado de K-Means puede depender fuertemente de la selección inicial de los centroides. Una mala inicialización puede llevar a una convergencia a mínimos locales subóptimos.
3. Formas de Clústeres:
Asume que los clústeres tienen una forma esférica y que todos los clústeres tienen aproximadamente el mismo tamaño. No maneja bien clústeres de formas irregulares o de tamaños muy diferentes.
4. Sensibilidad a Outliers:
Es sensible a los valores atípicos (outliers), ya que intenta minimizar la suma de las distancias al cuadrado. Los outliers pueden afectar significativamente la posición de los centroides.
5. Dependencia de la escala de las variables:
Las variables deben estar escaladas antes de aplicar K-Means, ya que las diferencias en las escalas pueden influir en la formación de los clústeres.
6. Asignación forzosa a Clústeres:
Cada punto de datos se asigna obligatoriamente a un clúster, lo que puede no ser adecuado para datos con puntos de datos ambiguos o con ruido significativo.
7. Número fijo de iteraciones:
Puede requerir un número fijo de iteraciones para converger, lo que puede ser computacionalmente costoso para conjuntos de datos grandes.
8. No Garantiza el Óptimo Global:
Puede converger a un mínimo local en lugar de al mínimo global, lo que significa que los resultados pueden no ser óptimos.