Ejercicio K-Means Estados Financieros#
import numpy as np
import pandas as pd
from sklearn.preprocessing import StandardScaler
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_score
import matplotlib.pyplot as plt
import seaborn as sns
# Cargar los datos
data_pymes = pd.read_excel("../210030_Estado de situación financiera, corriente_no corriente_PYMES.xlsx")
data_grandes = pd.read_excel("../210030_Estado de situación financiera, corriente_no corriente.xlsx")
Cantidad de empresas por industria:
# Combinar los datos de PYMES y grandes empresas
combined_data = pd.concat([data_pymes, data_grandes], ignore_index=True)
# Contar la cantidad de empresas por cada CIIU
ciiu_counts = combined_data[
"Clasificación Industrial Internacional Uniforme Versión 4 A.C (CIIU)"
].value_counts()
print(ciiu_counts[:20])
L6810 - Actividades inmobiliarias realizadas con bienes propios o arrendados 7718
F4111 - Construcción de edificios residenciales 2314
F4290 - Construcción de otras obras de ingeniería civil 1908
G4663 - Comercio al por mayor de materiales de construcción, artículos de ferretería, pinturas, productos de vidrio, equipo y materiales de fontanería y calefacción 1088
K6499 - Otras actividades de servicio financiero, excepto las de seguros y pensiones n.c.p. 976
G4731 - Comercio al por menor de combustible para automotores 902
G4530 - Comercio de partes, piezas (autopartes) y accesorios (lujos) para vehículos automotores 872
M7112 - Actividades de ingeniería y otras actividades conexas de consultoría técnica 860
G4659 - Comercio al por mayor de otros tipos de maquinaria y equipo n.c.p. 838
G4645 - Comercio al por mayor de productos farmacéuticos, medicinales, cosméticos y de tocador 814
G4631 - Comercio al por mayor de productos alimenticios 800
M7010 - Actividades de administración empresarial 714
M7020 - Actividades de consultoría de gestión 702
G4690 - Comercio al por mayor no especializado 690
A0141 - Cría de ganado bovino y bufalino 666
N8299 - Otras actividades de servicio de apoyo a las empresas n.c.p. 644
C1410 - Confección de prendas de vestir, excepto prendas de piel 632
L6820 - Actividades inmobiliarias realizadas a cambio de una retribución o por contrata 622
K6613 - Otras actividades relacionadas con el mercado de valores 596
G4664 - Comercio al por mayor de productos químicos básicos, cauchos y plásticos en formas primarias y productos químicos de uso agropecuario 592
Name: Clasificación Industrial Internacional Uniforme Versión 4 A.C (CIIU), dtype: int64
G4631 - Comercio al por mayor de productos alimenticios:#
# Función para filtrar, calcular indicadores y eliminar outliers
def filtrar_y_calcular(data, ciiu):
filtered_data = data[(data["Clasificación Industrial Internacional Uniforme Versión 4 A.C (CIIU)"]
== ciiu) & (data["Periodo"] == "Periodo Actual")].copy()
# Calcular los indicadores de liquidez y endeudamiento utilizando los nombres exactos de las columnas
filtered_data.loc[:, "Liquidez"] = (filtered_data["Activos corrientes totales (CurrentAssets)"]
/ filtered_data["Pasivos corrientes totales (CurrentLiabilities)"])
filtered_data.loc[:, "Endeudamiento"] = (filtered_data["Total pasivos (Liabilities)"]
/ filtered_data["Total de activos (Assets)"])
filtered_data.loc[:, "UtilidadesAcumuladas"] = filtered_data["Ganancias acumuladas (RetainedEarnings)"]
filtered_data.replace([np.inf, -np.inf], np.nan, inplace=True)
variables = ["Liquidez", "Endeudamiento", "UtilidadesAcumuladas"]
filtered_data = filtered_data[variables].dropna().copy()
# Identificar y eliminar valores atípicos usando el IQR
numeric_cols = filtered_data.select_dtypes(include=[np.number]).columns
Q1 = filtered_data[numeric_cols].quantile(0.25)
Q3 = filtered_data[numeric_cols].quantile(0.75)
IQR = Q3 - Q1
lower_bound = Q1 - 1.5 * IQR
upper_bound = Q3 + 1.5 * IQR
filtered_data = filtered_data[~((filtered_data[numeric_cols] < lower_bound) | (filtered_data[numeric_cols] > upper_bound)).any(axis=1)]
return filtered_data
# Filtrar y calcular indicadores
CIIU = "G4631 - Comercio al por mayor de productos alimenticios"
data_pymes_filtered = filtrar_y_calcular(data_pymes, CIIU)
data_grandes_filtered = filtrar_y_calcular(data_grandes, CIIU)
# Agregar etiquetas
data_pymes_filtered["Tipo"] = "Pyme"
data_grandes_filtered["Tipo"] = "Grande"
# Unir los datos
combined_data = pd.concat(
[data_pymes_filtered, data_grandes_filtered], ignore_index=True
)
print("Industria: ", CIIU)
print("Cantidad empresas grandes: ", data_grandes_filtered.shape[0])
print("Cantidad empresas pymes: ", data_pymes_filtered.shape[0])
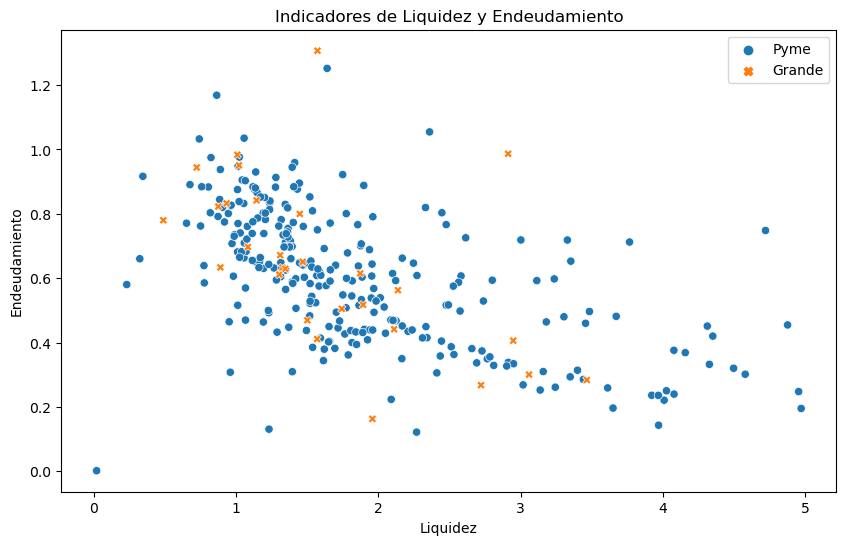
# Graficar los resultados en 2D
plt.figure(figsize=(10, 6))
sns.scatterplot(
data=combined_data, x="Liquidez", y="Endeudamiento", hue="Tipo", style="Tipo"
)
plt.title("Indicadores de Liquidez y Endeudamiento")
plt.xlabel("Liquidez")
plt.ylabel("Endeudamiento")
plt.legend()
plt.show()
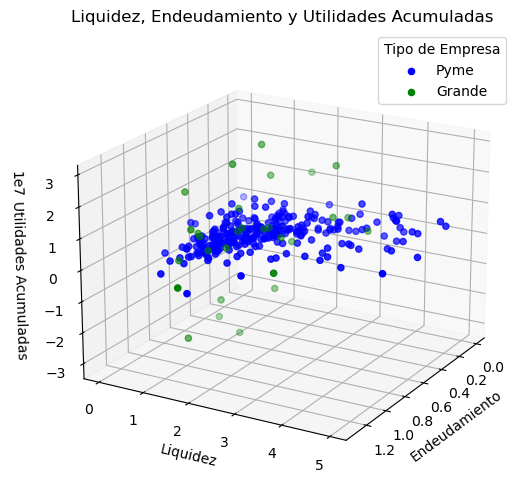
# Graficar los resultados en 3D
fig = plt.figure(figsize=(12, 6))
ax1 = fig.add_subplot(projection="3d")
# Filtrar los datos por tipo de empresa para graficar con colores diferentes
pymes = combined_data[combined_data["Tipo"] == "Pyme"]
grandes = combined_data[combined_data["Tipo"] == "Grande"]
# Graficar puntos para cada tipo
ax1.scatter(
pymes["Endeudamiento"],
pymes["Liquidez"],
pymes["UtilidadesAcumuladas"],
color="blue",
label="Pyme",
)
ax1.scatter(
grandes["Endeudamiento"],
grandes["Liquidez"],
grandes["UtilidadesAcumuladas"],
color="green",
label="Grande",
)
# Ajustes adicionales de la gráfica
ax1.set_xlabel("Endeudamiento")
ax1.set_ylabel("Liquidez")
ax1.set_zlabel("Utilidades Acumuladas")
ax1.set_title("Liquidez, Endeudamiento y Utilidades Acumuladas")
ax1.view_init(elev=20, azim=30)
# Crear leyenda
ax1.legend(title="Tipo de Empresa")
plt.show()
print(combined_data.head())
Industria: G4631 - Comercio al por mayor de productos alimenticios
Cantidad empresas grandes: 29
Cantidad empresas pymes: 282
Liquidez Endeudamiento UtilidadesAcumuladas Tipo
0 1.236270 0.833611 554338.0 Pyme
1 1.386163 0.660544 2181803.0 Pyme
2 1.366260 0.754717 9824698.0 Pyme
3 1.532488 0.543482 793405.0 Pyme
4 1.012583 0.515712 3113417.0 Pyme
df = combined_data.iloc[:, :-1]
# Escalar los datos
scaler = StandardScaler()
df_scaled = scaler.fit_transform(df)
wcss = []
silhouette_scores = []
K = range(2, 11)
for k in K:
kmeans = KMeans(n_clusters=k, random_state=34)
kmeans.fit(df_scaled)
wcss.append(kmeans.inertia_)
labels = kmeans.labels_
score = silhouette_score(df_scaled, labels)
silhouette_scores.append(score)
# Visualizar los resultados del método del codo y de la silueta
plt.figure(figsize=(16, 6))
plt.subplot(1, 2, 1)
plt.plot(K, wcss, "bo-")
plt.xlabel("Número de clústeres (K)")
plt.ylabel("WCSS")
plt.title("Método del Codo para determinar el número óptimo de clústeres")
plt.subplot(1, 2, 2)
plt.plot(K, silhouette_scores, "bo-")
plt.xlabel("Número de clústeres (K)")
plt.ylabel("Puntuación de la Silueta")
plt.title("Método de la Silueta para determinar el número óptimo de clústeres")
plt.tight_layout()
plt.show()
Ajuste del modelo K = 5
k = 5
kmeans = KMeans(n_clusters=k, random_state=34)
kmeans.fit(df_scaled)
df["cluster"] = kmeans.labels_
# Visualizar los clústeres del mejor modelo en 3D
fig = plt.figure(figsize=(10, 8))
ax = fig.add_subplot(111, projection="3d")
scatter = ax.scatter(
df["Liquidez"],
df["Endeudamiento"],
df["UtilidadesAcumuladas"],
c=df["cluster"],
cmap="viridis",
s=80,
edgecolors="w",
)
ax.set_title(f"Mejor modelo K-Means con K={k}")
ax.set_xlabel("Liquidez")
ax.set_ylabel("Endeudamiento")
ax.set_zlabel("Utilidades Acumuladas")
ax.view_init(elev=20, azim=30)
fig.tight_layout()
plt.show()