XGBoost#
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
import xgboost as xgb
from sklearn.metrics import classification_report, confusion_matrix
import yfinance as yf
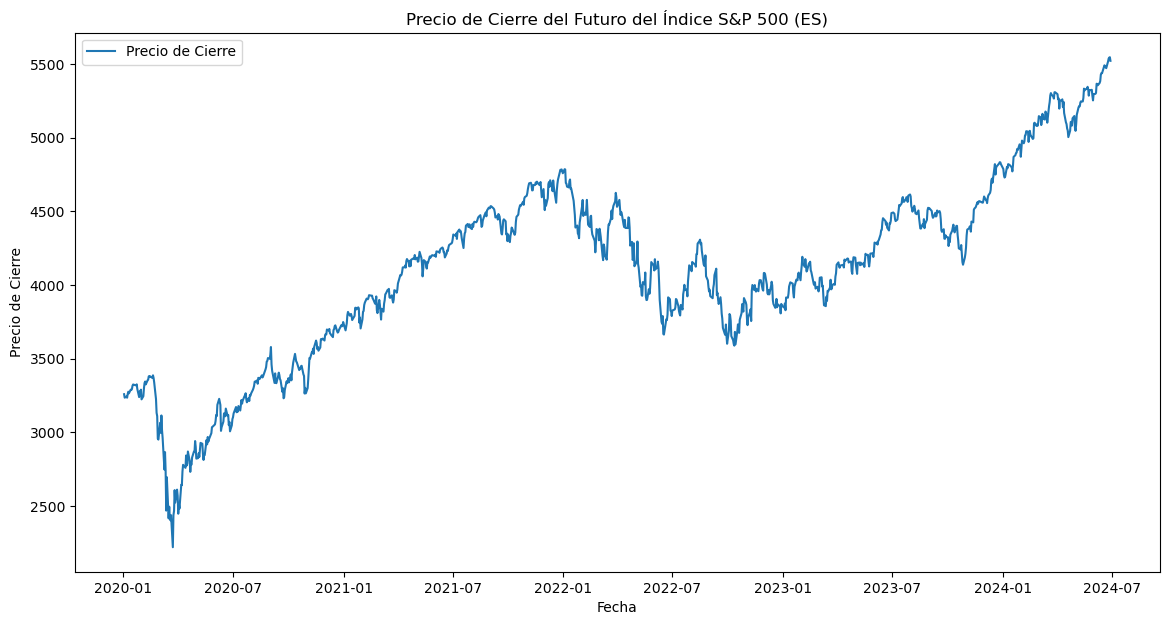
Descargar precios del Futuro ES:#
# Descargar datos históricos del futuro del índice S&P 500 (ES)
ticker = "ES=F"
data = yf.download(ticker, start="2020-01-01", end="2024-06-30", interval="1d")
# Graficar el precio de cierre
plt.figure(figsize=(14, 7))
plt.plot(data["Close"], label="Precio de Cierre")
plt.title("Precio de Cierre del Futuro del Índice S&P 500 (ES)")
plt.xlabel("Fecha")
plt.ylabel("Precio de Cierre")
plt.legend()
plt.show()
[*******************100%*********************] 1 of 1 completed
Creación de las características:#
# Crear características adicionales
data["PriceChange"] = data["Close"].shift(-1) - data["Close"]
data["Label"] = np.where(data["PriceChange"] > 0, 1, 0)
data["DailyPctChange"] = ((data["Close"] - data["Open"]) / data["Open"]) * 100
data["Range"] = data["High"] - data["Low"]
data["Volatility"] = (data["High"] - data["Low"]) / data["Close"]
# Seleccionar características y etiqueta
features = [
"Open",
"High",
"Low",
"Close",
"Volume",
"Volatility",
"DailyPctChange",
"Range",
]
X = data[features]
y = data["Label"]
print("Cantidad precios positivos y negativos:\n", data["Label"].value_counts())
print(X.head())
Cantidad precios positivos y negativos:
1 602
0 529
Name: Label, dtype: int64
Open High Low Close Volume Volatility Date
2020-01-02 3237.00 3261.75 3234.25 3259.00 1416241 0.008438
2020-01-03 3261.00 3263.50 3206.75 3235.50 1755057 0.017540
2020-01-06 3220.25 3249.50 3208.75 3243.50 1502748 0.012564
2020-01-07 3243.50 3254.50 3226.00 3235.25 1293494 0.008809
2020-01-08 3231.75 3267.75 3181.00 3260.25 2279138 0.026608
DailyPctChange Range
Date
2020-01-02 0.679642 27.50
2020-01-03 -0.781969 56.75
2020-01-06 0.721994 40.75
2020-01-07 -0.254355 28.50
2020-01-08 0.881875 86.75
XGBoost:#
XGBoost (eXtreme Gradient Boosting) es una biblioteca de aprendizaje automático que ha ganado gran popularidad debido a su rendimiento superior y eficiencia. Es una implementación avanzada del algoritmo de Gradient Boosting, diseñada para ser rápida, flexible y precisa. XGBoost se utiliza ampliamente para tareas de clasificación y regresión, y es especialmente eficaz en competiciones de ciencia de datos y problemas del mundo real que requieren modelos de alto rendimiento.
XGBoost incluye regularización \(𝐿_1\) (Lasso) y \(𝐿_2\) (Ridge) de manera nativa, lo que ayuda a evitar el sobreajuste y mejora la capacidad de generalización del modelo.
Soporta una variedad de funciones de pérdida personalizables, lo que permite optimizar diferentes tipos de problemas, como clasificación binaria, clasificación multiclase, regresión y ranking.
Permite ajustar muchos hiperparámetros para optimizar el modelo de acuerdo a las necesidades específicas del problema.
Cómo Funciona XGBoost:#
XGBoost es una implementación de Gradient Boosting que utiliza árboles de decisión como modelos base. A continuación se describen los pasos generales del funcionamiento de XGBoost:
1. Inicialización:
Comienza con un modelo inicial simple, generalmente un modelo constante que predice el valor promedio de la variable objetivo.
2. Iteración secuencial:
En cada iteración, se entrena un nuevo árbol de decisión en los residuos (errores) del modelo actual.
El objetivo es minimizar la función de pérdida, ajustando el nuevo árbol para corregir los errores del modelo acumulado.
3. Optimización del Gradiente:
Calcula el gradiente de la función de pérdida con respecto a las predicciones del modelo y utiliza estos gradientes para ajustar los nuevos árboles.
4. Regularización:
Aplica regularización para evitar el sobreajuste, controlando la complejidad del modelo a través de hiperparámetros como la profundidad máxima de los árboles y el término de penalización.
5. Combinación de modelos:
Los modelos se combinan para formar un predictor fuerte, ponderando cada modelo según su contribución a la reducción de la función de pérdida.
6. Predicción final:
La predicción final es la suma de las predicciones ponderadas de todos los modelos en el conjunto.
# Dividir el conjunto de datos en entrenamiento y prueba
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.3, random_state=34
)
# Crear un clasificador XGBoost
xgb_clf = xgb.XGBClassifier(
n_estimators=100, # Número de árboles en el bosque
max_depth=4, # Profundidad máxima de cada árbol
learning_rate=0.01, # Tasa de aprendizaje
subsample=0.8, # Subconjunto de datos utilizado para cada árbol
colsample_bytree=0.8, # Subconjunto de características utilizado para cada árbol
random_state=34,
)
# Entrenar el clasificador XGBoost
xgb_clf.fit(X_train, y_train)
# Realizar predicciones
y_pred = xgb_clf.predict(X_test)
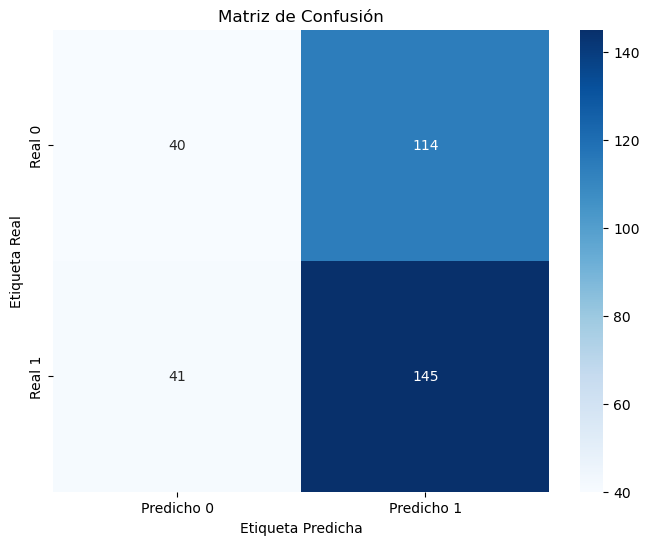
Evaluación del modelo:#
# Calcular las métricas de evaluación
conf_matrix = confusion_matrix(y_test, y_pred)
class_report = classification_report(y_test, y_pred)
# Mostrar las métricas de evaluación
print("Classification Report:\n", class_report)
# Crear un mapa de calor para la matriz de confusión con etiquetas
plt.figure(figsize=(8, 6))
sns.heatmap(
conf_matrix,
annot=True,
fmt="d",
cmap="Blues",
xticklabels=["Predicho 0", "Predicho 1"],
yticklabels=["Real 0", "Real 1"],
)
plt.xlabel("Etiqueta Predicha")
plt.ylabel("Etiqueta Real")
plt.title("Matriz de Confusión")
plt.show()
Classification Report:
precision recall f1-score support
0 0.49 0.26 0.34 154
1 0.56 0.78 0.65 186
accuracy 0.54 340
macro avg 0.53 0.52 0.50 340
weighted avg 0.53 0.54 0.51 340