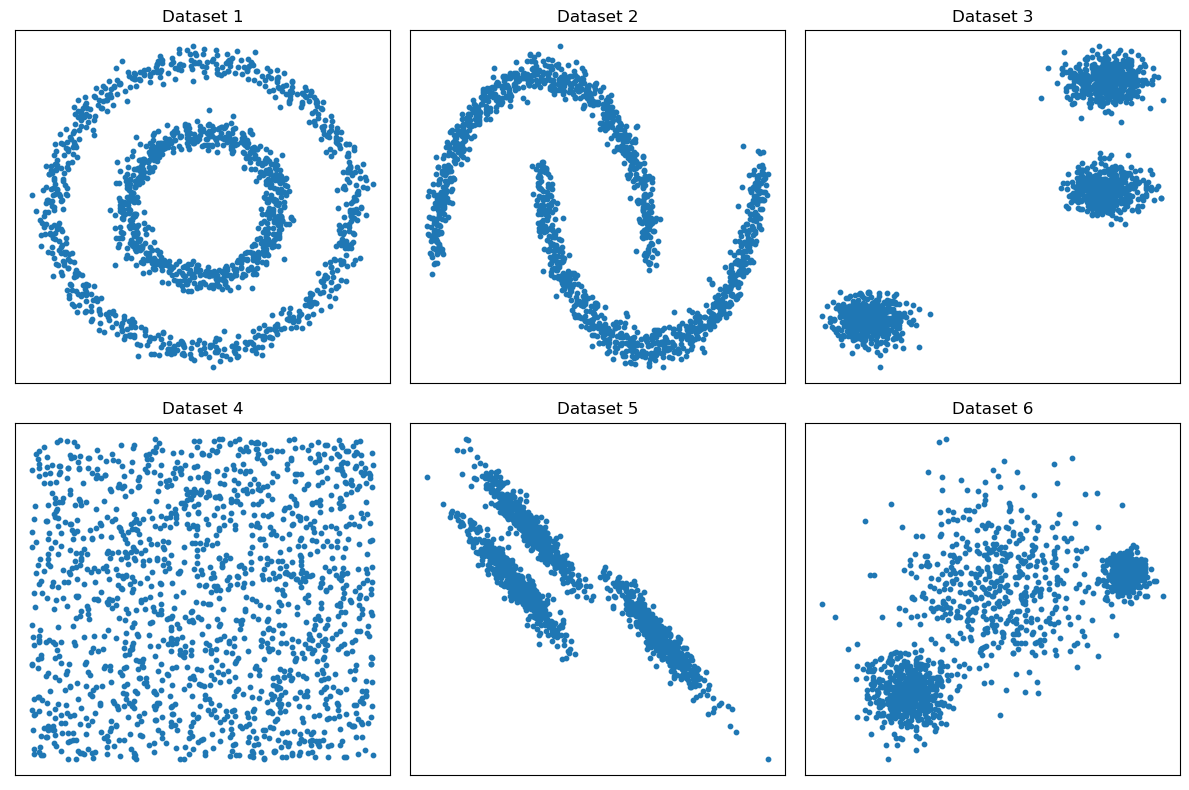
Taller Clustering datos ficticios#
Aplicar los métodos de clustering aprendidos a cada uno de los siguientes conjuntos de datos y determinar visualmente la mejor combinación de clusters.
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs, make_moons, make_circles
# Generar diferentes formas de datos
def generate_datasets():
n_samples = 1500
noisy_circles = make_circles(n_samples=n_samples, factor=.5, noise=.05)
noisy_moons = make_moons(n_samples=n_samples, noise=.05)
blobs = make_blobs(n_samples=n_samples, random_state=8)
no_structure = np.random.rand(n_samples, 2), None
# Anisotropicly distributed data
random_state = 170
X, y = make_blobs(n_samples=n_samples, random_state=random_state)
transformation = [[0.6, -0.6], [-0.4, 0.8]]
X_aniso = np.dot(X, transformation)
# Varying standard deviation of blobs
varied = make_blobs(n_samples=n_samples,
cluster_std=[1.0, 2.5, 0.5],
random_state=random_state)
return [noisy_circles, noisy_moons, blobs, no_structure, (X_aniso, y), varied]
datasets = generate_datasets()
# Definir una función para visualizar los datos
def plot_datasets(datasets):
plt.figure(figsize=(12, 8))
for i, (X, y) in enumerate(datasets):
plt.subplot(2, 3, i + 1)
plt.scatter(X[:, 0], X[:, 1], s=10)
plt.title(f'Dataset {i + 1}')
plt.xticks(())
plt.yticks(())
plt.tight_layout()
plt.show()
# Visualizar los datasets generados
plot_datasets(datasets)