Generalización#
El aprendizaje automático (Machine Learning) enfrenta un desafío fundamental: encontrar un equilibrio entre la optimización y la generalización.
Optimización: Este es el proceso de ajustar el modelo para que logre el mejor desempeño posible en el conjunto de entrenamiento (train). Aquí es donde realmente ocurre el “aprendizaje” del modelo: ajustando sus parámetros para minimizar el error en los datos con los que se ha entrenado.
Generalización: Se refiere a la capacidad del modelo para aplicar lo aprendido a datos nuevos, es decir, a datos que no se utilizaron durante el entrenamiento. El verdadero objetivo del aprendizaje automático es obtener un modelo que generalice bien, lo que significa que puede realizar predicciones precisas en datos no vistos.
Sin embargo, la generalización no se controla directamente; solo podemos ajustar el modelo en el conjunto de entrenamiento. Si el modelo se ajusta demasiado bien a estos datos, puede sufrir de sobreajuste (overfitting), lo que disminuye su capacidad para generalizar.
Zonas de ajuste del modelo:#
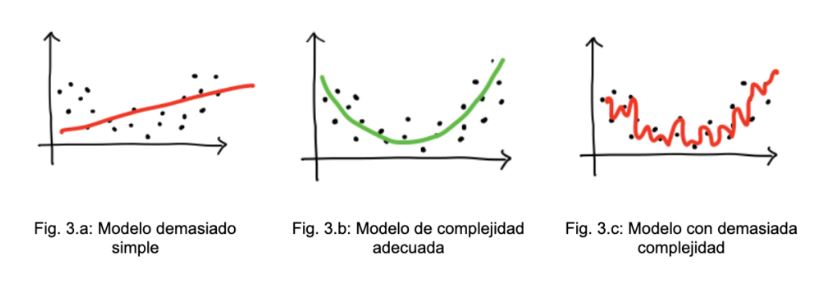
1. Underfitting:
Ocurre cuando el modelo es demasiado simple para captar los patrones subyacentes en los datos. En esta zona, el modelo no se ajusta adecuadamente ni a los datos de entrenamiento ni a los de prueba, indicando que aún hay espacio para mejorar el modelo.
2. Overfitting:
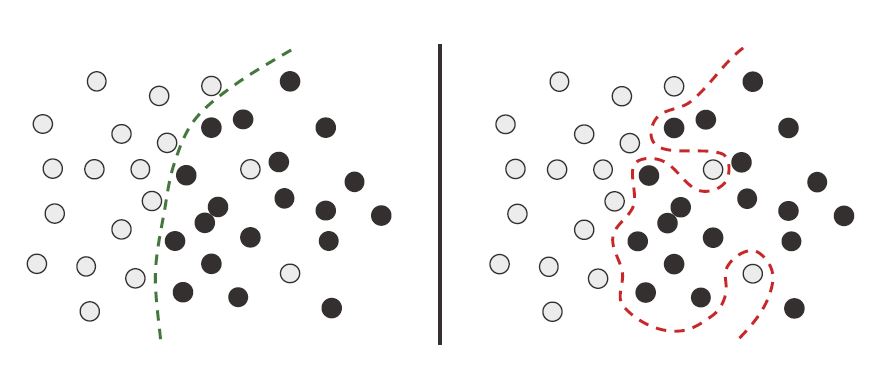
Sucede cuando el modelo es demasiado complejo en relación con la cantidad y la calidad de los datos de entrenamiento. Aunque el modelo puede tener un bajo error en el conjunto de entrenamiento, su rendimiento en el conjunto de validación o prueba comienza a degradarse. Esto indica que el modelo ha comenzado a memorizar los detalles y el ruido de los datos de entrenamiento, en lugar de aprender patrones generalizables.
Factores que contribuyen al sobreajuste:
El sobreajuste es más probable cuando los datos de entrenamiento son ruidosos o contienen variables poco comunes. Un modelo demasiado complejo puede adaptarse a estas irregularidades, lo que lleva a un rendimiento pobre en nuevos datos.
RobustVsOverfitting#
Bias-varianza-2#
Mejora de la generalización:#
Para lograr una buena generalización, el modelo debe entrenarse con una muestra suficientemente representativa y densa del espacio de entrada. Esto significa que el conjunto de entrenamiento debe cubrir adecuadamente la diversidad de los datos que el modelo puede encontrar en el mundo real.
Más y mejores datos: La manera más efectiva de mejorar la generalización de un modelo es entrenarlo con más datos o con datos de mejor calidad. Datos ruidosos o inexactos pueden dañar la capacidad de generalización, mientras que una cobertura más completa y densa del espacio de entrada suele producir un modelo más robusto.
Regularización: Cuando no es posible obtener más datos, una estrategia clave es agregar restricciones al modelo para que se enfoque en los patrones más importantes y menos propensos a ser el resultado de ruido. Este proceso, conocido como regularización, es esencial para prevenir el sobreajuste y mejorar la generalización.