Transformaciones#
Las series de tiempo no estacionarias presentan patrones de tendencia, estacionalidad o cambios en la varianza que dificultan su modelado y pronóstico. Para abordar estos problemas, se aplican transformaciones matemáticas que permiten:
Convertir una serie no estacionaria en una serie estacionaria
Simplificar los patrones de la serie (por ejemplo, eliminar una tendencia o reducir la estacionalidad)
Estabilizar la varianza cuando esta varía con el nivel de la serie
Tipos de Transformaciones#
Transformaciones para eliminar la tendencia#
Estas técnicas permiten eliminar tendencias deterministas o suavizar componentes que hacen que la serie no tenga una media constante en el tiempo.
Diferenciación (Differencing):
Consiste en calcular las diferencias entre valores consecutivos:
Si después de aplicar una diferencia la serie aún no es estacionaria, se pueden aplicar diferencias adicionales (segunda diferencia, etc.).
¿Cuándo usar?
Cuando la serie muestra una tendencia creciente o decreciente
Cuando el gráfico de la serie indica no estacionariedad en media
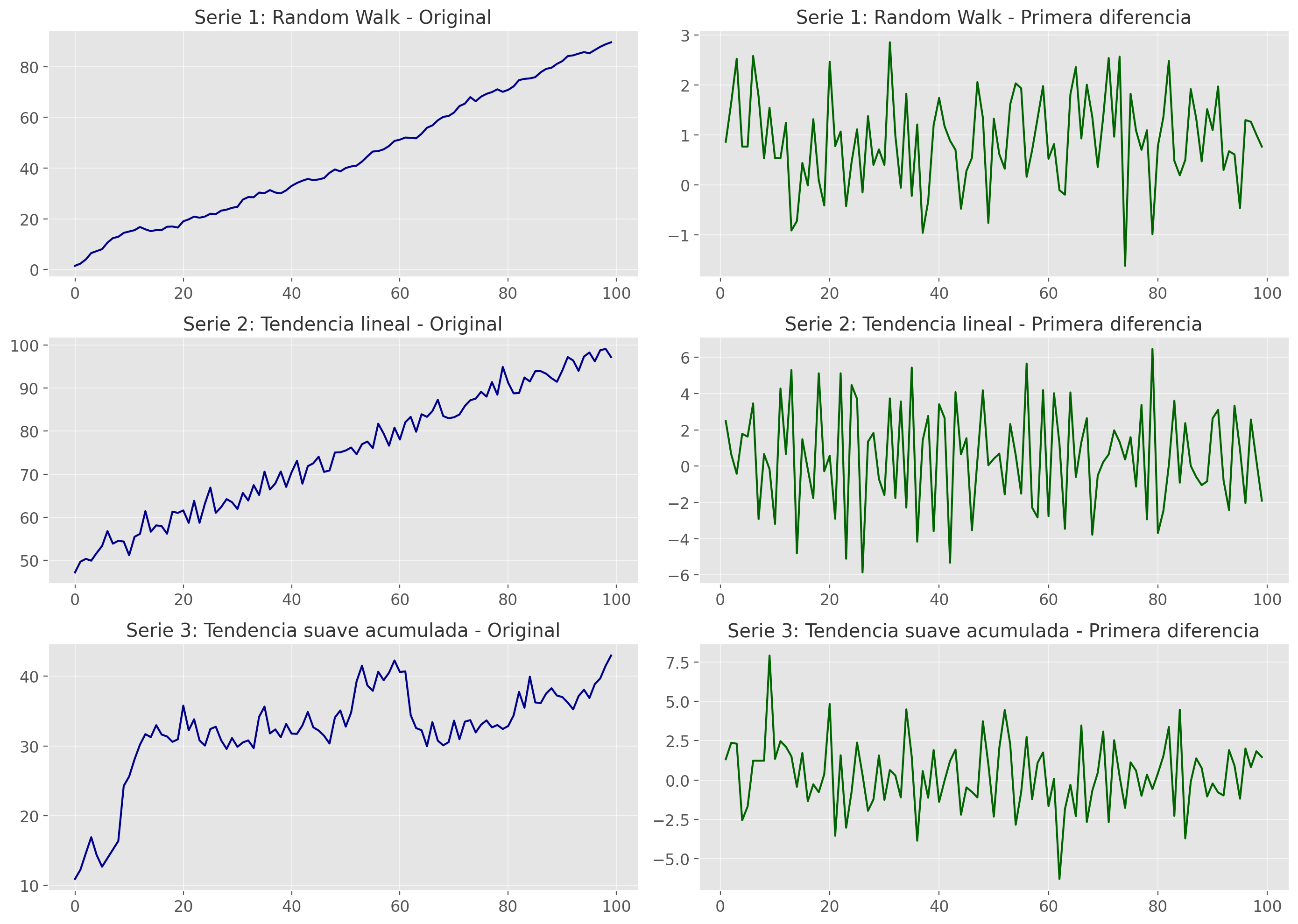
Transformación_diff#
Transformaciones para estabilizar la varianza:#
Logaritmo:
Raíz cuadrada:
Transformación Box-Cox:
Es una familia flexible que incluye al logaritmo y las potencias. Está definida como:
¿Cuándo usar?
Cuando la varianza aumenta con el nivel de la serie
Cuando se observa que los picos y valles aumentan proporcionalmente a la magnitud de los datos
Cuando se requiere que los modelos generen valores positivos
Combinación de Transformaciones:
A menudo es necesario combinar transformaciones para lograr estacionariedad completa:
Transformar para estabilizar la varianza (log, raíz, Box-Cox)
Diferenciar para eliminar tendencia
Opcional: Diferenciación estacional para remover estacionalidades fuertes
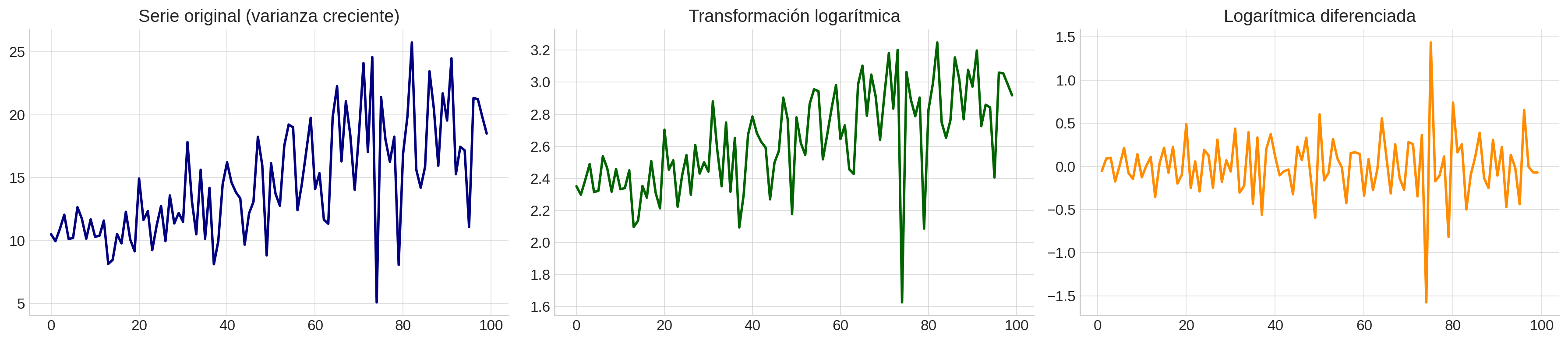
Combinación_transf#
Código en Python para transformaciones:#
Desempleo:#
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
# Cargar el archivo xlsx:
df = pd.read_excel('Desempleo.xlsx')
# Corregir nombres de columnas si tienen espacios
df.columns = df.columns.str.strip()
# Convertir 'Fecha' a datetime y usar como índice
df['Fecha'] = pd.to_datetime(df['Fecha'])
df.set_index('Fecha', inplace=True)
# Ordenar por fecha por si acaso
df = df.sort_index()
# Establecer frecuencia explícita para evitar el warning de statsmodels
df.index.freq = df.index.inferred_freq
plt.figure(figsize=(18, 5))
plt.plot(df, color='navy')
plt.title("Serie de tiempo: Desempleo")
plt.xlabel("Fecha")
plt.ylabel("Valor")
plt.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
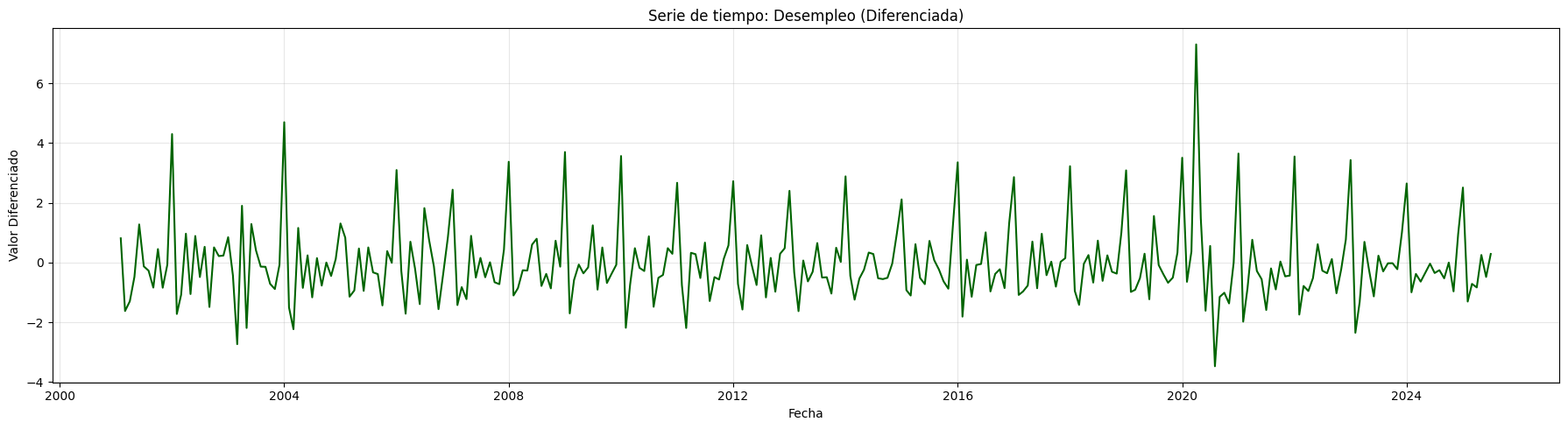
# Transformación: diferenciación:
df_diff = df.diff().dropna()
plt.figure(figsize=(18, 5))
plt.plot(df_diff, color='darkgreen')
plt.title("Serie de tiempo: Desempleo (Diferenciada)")
plt.xlabel("Fecha")
plt.ylabel("Valor Diferenciado")
plt.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
from statsmodels.tsa.stattools import adfuller
adf_result = adfuller(df_diff, regression='n') # 'n' para no incluir constante ni tendencia
print(f'Estadístico ADF: {adf_result[0]}')
print(f'Valor p: {adf_result[1]}')
# Interpretación del resultado
alpha = 0.05
if adf_result[1] < alpha:
print("Rechazamos la hipótesis nula: La serie es estacionaria.")
else:
print("No podemos rechazar la hipótesis nula: La serie no es estacionaria.")
Estadístico ADF: -4.717438227528668
Valor p: 3.7030290244776624e-06
Rechazamos la hipótesis nula: La serie es estacionaria.
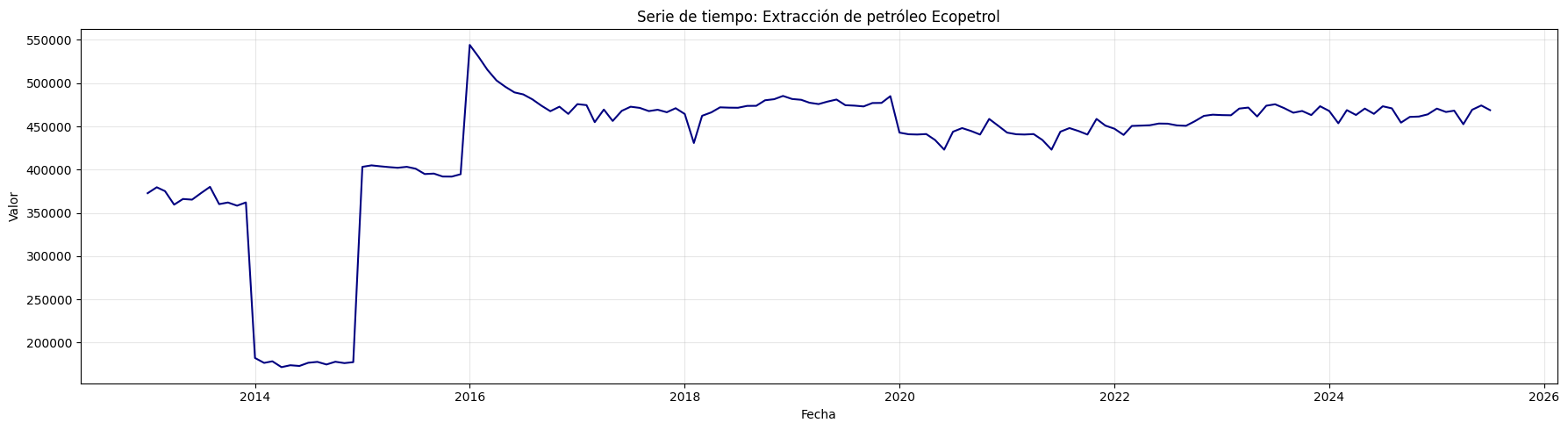
Extracción de petróleo Ecopetrol:#
# Cargar el archivo xlsx:
df = pd.read_excel('Extracción petróleo Ecopetrol.xlsx')
# Corregir nombres de columnas si tienen espacios
df.columns = df.columns.str.strip()
# Convertir 'Fecha' a datetime y usar como índice
df['Fecha'] = pd.to_datetime(df['Fecha'])
df.set_index('Fecha', inplace=True)
# Ordenar por fecha por si acaso
df = df.sort_index()
# Establecer frecuencia explícita para evitar el warning de statsmodels
df.index.freq = df.index.inferred_freq
plt.figure(figsize=(18, 5))
plt.plot(df, color='navy')
plt.title("Serie de tiempo: Extracción de petróleo Ecopetrol")
plt.xlabel("Fecha")
plt.ylabel("Valor")
plt.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
# Transformación: diferenciación:
df_diff = df.diff().dropna()
plt.figure(figsize=(18, 5))
plt.plot(df_diff, color='darkgreen')
plt.title("Serie de tiempo: Extracción de petróleo Ecopetrol (Diferenciada)")
plt.xlabel("Fecha")
plt.ylabel("Valor Diferenciado")
plt.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
adf_result = adfuller(df_diff, regression='n') # 'n' para no incluir constante ni tendencia
print(f'Estadístico ADF: {adf_result[0]}')
print(f'Valor p: {adf_result[1]}')
# Interpretación del resultado
alpha = 0.05
if adf_result[1] < alpha:
print("Rechazamos la hipótesis nula: La serie es estacionaria.")
else:
print("No podemos rechazar la hipótesis nula: La serie no es estacionaria.")
Estadístico ADF: -12.533198791264146
Valor p: 7.230183385773031e-23
Rechazamos la hipótesis nula: La serie es estacionaria.
TRM:#
import yfinance as yf
import matplotlib.dates as mdates
# Descargar datos mensuales desde 2015
start_date = "2015-01-01"
end_date = "2025-07-31"
# TRM de Colombia (USD/COP)
trm = yf.download("USDCOP=X", start=start_date, end=end_date, interval='1mo', auto_adjust=False)['Close']
trm.name = 'TRM (USD/COP)'
# Crear figura
plt.figure(figsize=(10, 5))
plt.plot(trm.index, trm, linestyle='-', color='navy')
# Personalización del gráfico
plt.title("Evolución de la TRM (USD/COP)", fontsize=14)
plt.xlabel("Fecha")
plt.ylabel("TRM (Pesos por USD)")
plt.grid(True, alpha=0.3)
# Formato de fechas en el eje X
plt.gca().xaxis.set_major_locator(mdates.YearLocator())
plt.gca().xaxis.set_major_formatter(mdates.DateFormatter('%Y'))
plt.tight_layout()
plt.show()
[*******************100%*********************] 1 of 1 completed

# Transformación: diferenciación
df_diff = trm.diff().dropna()
plt.figure(figsize=(10, 5))
plt.plot(df_diff.index, df_diff, linestyle='-', color='darkgreen')
plt.title("Diferenciación de la TRM (USD/COP)", fontsize=14)
plt.xlabel("Fecha")
plt.ylabel("Diferencia de TRM")
plt.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
adf_result = adfuller(df_diff, regression='n') # 'n' para no incluir constante ni tendencia
print(f'Estadístico ADF: {adf_result[0]}')
print(f'Valor p: {adf_result[1]}')
# Interpretación del resultado
alpha = 0.05
if adf_result[1] < alpha:
print("Rechazamos la hipótesis nula: La serie es estacionaria.")
else:
print("No podemos rechazar la hipótesis nula: La serie no es estacionaria.")
Estadístico ADF: -4.925362403744495
Valor p: 1.477761458696925e-06
Rechazamos la hipótesis nula: La serie es estacionaria.
# Transformación: Logaritmo
df_log = np.log(trm)
plt.figure(figsize=(18, 5))
plt.plot(df_log, color='darkgreen')
plt.title("Serie de tiempo: TRM (USD/COP) (Logaritmo)")
plt.xlabel("Fecha")
plt.ylabel("Log(Valor)")
plt.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
# Transformación: diferenciación del logaritmo
df_log_diff = df_log.diff().dropna()
plt.figure(figsize=(18, 5))
plt.plot(df_log_diff, color='darkgreen')
plt.title("Serie de tiempo: TRM (USD/COP) (Diferenciación del Logaritmo)")
plt.xlabel("Fecha")
plt.ylabel("Diferencia del Log(Valor)")
plt.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
adf_result = adfuller(df_log_diff, regression='n') # 'n' para no incluir constante ni tendencia
print(f'Estadístico ADF: {adf_result[0]}')
print(f'Valor p: {adf_result[1]}')
# Interpretación del resultado
alpha = 0.05
if adf_result[1] < alpha:
print("Rechazamos la hipótesis nula: La serie es estacionaria.")
else:
print("No podemos rechazar la hipótesis nula: La serie no es estacionaria.")
Estadístico ADF: -4.993827752170626
Valor p: 1.0868579718262527e-06
Rechazamos la hipótesis nula: La serie es estacionaria.