Análisis residuales ajuste modelo AR al precio de electricidad#
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib.dates as mdates
from statsmodels.tsa.stattools import adfuller
from statsmodels.graphics.tsaplots import plot_acf, plot_pacf
Funciones:#
def plot_serie_tiempo(
serie: pd.DataFrame,
nombre: str,
unidades: str = None,
columna: str = None,
fecha_inicio: str = None,
fecha_fin: str = None,
color: str = 'navy',
linewidth: float = 2,
num_xticks: int = 12,
estacionalidad: str = None, # 'diciembre', 'enero', 'semana', 'semestre', 'custom_month'
custom_month: int = None, # Si quieres marcar otro mes (ejemplo: 3 para marzo)
vline_label: str = None, # Etiqueta para la(s) línea(s) vertical(es)
hlines: list = None, # lista de valores horizontales a marcar
hlines_labels: list = None, # lista de etiquetas para líneas horizontales
color_estacion: str = 'darkgray', # color de las líneas estacionales
alpha_estacion: float = 0.3, # transparencia de líneas estacionales
color_hline: str = 'gray', # color de las líneas horizontales
alpha_hline: float = 0.7 # transparencia de líneas horizontales
):
"""
Gráfico elegante de serie de tiempo.
- Eje X alineado con la primera fecha real de la serie.
- Opcional: marcar estacionalidades (diciembres, semanas, semestres, mes personalizado) con etiqueta.
- Líneas horizontales con etiqueta opcional (legend).
"""
df = serie.copy()
if columna is None:
columna = df.columns[0]
if fecha_inicio:
df = df[df.index >= fecha_inicio]
if fecha_fin:
df = df[df.index <= fecha_fin]
# Asegura que el índice sea datetime y esté ordenado
df = df.sort_index()
df.index = pd.to_datetime(df.index)
plt.style.use('ggplot')
fig, ax = plt.subplots(figsize=(14, 6))
# Gráfica principal
ax.plot(df.index, df[columna], color=color, linewidth=linewidth, label=nombre)
ax.set_title(f"Serie de tiempo: {nombre}", fontsize=20, weight='bold',
color='black')
ax.set_xlabel("Fecha", fontsize=15, color='black')
ax.set_ylabel(unidades, fontsize=15, color='black')
ax.tick_params(axis='both', colors='black', labelsize=13)
for label in ax.get_xticklabels() + ax.get_yticklabels():
label.set_color('black')
# Limita el rango del eje X exactamente al rango de fechas de la serie (no corrido)
ax.set_xlim(df.index.min(), df.index.max())
# Ticks equidistantes en eje X, asegurando que empieza en la primera fecha
idx = df.index
if len(idx) > num_xticks:
ticks = np.linspace(0, len(idx)-1, num_xticks, dtype=int)
ticks[0] = 0 # asegúrate que arranque en la primera fecha
ticklabels = [idx[i] for i in ticks]
ax.set_xticks(ticklabels)
ax.set_xticklabels([pd.to_datetime(t).strftime('%b %Y') for t in ticklabels], rotation=0, color='black')
else:
ax.xaxis.set_major_formatter(mdates.DateFormatter('%b %Y'))
fig.autofmt_xdate(rotation=0)
# ==============================
# LÍNEAS VERTICALES: Estacionalidad (con etiqueta en leyenda si se desea)
# ==============================
vlines_plotted = False
if estacionalidad is not None:
if estacionalidad == 'diciembre':
fechas_mark = df[df.index.month == 12].index
elif estacionalidad == 'enero':
fechas_mark = df[df.index.month == 1].index
elif estacionalidad == 'semana':
fechas_mark = df[df.index.weekday == 0].index
elif estacionalidad == 'semestre':
fechas_mark = df[df.index.month.isin([6, 12])].index
elif estacionalidad == 'custom_month' and custom_month is not None:
fechas_mark = df[df.index.month == custom_month].index
else:
fechas_mark = []
for i, f in enumerate(fechas_mark):
# Solo pone la etiqueta una vez (la primera línea)
if not vlines_plotted and vline_label is not None:
ax.axvline(f, color=color_estacion, alpha=alpha_estacion, linewidth=2, linestyle='--', zorder=0, label=vline_label)
vlines_plotted = True
else:
ax.axvline(f, color=color_estacion, alpha=alpha_estacion, linewidth=2, linestyle='--', zorder=0)
# ==============================
# LÍNEAS HORIZONTALES OPCIONALES, con leyenda
# ==============================
if hlines is not None:
if hlines_labels is None:
hlines_labels = [None] * len(hlines)
for i, h in enumerate(hlines):
if hlines_labels[i] is not None:
ax.axhline(h, color=color_hline, alpha=alpha_hline, linewidth=1.5, linestyle='--', zorder=0, label=hlines_labels[i])
else:
ax.axhline(h, color=color_hline, alpha=alpha_hline, linewidth=1.5, linestyle='--', zorder=0)
# Coloca la leyenda solo si hay etiquetas
handles, labels = ax.get_legend_handles_labels()
if any(labels):
ax.legend(loc='best', fontsize=13, frameon=True)
ax.grid(True, alpha=0.4)
plt.tight_layout()
plt.show()
##################################################################################
def analisis_estacionariedad(
serie: pd.Series,
nombre: str = None,
lags: int = 24,
xtick_interval: int = 3
):
"""
Gráfica y análisis de estacionariedad para una serie de tiempo:
- Serie original, diferencia, logaritmo y diferencia del logaritmo.
- Muestra la ACF, PACF y resultado ADF en subplots.
Args:
serie: Serie de tiempo (índice datetime, pandas.Series)
nombre: Nombre de la serie (para títulos)
lags: Número de rezagos para ACF/PACF
xtick_interval: Mostrar ticks en X cada este número de lags, incluyendo siempre el lag 1
"""
if nombre is None:
nombre = serie.name if serie.name is not None else "Serie"
# Transformaciones
serie_1 = serie.copy()
serie_2 = serie_1.diff().dropna()
serie_3 = np.log(serie_1)
serie_4 = serie_3.diff().dropna()
titulos = [
f"Serie original: {nombre}",
"Diferenciación",
"Logaritmo",
"Diferenciación del Logaritmo"
]
series = [serie_1, serie_2, serie_3, serie_4]
resultados_adf = []
interpretaciones = []
for i, serie_i in enumerate(series):
serie_ = serie_i.dropna()
# Selección de regresión en ADF
if i in [0, 2]:
adf = adfuller(serie_, regression='ct')
else:
adf = adfuller(serie_, regression='c')
estadistico = adf[0]
pvalue = adf[1]
resultados_adf.append((estadistico, pvalue))
interpretaciones.append("Estacionaria" if pvalue < 0.05 else "No estacionaria")
fig, axes = plt.subplots(4, 3, figsize=(18, 16))
colores = ['black', 'black', 'black', 'black']
for fila in range(4):
# Serie y etiquetas
axes[fila, 0].plot(series[fila], color=colores[fila])
axes[fila, 0].set_title(titulos[fila], color='black')
axes[fila, 0].set_xlabel("Fecha", color='black')
if fila == 0:
axes[fila, 0].set_ylabel("Valor", color='black')
elif fila == 1:
axes[fila, 0].set_ylabel("Δ Valor", color='black')
elif fila == 2:
axes[fila, 0].set_ylabel("Log(Valor)", color='black')
else:
axes[fila, 0].set_ylabel("Δ Log(Valor)", color='black')
axes[fila, 0].grid(True, alpha=0.3)
axes[fila, 0].tick_params(axis='both', labelsize=11, colors='black')
# ACF
plot_acf(
series[fila].dropna(),
lags=lags,
ax=axes[fila, 1],
zero=False,
color=colores[fila]
)
axes[fila, 1].set_title("ACF", color='black')
# xticks: incluir lag 1 y luego cada xtick_interval (ej: 1, 3, 6, ...)
xticks = [1] + list(range(xtick_interval, lags + 1, xtick_interval))
xticks = sorted(set(xticks)) # asegura que no haya duplicados
axes[fila, 1].set_xticks(xticks)
axes[fila, 1].tick_params(axis='both', labelsize=11, colors='black')
axes[fila, 1].set_xlabel("Lag", color='black')
axes[fila, 1].set_ylabel("Autocorrelación", color='black')
# PACF
plot_pacf(
series[fila].dropna(),
lags=lags,
ax=axes[fila, 2],
zero=False,
color=colores[fila]
)
axes[fila, 2].set_title("PACF", color='black')
axes[fila, 2].set_xticks(xticks)
axes[fila, 2].tick_params(axis='both', labelsize=11, colors='black')
axes[fila, 2].set_xlabel("Lag", color='black')
axes[fila, 2].set_ylabel("Autocorrelación parcial", color='black')
# Indicador estacionariedad (más abajo)
axes[fila, 0].text(
0.02, 0.85,
f"ADF: {resultados_adf[fila][0]:.2f}\np-valor: {resultados_adf[fila][1]:.4f}\n{interpretaciones[fila]}",
transform=axes[fila, 0].transAxes,
fontsize=11, bbox=dict(facecolor='white', alpha=0.85), color='black'
)
plt.tight_layout()
plt.show()
# Devuelve los resultados en un dict (opcional)
adf_dict = {
titulos[i]: {
"estadístico ADF": resultados_adf[i][0],
"p-valor": resultados_adf[i][1],
"interpretación": interpretaciones[i]
}
for i in range(4)
}
return adf_dict
Precio de electricidad#
# Cargar el archivo
precio_electricidad = pd.read_csv("Precio_electricidad.csv")
# Corregir nombres de columnas si tienen espacios
precio_electricidad.columns = precio_electricidad.columns.str.strip()
# Convertir 'Fecha' a datetime y usar como índice
precio_electricidad['Fecha'] = pd.to_datetime(precio_electricidad['Fecha'])
precio_electricidad.set_index('Fecha', inplace=True)
# Ordenar por fecha por si acaso
precio_electricidad = precio_electricidad.sort_index()
# Establecer frecuencia explícita para evitar el warning de statsmodels
precio_electricidad.index.freq = precio_electricidad.index.inferred_freq
precio_electricidad.head()
| Precio | |
|---|---|
| Fecha | |
| 2000-01-01 | 36.539729 |
| 2000-02-01 | 39.885205 |
| 2000-03-01 | 35.568126 |
| 2000-04-01 | 44.957443 |
| 2000-05-01 | 33.848903 |
plot_serie_tiempo(
precio_electricidad,
nombre="Precio de electricidad",
columna='Precio',
unidades='COP/kWh',
estacionalidad='diciembre',
vline_label="Diciembre",
num_xticks = 14
)
adf_resultados = analisis_estacionariedad(
precio_electricidad['Precio'],
nombre="Precio de electricidad",
lags=36,
xtick_interval=3
)
Modelo AR a la serie transformada: logaritmo#
Serie transformada: logaritmo
# Transformación: Logaritmo
df_log = np.log(precio_electricidad)
plot_serie_tiempo(
df_log,
nombre="Logaritmo del precio de electricidad",
columna='Precio',
unidades='',
num_xticks = 14
)
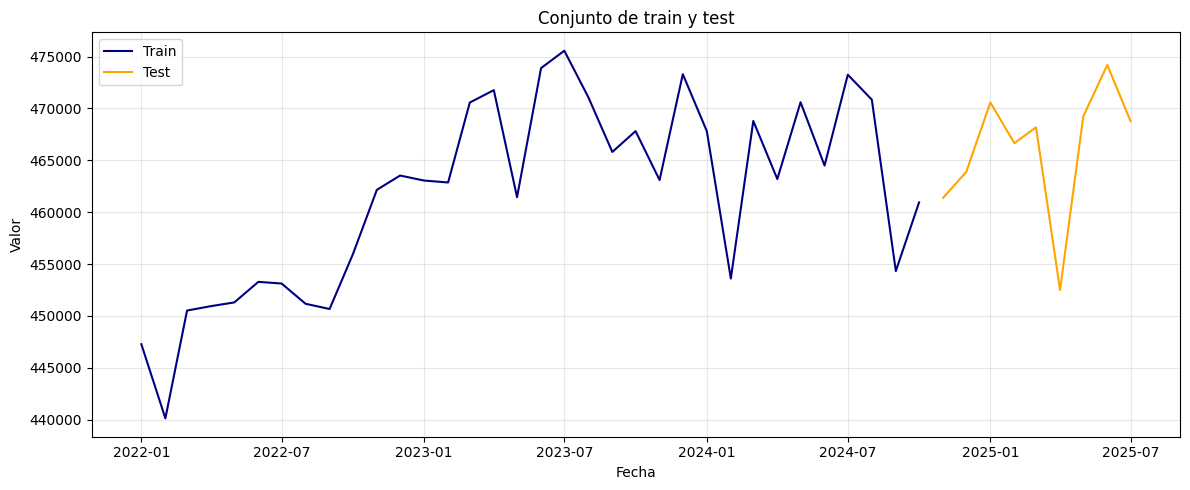
Conjunto de train y test:
# Dividir en train y test (por ejemplo, 80% train, 20% test)
split = int(len(df_log) * 0.8)
train, test = df_log[:split], df_log[split:]
# Graficar train y test:
plt.figure(figsize=(12, 5))
plt.plot(train, label='Train', color='navy')
plt.plot(test, label='Test', color='orange')
plt.title("Conjunto de train y test")
plt.xlabel("Fecha")
plt.ylabel("Valor")
plt.legend()
plt.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
Ajuste modelo AR#
from statsmodels.tsa.statespace.sarimax import SARIMAX
# Definir los parámetros del modelo AR (p, 0, 0)
order = (1, 0, 0) # Puedes ajustar según el análisis de ACF y PACF
trend = 'ct' # 'c' = constante, 't' = tendencia, 'ct' = constante + tendencia, 'n' = sin tendencia
# Ajustar el modelo con los datos de entrenamiento
model = SARIMAX(train, order=order, trend=trend)
results = model.fit()
# Mostrar resumen del modelo
print(results.summary())
SARIMAX Results
==============================================================================
Dep. Variable: Precio No. Observations: 232
Model: SARIMAX(1, 0, 0) Log Likelihood -7.218
Date: Fri, 24 Oct 2025 AIC 22.436
Time: 15:39:26 BIC 36.223
Sample: 01-01-2000 HQIC 27.996
- 04-01-2019
Covariance Type: opg
==============================================================================
coef std err z P>|z| [0.025 0.975]
------------------------------------------------------------------------------
intercept 0.6807 0.122 5.600 0.000 0.442 0.919
drift 0.0012 0.000 3.282 0.001 0.000 0.002
ar.L1 0.8251 0.030 27.572 0.000 0.766 0.884
sigma2 0.0621 0.004 14.777 0.000 0.054 0.070
===================================================================================
Ljung-Box (L1) (Q): 0.81 Jarque-Bera (JB): 54.71
Prob(Q): 0.37 Prob(JB): 0.00
Heteroskedasticity (H): 4.41 Skew: 0.51
Prob(H) (two-sided): 0.00 Kurtosis: 5.15
===================================================================================
Warnings:
[1] Covariance matrix calculated using the outer product of gradients (complex-step).
1. Independencia temporal (Ljung–Box test)
Prob(Q) = 0.37 → valor p > 0.05.
Esto indica que no se rechaza la hipótesis nula de independencia de los residuales.
En otras palabras, no hay autocorrelación significativa, por lo que el modelo ha capturado adecuadamente la estructura temporal de la serie.
Los residuales se comportan como ruido blanco en cuanto a dependencia temporal.
2. Normalidad (Jarque–Bera, Skew y Kurtosis)
JB = 54.71 con Prob(JB) = 0.00 → valor p < 0.05.
Esto implica que se rechaza la hipótesis nula de normalidad.Por tanto, los residuales no siguen una distribución normal exacta.Analizando los componentes:
Skew = 0.51 → indica ligera asimetría positiva: los residuales tienden a tener cola más larga hacia la derecha.
Kurtosis = 5.15 → valor mayor que 3, lo que sugiere colas más pesadas (mayor concentración de valores extremos) que una distribución normal.
En conjunto, la distribución de los residuales presenta forma aproximadamente simétrica con colas gruesas, lo que podría deberse a algunos valores atípicos o episodios de variabilidad extrema en la serie.
Esto afecta principalmente la forma de los intervalos de predicción, pero no necesariamente la precisión del valor central del pronóstico (la media esperada).
Aunque la prueba JB rechaza la normalidad (debido a su alta sensibilidad), si el histograma y el Q-Q plot muestran forma de campana con leves desviaciones en los extremos, se puede considerar que la distribución es aproximadamente normal para fines prácticos.
3. Varianza constante (Heteroskedasticity test)
Prob(H) = 0.00 → valor p < 0.05.
Esto indica que se rechaza la hipótesis nula de homocedasticidad.Es decir, la varianza de los residuales no es constante, y existe heterocedasticidad.En términos prácticos, esto significa que en ciertos periodos los errores tienden a tener mayor dispersión que en otros.
El gráfico de residuales en el tiempo probablemente muestra zonas donde la amplitud de las fluctuaciones aumenta o disminuye.
Este comportamiento puede corregirse mediante:
Transformaciones (por ejemplo, logaritmo o Box–Cox),
O modelos que consideren varianza cambiante (como ARCH/GARCH).
Esto no impide pronosticar, pero puede hacer que los intervalos de confianza o bandas de predicción sean poco realistas (por ejemplo, demasiado angostas en algunos periodos y muy amplias en otros).
4. Conclusión general
No hay autocorrelación (residuales independientes).
Distribución no perfectamente normal, con ligera asimetría derecha y colas pesadas.
Varianza no constante, lo cual sugiere heterocedasticidad.
En resumen, el modelo explica correctamente la dinámica temporal, pero los residuales presentan problemas de varianza y normalidad, probablemente asociados a fluctuaciones irregulares o valores extremos en la serie.
Aunque esto no invalida el modelo para pronóstico, sí sugiere que los intervalos de predicción pueden no tener la cobertura esperada, por lo que podría ser recomendable:
aplicar una transformación estabilizadora de varianza, o
considerar un modelo con componentes de varianza condicional (como GARCH o SARIMAX con errores heterocedásticos).
Ajuste y pronóstico en la serie original:#
###### Pronóstico dentro de la muestra (train) ######
fitted_values = results.fittedvalues
conf_int_train = results.get_prediction().conf_int(alpha=0.05) # Intervalo de confianza del 95%
# Alinear por si el índice de train y fitted_values difieren en los primeros p rezagos
fitted_values = fitted_values.reindex(train.index)
###### Pronóstico fuera de la muestra (test) #####
current_results = results # Modelo ajustado
forecasted_test = []
lower_ci_test = []
upper_ci_test = []
for i in range(len(test)):
forecaster = current_results.get_forecast(steps=1) # Un pronóstico hacia adelante
forecast_mean_test = forecaster.predicted_mean.iloc[0] # Media del pronóstico
ci_i_test = forecaster.conf_int(alpha=0.05).iloc[0] # Intervalo de confianza del 95%
forecasted_test.append(forecast_mean_test)
lower_ci_test.append(ci_i_test.iloc[0]) # límite inferior
upper_ci_test.append(ci_i_test.iloc[1]) # límite superior
# Actualiza el estado con el valor real (método recursivo)
current_results = current_results.append(endog=[test.iloc[i]], refit=False)
forecasted_test = pd.Series(forecasted_test, index=test.index, name='forecast_test')
lower_ci_test = pd.Series(lower_ci_test, index=test.index, name='lower_test')
upper_ci_test = pd.Series(upper_ci_test, index=test.index, name='upper_test')
###### Pronóstico fuera de la muestra: futuro #####
n_forecast = 5 # Pronóstico para 12 meses
# Actualiza el estado con el dataset de test
current_results = results.append(endog=test, refit=False)
forecasting = []
lower_ci = []
upper_ci = []
for i in range(n_forecast):
forecaster = current_results.get_forecast(steps=1) # Un pronóstico hacia adelante
forecast_mean = forecaster.predicted_mean.iloc[0] # Media del pronóstico
ci_i = forecaster.conf_int(alpha=0.05).iloc[0] # Intervalo de confianza del 95%
forecasting.append(forecast_mean)
lower_ci.append(ci_i.iloc[0]) # límite inferior
upper_ci.append(ci_i.iloc[1]) # límite superior
# Alimenta el modelo con el valor pronosticado (pronóstico puro hacia adelante)
current_results = current_results.append(endog=[forecast_mean], refit=False)
# Fechas futuras (mensuales inicio de mes)
last_date = test.index[-1]
future_dates = pd.date_range(start=last_date + pd.offsets.MonthBegin(1),
periods=n_forecast, freq='MS')
# Asegura Series con índice de fechas
forecasting = pd.Series(forecasting, index=future_dates, name='forecast')
lower_ci = pd.Series(lower_ci, index=future_dates, name='lower')
upper_ci = pd.Series(upper_ci, index=future_dates, name='upper')
# Inversa de la transformación - SARIMAX devuelve automáticamente la diferenciación
y_pred_train = np.exp(fitted_values)
y_pred_test = np.exp(forecasted_test)
forcasting_orig = np.exp(forecasting) # pronóstico futuro
# Intervalos de confianza
lower_bt = np.exp(lower_ci)
upper_bt = np.exp(upper_ci)
# Graficar sobre la serie original
plt.figure(figsize=(12,6))
# Serie original
plt.plot(precio_electricidad[1:], label='Precio de electricidad', color='black')
# Ajuste en train
plt.plot(y_pred_train[1:], label='Ajuste en train', color='tab:blue')
# Ajuste en test
plt.plot(y_pred_test, label='Pronóstico en test', color='tab:green')
# Pronóstico futuro + IC
plt.plot(forcasting_orig, label='Pronóstico futuro', color='tab:red', linestyle='--')
plt.fill_between(future_dates, lower_bt.values, upper_bt.values, color='tab:red', alpha=0.2, label='IC 95%')
plt.title('Ajuste y pronóstico')
plt.xlabel('Tiempo')
plt.ylabel('Valor')
plt.legend()
plt.tight_layout()
plt.show()
Análisis de residuales#
y_pred = y_pred_train[1:]
y_real = precio_electricidad[1:split]
plt.figure(figsize=(20,6))
# Serie real
plt.plot(y_real, label='Serie real', color='black', linewidth=2)
# Valores ajustados o predichos
plt.plot(y_pred, label='Ajuste del modelo', color='blue', linewidth=2, alpha=0.8)
plt.title("Ajuste sobre Train", fontsize=12)
plt.xlabel("Tiempo")
plt.ylabel("Valor")
plt.legend()
plt.grid(alpha=0.3)
plt.tight_layout()
plt.show()
# Extraer residuales
residuals = results.resid
print(residuals.head())
Fecha
2000-01-01 -0.300585
2000-02-01 0.035039
2000-03-01 -0.152969
2000-04-01 0.174651
2000-05-01 -0.303625
Freq: MS, dtype: float64
Gráfico de residuales en el tiempo#
# Gráfico en el tiempo
plt.figure(figsize=(11,4))
plt.scatter(residuals.index, residuals, color="darkblue")
plt.axhline(0, ls="--", color="black")
plt.title("Residuales en el tiempo")
plt.xlabel("Tiempo")
plt.ylabel("Residual")
plt.tight_layout()
plt.show()
ACF y PACF de los residuales#
import statsmodels.api as sm
fig, axes = plt.subplots(1, 2, figsize=(12,4))
# Gráfico ACF
sm.graphics.tsa.plot_acf(residuals, lags=20, ax=axes[0], zero=False, color='navy')
axes[0].set_title("ACF de los residuales")
axes[0].set_xlabel("Rezagos")
axes[0].set_ylabel("Autocorrelación")
# Gráfico PACF
sm.graphics.tsa.plot_pacf(residuals, lags=20, ax=axes[1], zero=False, color='navy')
axes[1].set_title("PACF de los residuales")
axes[1].set_xlabel("Rezagos")
axes[1].set_ylabel("Autocorrelación parcial")
plt.tight_layout()
plt.show()
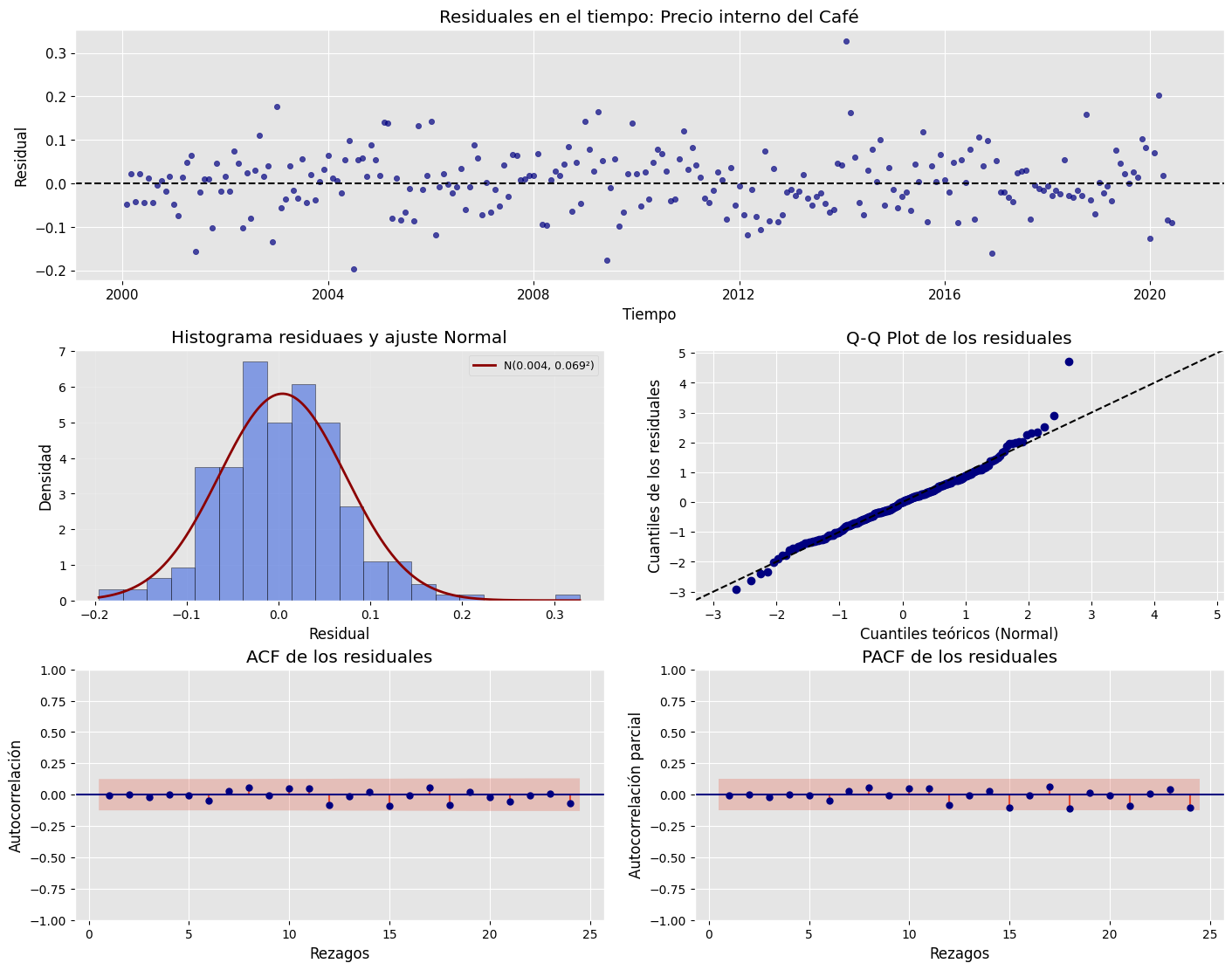
Histograma de los residuales#
# Histograma de residuales con ajuste Normal
from scipy.stats import norm
# Parámetros de la normal ajustada (MLE)
mu = residuals.mean()
sigma = residuals.std(ddof=1)
# Rango para la curva teórica
x = np.linspace(residuals.min(), residuals.max(), 400)
pdf = norm.pdf(x, loc=mu, scale=sigma)
plt.figure(figsize=(8,5))
plt.hist(residuals, bins="auto", density=True, alpha=0.6, edgecolor="k", color="blue")
plt.plot(x, pdf, lw=2, label=f"N({mu:.3f}, {sigma:.3f}²)", color="darkred")
plt.title("Histograma de residuales + ajuste Normal")
plt.xlabel("Residual")
plt.ylabel("Densidad")
plt.legend()
plt.tight_layout()
plt.show()
QQ-plot de los residuales#
plt.figure(figsize=(6,6))
sm.qqplot(residuals, line='45', fit=True)
plt.title("Q-Q Plot de los residuales")
plt.xlabel("Cuantiles teóricos (Normal)")
plt.ylabel("Cuantiles de los residuales")
plt.tight_layout()
plt.show()
<Figure size 600x600 with 0 Axes>

Gráfico de valores predichos vs. valores reales#
plt.figure(figsize=(6,6))
plt.scatter(y_real, y_pred, color='blue', alpha=0.6, edgecolor='k')
# Línea de identidad (y = x)
min_val = min(y_real.min().values, y_pred.min())
max_val = max(y_real.max().values, y_pred.max())
plt.plot([min_val, max_val], [min_val, max_val], color='black', lw=2)
plt.title("Valores predichos vs. valores reales", fontsize=12)
plt.xlabel("Valores reales")
plt.ylabel("Valores predichos")
plt.axis("equal") # asegura proporciones iguales para la diagonal
plt.grid(alpha=0.3)
plt.tight_layout()
plt.show()
1. Qué significa la forma de embudo
En la parte estrecha del embudo, los errores (residuales) son pequeños: el modelo predice bien en esa zona.
En la parte ancha, los errores son grandes: la dispersión aumenta con el nivel de la variable.
En resumen:
El modelo tiende a subestimar la variabilidad cuando los valores reales son grandes, y a sobreestimarla cuando los valores son pequeños.
2. Cómo confirmarlo estadísticamente
El embudo visual se traduce en heterocedasticidad, lo que puedes
confirmar con: - El indicador de Heteroskedasticity (H) que ya
entrega statsmodels.
Si el Prob(H) fuera < 0.05, confirmaría estadísticamente ese patrón.
3. Por qué ocurre
Algunas causas típicas:
La relación entre la variable dependiente y los predictores no es lineal.
La variable tiene una escala amplia (valores grandes y pequeños mezclados).
El modelo no fue ajustado sobre una transformación estabilizadora (como log o Box–Cox).
Los errores crecen proporcionalmente al nivel de la serie (muy común en datos económicos o energéticos).
4. Qué implica para el modelo
- El pronóstico medio (el valor esperado) sigue siendo útil,pero los intervalos de predicción pueden ser inadecuados,ya que el modelo asume una varianza constante cuando en realidad crece o disminuye.
En series de tiempo, esta heterocedasticidad puede hacer que el modelo subestime la incertidumbre en los picos y sobrestime la precisión en valores bajos.
5. Cómo corregirlo
Para reducir o eliminar la forma de embudo:
Transformar la variable dependiente para estabilizar la varianza:
Logaritmo:
y_log = np.log(y)(aunque esta transformación ya se hizo).Raíz cuadrada:
y_sqrt = np.sqrt(y)Box–Cox:
scipy.stats.boxcox(y)
Estas transformaciones reducen la diferencia de escala entre valores pequeños y grandes.
- Probar un modelo con estructura de varianza variable,como modelos GARCH o SARIMAX con errores heterocedásticos.
Incluir predictores adicionales o términos no lineales (por ejemplo, \(x^2\)) si el patrón depende de alguna variable explicativa.
6. Conclusión
Que el gráfico “predichos vs. reales” tenga forma de embudo significa que la varianza de los errores depende del nivel de la variable. Es decir, el modelo tiene heterocedasticidad.
Esto no invalida el modelo para pronóstico puntual, pero afecta la precisión y confiabilidad de los intervalos de predicción. Se recomienda aplicar una transformación de la variable o ajustar un modelo que considere varianza no constante.