Métricas de evaluación en regresión#
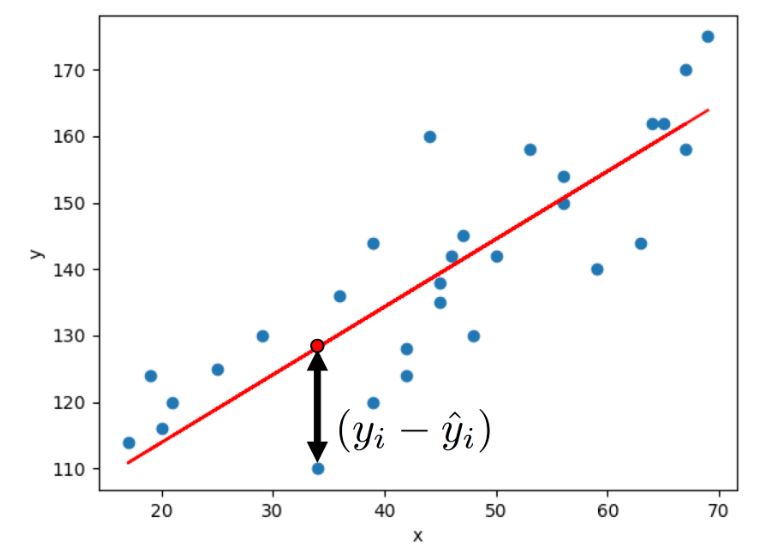
Error#
R2 Score o Coeficiente de Determinación:#
Es una métrica que indica qué tan bien los valores predichos se ajustan a los valores observados. Se interpreta como el porcentaje de la varianza de la variable dependiente que es explicada por el modelo.
donde \(𝑦_𝑖\) son los valores observados, \(\hat{y_i}\) son los valores predichos y \(\bar{y}\) es la media de los valores observados.
Un valor de \(R^2\) cercano a 1 indica un buen ajuste del modelo. Si \(R^2=0\), el modelo no explica nada de la variabilidad en los datos. Si es negativo, el modelo es peor que un modelo que simplemente predice la media de los valores observados.
Mean Absolute Error (MAE):#
Es la media de las diferencias absolutas entre los valores observados y los valores predichos. Proporciona una idea de cuán grande es el error promedio en las predicciones.
MAE es fácil de interpretar, ya que está en las mismas unidades que los datos. Sin embargo, no penaliza errores grandes de manera más fuerte que errores pequeños.
Mean Squared Error (MSE):#
Es la media de los cuadrados de las diferencias entre los valores observados y los valores predichos. Penaliza más los errores grandes que los pequeños.
MSE es útil cuando se quiere penalizar los errores grandes. Sin embargo, no está en las mismas unidades que los datos originales, lo que puede dificultar la interpretación.
Root Mean Squared Error (RMSE):#
Es la raíz cuadrada de la media de los errores cuadrados (MSE). RMSE da una medida de la magnitud promedio de los errores de predicción, teniendo en cuenta tanto la varianza como la media del error.
RMSE está en las mismas unidades que la variable de interés, lo que facilita su interpretación. Es útil para comprender la precisión general del modelo, penalizando más los errores grandes que los pequeños debido a la elevación al cuadrado de las diferencias.
El RMSE es una métrica comúnmente utilizada en regresión debido a su facilidad de interpretación y a que combina la penalización de errores grandes (al igual que el MSE) con una representación en las mismas unidades que la variable objetivo.
Mean Absolute Percentage Error (MAPE):#
Es el promedio de los errores absolutos porcentuales entre los valores observados y predichos.
MAPE se interpreta como un porcentaje de error, lo que facilita su comprensión. Sin embargo, puede ser problemático cuando \(y_i\) es cercano a cero, ya que los valores pequeños inflan el error.
Max Error:#
Es el error máximo observado entre los valores predichos y los valores reales.
Indica el peor error cometido por el modelo. Es útil cuando se quiere asegurar que los errores grandes sean mínimos.
Explained Variance Score:#
Mide la proporción de la varianza de los datos que es capturada por el modelo, similar al \(R^2\) , pero puede ser negativo si el modelo no se ajusta bien.
Un valor de 1 indica que el modelo explica toda la varianza, mientras que un valor cercano a 0 indica poca o ninguna capacidad de explicación. Valores negativos indican un modelo peor que la media.
Cómo usarlos:#
1. R2 Score o Coeficiente de Determinación:
Cuándo usarlo: Es útil para entender qué tan bien el modelo está explicando la variabilidad de los datos observados.
Series de tiempo: Puede ser problemático si el modelo no captura bien las dinámicas temporales, ya que un buen \(𝑅^2\) no siempre significa que las predicciones futuras serán precisas. Es mejor usarlo en combinación con otras métricas.
2. Mean Absolute Error (MAE):
Cuándo usarlo: Es útil cuando se desea una medida fácil de interpretar que no penalice en exceso los errores grandes.
Series de tiempo: Es recomendable cuando los errores tienen una importancia uniforme y quieres una medida que refleje el error promedio absoluto en las mismas unidades de la variable objetivo.
3. Mean Squared Error (MSE):
Cuándo usarlo: Es útil cuando se desea penalizar más los errores grandes, ya que eleva al cuadrado las diferencias.
Series de tiempo: Es valioso en situaciones donde los grandes errores son inaceptables, como en aplicaciones financieras, pero puede ser sensible a valores atípicos.
4. Root Mean Squared Error (RMSE):
Cuándo usarlo: Es conveniente cuando se quiere interpretar el error en las mismas unidades que los datos originales, pero manteniendo la penalización de los errores grandes como el MSE.
Series de tiempo: Ideal para comparar la precisión entre diferentes modelos de series de tiempo. Como el RMSE penaliza los errores grandes, es útil cuando se desea minimizar los errores grandes.
5. Mean Absolute Percentage Error (MAPE):
Cuándo usarlo: Es útil cuando se necesita interpretar el error en términos porcentuales, lo que facilita la comparación entre diferentes modelos o series con diferentes escalas.
Series de tiempo: Se usa frecuentemente, pero puede ser problemática si los valores reales son cercanos a cero, ya que puede inflar el error. Es útil para series donde los valores observados no varían en órdenes de magnitud.
6. Max Error:
Cuándo usarlo: Es útil cuando es crucial entender el peor caso de error del modelo.
Series de tiempo: Importante en aplicaciones donde un solo error grande puede tener consecuencias significativas, como en la predicción de eventos extremos en series financieras.
7. Explained Variance Score:
Cuándo usarlo: Se usa para evaluar cuánta varianza del dato es explicada por el modelo.
Series de tiempo: Es útil en la validación de modelos de series de tiempo donde se quiere asegurar que el modelo está capturando la estructura general de la variabilidad, pero no debe ser usada sola, ya que no considera la calidad de las predicciones futuras.
Resumen para series de tiempo:
MAE y RMSE son generalmente preferibles para series de tiempo debido a su fácil interpretación y la capacidad de reflejar tanto la magnitud como la dispersión del error.
MAPE es útil para interpretaciones porcentuales pero con cuidado en datos cercanos a cero.
Max Error es crítico cuando los errores extremos no son aceptables.
R^2 Score y Explained Variance Score pueden complementar la evaluación, pero con precaución ya que no siempre capturan dinámicas temporales.