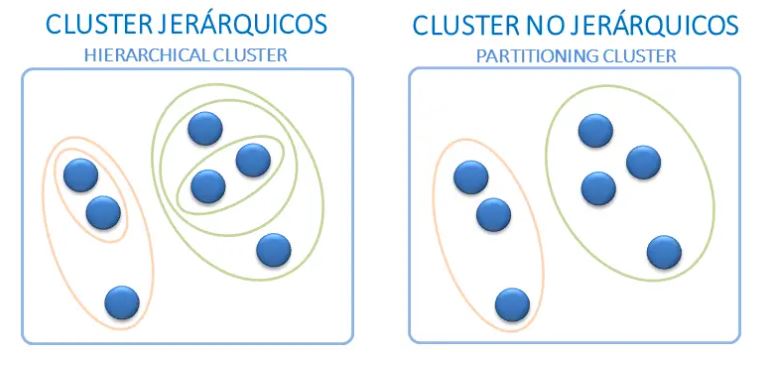
Clustering Jerárquico#
El clustering jerárquico es un enfoque alternativo que agrupa objetos basado en su similaridad, útil cuando los datos no tienen etiquetas de clase y se desea realizar un agrupamiento sin conocer el número de clusters.
Tipos de Clustering Jerárquico:#
Aglomerativo (bottom-up):
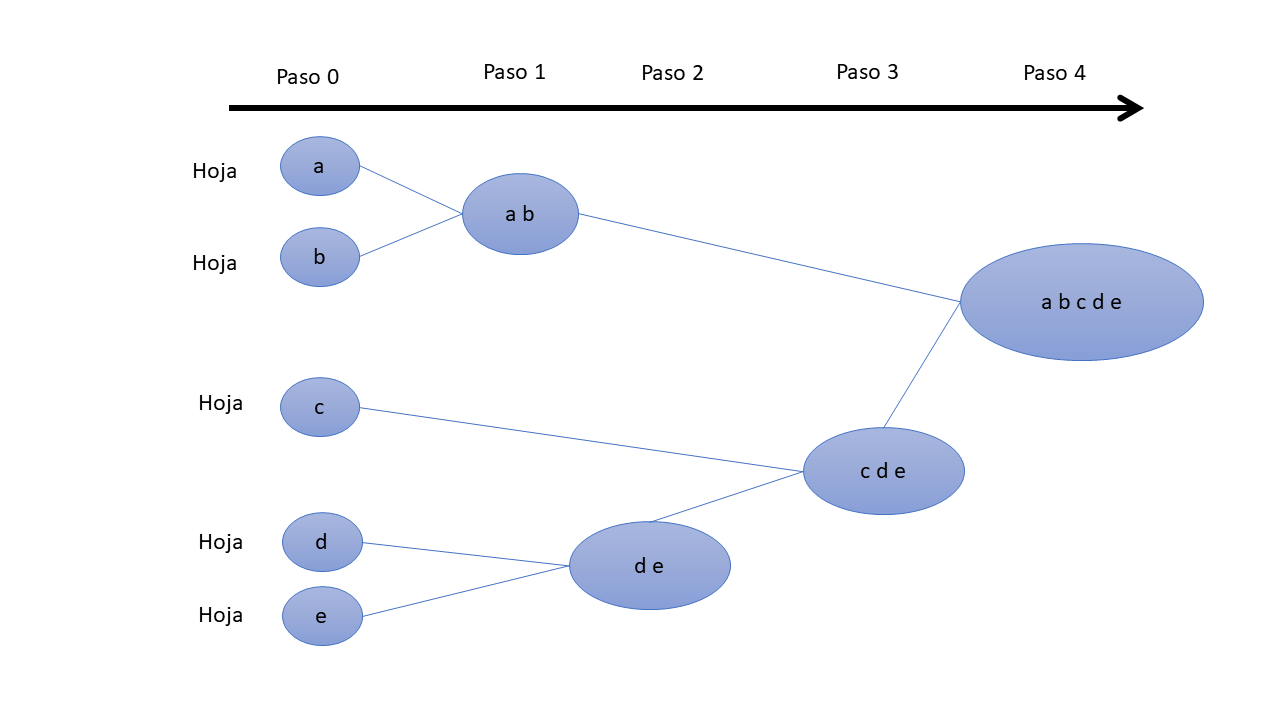
Proceso: Comienza con cada observación como un grupo (hojas y ramas). Los clusters más similares se fusionan sucesivamente hasta que solo queda un solo cluster grande (raíz).
Ventaja: Identifica bien los pequeños grupos.
En la práctica, el método aglomerativo es más común debido a su simplicidad y eficiencia.
Divisivo (top-down):
Proceso: Comienza con todos los objetos en un grupo (raíz) y divide los grupos más heterogéneos sucesivamente hasta que todas las observaciones están en su propio grupo.
Ventaja: Identifica bien los grandes grupos.
El clustering jerárquico no requiere especificar el número de clusters previamente y brinda una representación visual atractiva conocida como dendrograma.
Pasos#
Jerárquico_y_no#
Pasos del Clustering Jerárquico Aglomerativo:
1. Inicialización: Cada observación es un cluster.
2. Cálculo de distancias: Se calculan las distancias entre todos los clusters utilizando una métrica de distancia (ejemplo, Euclidiana, Manhattan).
3. Combinación de clusters: Se encuentran los dos clusters más cercanos y se combinan en un nuevo cluster.
4. Actualización de distancias: Se recalculan las distancias entre el nuevo cluster y los clusters existentes.
5. Repetición: Se repiten los pasos 3 y 4 hasta que todos los puntos están en un solo cluster.
Métodos para calcular la distancia entre clusters:
Enlace sencillo (Single Linkage): La distancia mínima entre puntos en dos clusters.
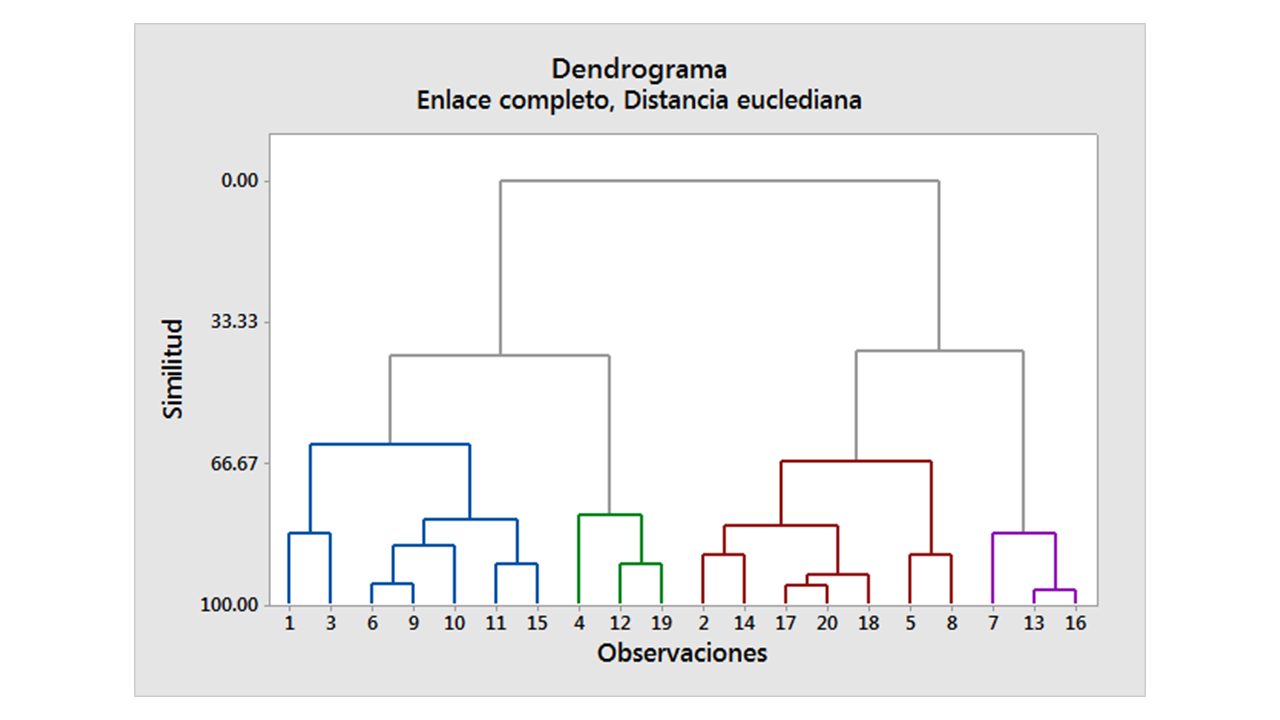
Enlace completo (Complete Linkage): La distancia máxima entre puntos en dos clusters.
Enlace promedio (Average Linkage): El promedio de todas las distancias entre puntos en los dos clusters.
Centroide (Centroid Linkage): La distancia entre los centroides de dos clusters.
Método Ward: Minimiza la varianza dentro de cada cluster.
Dendrograma:#
El dendrograma es un diagrama de árbol que muestra cómo se combinan los clusters. Es una herramienta esencial para visualizar el resultado del clustering jerárquico.
El eje y representa la distancia o disimilitud entre los clusters, y el eje x representa las observaciones o puntos de datos.
Pasos del Algoritmo Aglomerativo:
Preparación de los datos: Recopilar y normalizar los datos si es necesario.
Cálculo de distancias: Utilizar una función de distancia (ejemplo, Euclidiana) para calcular la similitud o disimilitud entre cada par de objetos en el conjunto de datos.
Función de vinculación: Agrupar objetos en un árbol jerárquico utilizando la información de distancia.Las funciones comunes de vinculación incluyen:
Enlace sencillo (Single Linkage): La distancia mínima entre puntos en dos clusters.
Enlace completo (Complete Linkage): La distancia máxima entre puntos en dos clusters.
Enlace promedio (Average Linkage): El promedio de todas las distancias entre puntos en los dos clusters.
Método Ward: Minimiza la varianza dentro de cada cluster.
Formación del Árbol: Combinar los clusters más similares en nuevos clusters más grandes repetidamente hasta que todos los objetos estén en un solo cluster.
Corte del Árbol: Determinar dónde cortar el dendrograma para crear una partición de los datos en clusters.
Por defecto scikit-learn en el cluster aglomerativo usa 'ward'
por defecto cómo método de vinculación.
linkage='ward'
Aunque tiene los siguientes:
‘ward’, ‘complete’, ‘average’, ‘single’
Para el cálculo de las distancias, scikit-learn en el cluster
aglomerativo usa 'euclidean' por defecto.
metric='euclidean'
Aunque tiene los siguientes:
“manhattan”, “cosine”
Dendograma#
Medidas de Similitud:
Existen varios métodos para calcular la similitud entre objetos. Las medidas de distancia comunes incluyen:
Distancia Euclidiana: Distancia directa en el espacio euclidiano.
Distancia Manhattan: Suma de las diferencias absolutas entre las coordenadas.
Distancia de Minkowski: Generalización de la distancia Euclidiana y Manhattan.
Distancia Coseno: Mide la similitud del ángulo entre dos vectores.
Vinculación de objetos o grupos:
La función de vinculación utiliza la matriz de distancia para agrupar objetos en clusters. Este proceso se repite hasta que todos los objetos están en un solo árbol jerárquico.
Verificación del Árbol de Agrupamiento:#
Para evaluar qué tan bien el árbol generado refleja los datos originales, se puede calcular la correlación entre las distancias cofenéticas (distancias en el árbol) y las distancias originales. Una alta correlación indica una buena representación.
Interpretación de la correlación Coefénica:
Alta correlación (cerca de 1): Indica que el dendrograma refleja bien las distancias originales entre los puntos de datos. El clustering jerárquico es una buena representación de las similitudes en los datos.
Media correlación (aproximadamente 0,5): Indica una representación moderada de las distancias originales. Puede haber alguna pérdida de información, pero el dendrograma todavía tiene una correspondencia aceptable con los datos originales.
Baja correlación (cerca de 0): Indica que el dendrograma no representa bien las distancias originales entre los puntos de datos. El clustering jerárquico no está capturando correctamente las relaciones entre los datos.
Posibles causas de una baja correlación coefénica:
Datos altamente ruidosos: Los datos pueden tener mucho ruido, lo que dificulta encontrar una estructura clara.
Método de vinculación inadecuado: El método de vinculación utilizado (por ejemplo, Ward, enlace sencillo, enlace completo) puede no ser adecuado para la estructura de los datos.
Características inapropiadas: Las características utilizadas para calcular las distancias pueden no ser representativas de las similitudes reales entre los puntos de datos.
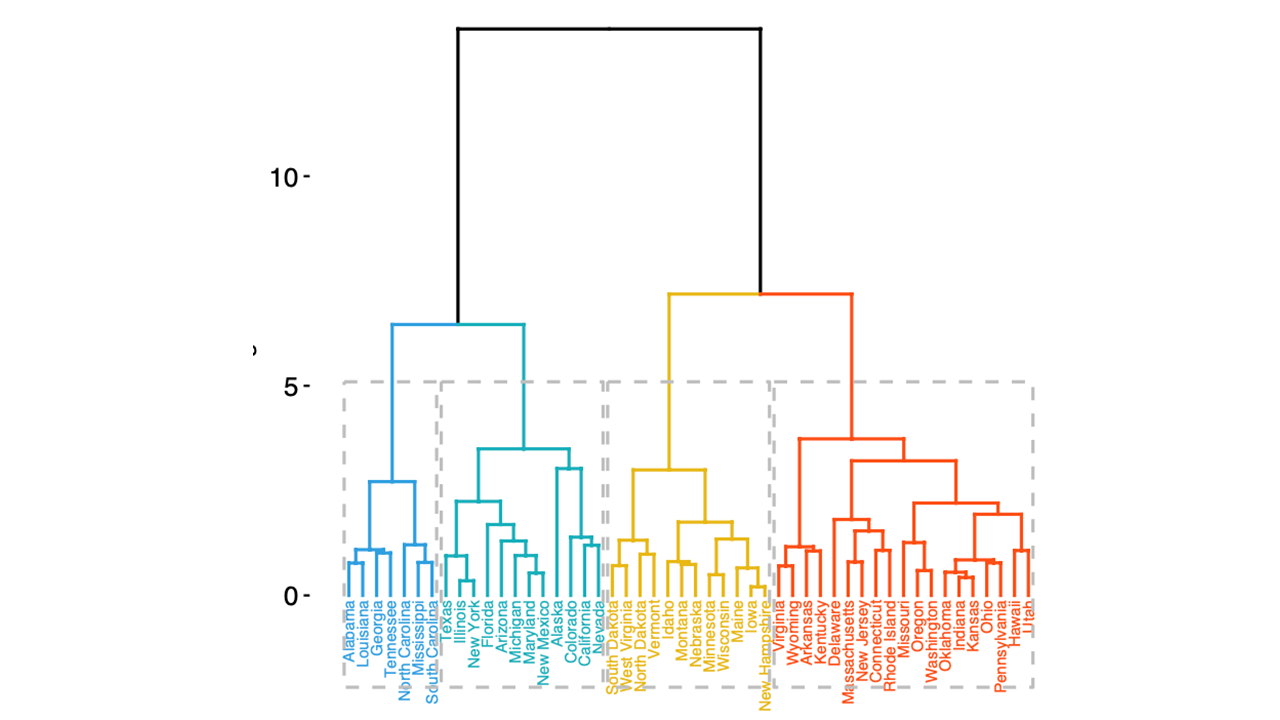
Corte del árbol:#
No existe un criterio único y claro para determinar el punto de corte del dendrograma. Se pueden utilizar métodos similares a los empleados en K-means, como el análisis de la suma de las distancias cuadráticas dentro de los clusters (inercia) o el método del codo. Además, es posible definir un número de clusters a priori o establecer un nivel máximo de disimilitud aceptable para realizar el corte.
Dendograma_cortado#