Ejemplo DBSCAN#
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import DBSCAN
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import silhouette_score
import seaborn as sns
Generar datos en forma de espiral:#
def generate_spiral_data(n_points, noise=0.5):
theta = np.sqrt(np.random.rand(n_points)) * 2 * np.pi # Random theta
r_a = 2 * theta + np.pi # Radius for spiral A
data_a = np.array([np.cos(theta) * r_a, np.sin(theta) * r_a]).T
data_a += np.random.randn(n_points, 2) * noise
r_b = -2 * theta - np.pi # Radius for spiral B
data_b = np.array([np.cos(theta) * r_b, np.sin(theta) * r_b]).T
data_b += np.random.randn(n_points, 2) * noise
res_a = np.append(data_a, np.zeros((n_points, 1)), axis=1)
res_b = np.append(data_b, np.ones((n_points, 1)), axis=1)
res = np.append(res_a, res_b, axis=0)
np.random.shuffle(res)
return res[:, :2], res[:, 2]
# Generar datos
X, y = generate_spiral_data(1000)
# Visualizar los datos y los clusters
plt.figure(figsize=(10, 7))
plt.scatter(X[:, 0], X[:, 1], cmap='rainbow', alpha=0.7, edgecolors='b')
plt.title("Espiral")
plt.xlabel("X1")
plt.ylabel("X2")
plt.show()

Aplicar DBSCAN#
# Estandarizar los datos
X = StandardScaler().fit_transform(X)
# Aplicar DBSCAN
db = DBSCAN(eps=0.3, min_samples=10).fit(X)
labels = db.labels_
Clusters:
set(labels)
{0, 1}
En caso de existir ruido, puntos de ruido, el cluster se denota -1
# Número de clusters en las etiquetas, ignorando el ruido si está presente.
n_clusters_ = len(set(labels)) - (1 if -1 in labels else 0) # Tener en cuenta que el cluster -1 es el ruido.
n_noise_ = list(labels).count(-1)
print(f'Número de clusters: {n_clusters_}')
print(f'Número de puntos de ruido: {n_noise_}')
Número de clusters: 2
Número de puntos de ruido: 0
# Colores para los diferentes clusters, y el color negro para el ruido.
unique_labels = set(labels)
colors = [plt.cm.Spectral(each) for each in np.linspace(0, 1, len(unique_labels))]
dbscan_labels = db.fit_predict(X)
# Calcular el índice de silueta
silhouette_scores = silhouette_score(X, dbscan_labels)
print(f'Puntuación de Silueta: {silhouette_scores:.4f}')
plt.figure(figsize=(10, 7))
for k, col in zip(unique_labels, colors):
if k == -1:
# Negro es usado para el ruido.
col = [0, 0, 0, 1] # RGB y alfa
class_member_mask = (labels == k)
xy = X[class_member_mask & (labels == k)]
plt.plot(xy[:, 0], xy[:, 1], 'o', markerfacecolor=tuple(col),
markeredgecolor='k', markersize=6)
plt.title('Clustering DBSCAN')
plt.xlabel('X1')
plt.ylabel('X2')
plt.show()
Puntuación de Silueta: 0.1849
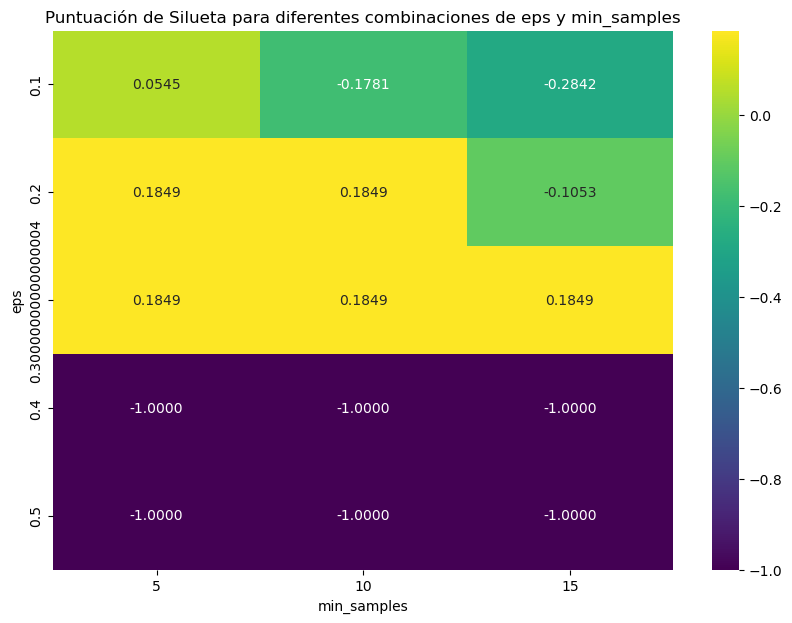
Determinar los valores de eps y min_samples:#
# Definir los valores de eps y min_samples para evaluar
eps_values = np.arange(0.1, 0.6, 0.1)
min_samples_values = range(5, 16, 5)
# Almacenar las puntuaciones de silueta
results = []
for eps in eps_values:
for min_samples in min_samples_values:
db = DBSCAN(eps=eps, min_samples=min_samples)
dbscan_labels = db.fit_predict(X)
if len(set(dbscan_labels)) > 1: # Asegurarse de que hay más de un cluster
silhouette_avg = silhouette_score(X, dbscan_labels)
results.append((eps, min_samples, silhouette_avg))
print(f'eps: {eps}, min_samples: {min_samples}, Puntuación de Silueta: {silhouette_avg:.4f}')
else:
results.append((eps, min_samples, -1))
print(f'eps: {eps}, min_samples: {min_samples}, Puntuación de Silueta: No aplicable')
# Convertir los resultados a un DataFrame
import pandas as pd
results_df = pd.DataFrame(results, columns=['eps', 'min_samples', 'silhouette_score'])
# Visualizar los resultados en un heatmap
pivot_table = results_df.pivot('eps', 'min_samples', 'silhouette_score')
plt.figure(figsize=(10, 7))
sns.heatmap(pivot_table, annot=True, fmt=".4f", cmap='viridis')
plt.title('Puntuación de Silueta para diferentes combinaciones de eps y min_samples')
plt.show()
eps: 0.1, min_samples: 5, Puntuación de Silueta: 0.0545
eps: 0.1, min_samples: 10, Puntuación de Silueta: -0.1781
eps: 0.1, min_samples: 15, Puntuación de Silueta: -0.2842
eps: 0.2, min_samples: 5, Puntuación de Silueta: 0.1849
eps: 0.2, min_samples: 10, Puntuación de Silueta: 0.1849
eps: 0.2, min_samples: 15, Puntuación de Silueta: -0.1053
eps: 0.30000000000000004, min_samples: 5, Puntuación de Silueta: 0.1849
eps: 0.30000000000000004, min_samples: 10, Puntuación de Silueta: 0.1849
eps: 0.30000000000000004, min_samples: 15, Puntuación de Silueta: 0.1849
eps: 0.4, min_samples: 5, Puntuación de Silueta: No aplicable
eps: 0.4, min_samples: 10, Puntuación de Silueta: No aplicable
eps: 0.4, min_samples: 15, Puntuación de Silueta: No aplicable
eps: 0.5, min_samples: 5, Puntuación de Silueta: No aplicable
eps: 0.5, min_samples: 10, Puntuación de Silueta: No aplicable
eps: 0.5, min_samples: 15, Puntuación de Silueta: No aplicable