Preparación y preprocesamiento de datos#
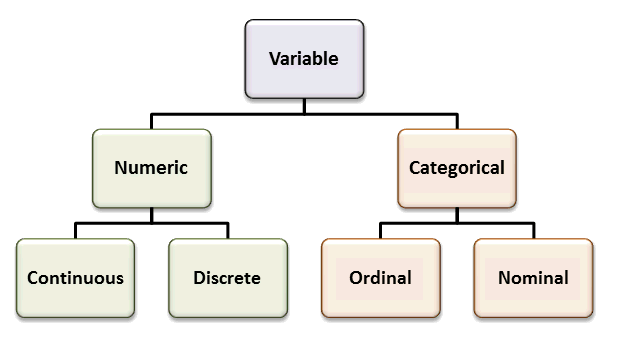
En Machine Learning, los datos de entrada pueden ser de diferentes tipos. Conocer el tipo de dato es fundamental para elegir el preprocesamiento y el modelo adecuado.
Tipos principales#
Numéricos (cuantitativos):
Son valores que representan cantidades medibles.
Continuos: pueden tomar cualquier valor en un rango. Ejemplo: altura, peso, temperatura.
Discretos: toman valores enteros. Ejemplo: número de hijos, cantidad de ventas.
Categóricos (cualitativos):
Variables nominales: No tienen un orden natural entre sus categorías.
Ejemplos:
Color: Rojo, Azul, Verde.
País: Colombia, México, Chile.
Género: Masculino, Femenino.
Conversión numérica (One-Hot Encoding):
Color
Color_Rojo
Color_Azul
Color_Verde
Rojo
1
0
0
Azul
0
1
0
Verde
0
0
1
Variables ordinales: Tienen un orden lógico entre sus categorías.
Ejemplos:
Nivel educativo: Bajo, Medio, Alto.
Talla de ropa: S, M, L, XL.
Satisfacción: Mala, Regular, Buena, Excelente.
Conversión numérica (Ordinal Encoding):
Nivel educativo
Codificación
Bajo
1
Medio
2
Alto
3
Otro ejemplo:
Talla
Codificación
S
1
M
2
L
3
XL
4
DataTypes1#
Codificación de variables categóricas:#
Las variables categóricas representan información no numérica, como el color, el país o el tipo de producto. La mayoría de los algoritmos de Machine Learning trabajan únicamente con datos numéricos, por lo que es necesario codificarlas.
¿Por qué codificar?
Los modelos no pueden interpretar directamente texto o etiquetas como “Rojo” o “Alto”.
La codificación traduce estas categorías a valores numéricos que los algoritmos puedan procesar.
La forma de codificación influye en el rendimiento y la interpretación del modelo.
Tipos de codificación:
Codificación ordinal:
Se asigna un número entero a cada categoría respetando un orden lógico.
Ejemplo: Nivel educativo — Bajo = 1, Medio = 2, Alto = 3.
Nivel educativo
Codificación
Bajo
1
Medio
2
Alto
3
Útil para variables ordinales donde el orden importa.
Talla
Codificación
S
1
M
2
L
3
XL
4
No es necesario crear variables booleanas, ya que el orden tiene significado.
One-Hot Encoding (Variables Dummy):
Convierte cada categoría en una columna booleana (0/1). Útil para variables nominales (sin orden). • Crea una nueva columna binaria (0 o 1) para cada categoría posible.
Color
Color_Rojo
Color_Azul
Color_Verde
Rojo
1
0
0
Azul
0
1
0
Verde
0
0
1
No es correcto asignar números enteros arbitrarios (rojo=0, Azul=1, Verde=2) porque:
Introduce un orden ficticio.
Hace que el modelo suponga distancias entre categorías que no existen.
Multicolinealidad en modelos lineales:
En modelos lineales (como regresión lineal o logística), usar One-Hot Encoding con todas las categorías puede generar multicolinealidad: una dependencia perfecta entre variables.
Solución: eliminar una de las columnas creadas (llamado “drop first”).
Ejemplo: para
Rojo,Azul,Verde, se eliminanRojoy se dejanAzulyVerde.
En otros modelos (árboles de decisión, random forest, XGBoost, redes neuronales) no es necesario eliminar columnas, ya que no se ven afectados por la multicolinealidad de la misma forma.
Resumen:
Nominales → usar One-Hot Encoding para evitar introducir un orden falso.
Ordinales → usar Ordinal Encoding respetando el orden natural de las categorías.
Ejemplo:#
En este ejemplo se codifican tre variables categóricas:
Nivel_educacion (ordinal).
Género (nominal): Cuando Género tiene solo dos categorías, puede representarse directamente como variable binaria sin necesidad de crear más de una columna.
Compra (nominal): Al tener solo dos categorías, puede codificarse directamente como variable binaria.
Color (nominal): Tiene más de dos categorías.
import pandas as pd
# Datos de ejemplo
df = pd.DataFrame({
'Género': ['M', 'F', 'F', 'M', 'M'],
'Nivel_educacion': ['Bajo', 'Medio', 'Alto', 'Medio', 'Bajo'],
'Color': ['Rojo', 'Azul', 'Verde', 'Rojo', 'Azul'],
'Compra': ['Sí', 'No', 'Sí', 'No', 'Sí']
})
print("Datos originales:")
df
Datos originales:
| Género | Nivel_educacion | Color | Compra | |
|---|---|---|---|---|
| 0 | M | Bajo | Rojo | Sí |
| 1 | F | Medio | Azul | No |
| 2 | F | Alto | Verde | Sí |
| 3 | M | Medio | Rojo | No |
| 4 | M | Bajo | Azul | Sí |
Ejemplo con scikit-learn:#
Variables nominales:
OneHotEncoder: transforma variables categóricas en columnas binarias (0/1).
drop='first': elimina la primera categoría de cada variable para evitar multicolinealidad en modelos lineales o para las que tienen solo dos categorías cómo Género y Compra.sparse=False: devuelve un arreglo denso (numpy.ndarray) en lugar de una matriz dispersa, lo que facilita convertirlo en un DataFrame.
Género y compra donde deben quedar en una sola columna binaria,
por tanto, usar drop=first'.
Para Color se aplicará también drop=first' por si se usarán
modelos lineales y así evitar la muticolinealidad.
encoder_drop.get_feature_names_out(input_features): Devuelve los
nombres de las columnas generadas tras la codificación.
from sklearn.preprocessing import OneHotEncoder, OrdinalEncoder
# ---- One-Hot Encoding eliminando una columna para las variables nominales con dos categorías y para Color para evitar multicolinealidad ----
encoder_drop = OneHotEncoder(drop='first', sparse=False)
encoded_drop = encoder_drop.fit_transform(df[['Género', 'Color', 'Compra']])
cols_drop = encoder_drop.get_feature_names_out(['Género', 'Color', 'Compra'])
df_encoded_drop = pd.DataFrame(encoded_drop, columns=cols_drop)
df_encoded_drop
| Género_M | Color_Rojo | Color_Verde | Compra_Sí | |
|---|---|---|---|---|
| 0 | 1.0 | 1.0 | 0.0 | 1.0 |
| 1 | 0.0 | 0.0 | 0.0 | 0.0 |
| 2 | 0.0 | 0.0 | 1.0 | 1.0 |
| 3 | 1.0 | 1.0 | 0.0 | 0.0 |
| 4 | 1.0 | 0.0 | 0.0 | 1.0 |
Para Nivel educación por ser ordinal donde el orden tiene
importancia, se usará OrdinalEncoder.
# Codificación ordinal (respeta el orden) para 'Nivel_educacion'
encoder_ord = OrdinalEncoder(categories=[['Bajo', 'Medio', 'Alto']])
encoded_ord = encoder_ord.fit_transform(df[['Nivel_educacion']])
df_encoded_ord = pd.DataFrame(encoded_ord, columns=['Nivel_educacion'])
df_encoded_ord
| Nivel_educacion | |
|---|---|
| 0 | 0.0 |
| 1 | 1.0 |
| 2 | 2.0 |
| 3 | 1.0 |
| 4 | 0.0 |
# Resultados elimando una columna a Color:
pd.concat([df_encoded_drop, df_encoded_ord], axis=1)
| Género_M | Color_Rojo | Color_Verde | Compra_Sí | Nivel_educacion | |
|---|---|---|---|---|---|
| 0 | 1.0 | 1.0 | 0.0 | 1.0 | 0.0 |
| 1 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 |
| 2 | 0.0 | 0.0 | 1.0 | 1.0 | 2.0 |
| 3 | 1.0 | 1.0 | 0.0 | 0.0 | 1.0 |
| 4 | 1.0 | 0.0 | 0.0 | 1.0 | 0.0 |
# ---- One-Hot Encoding eliminando una columna para las variables nominales con dos categorías----
encoder_drop = OneHotEncoder(drop='first', sparse=False)
encoded_drop = encoder_drop.fit_transform(df[['Género', 'Compra']])
cols_drop = encoder_drop.get_feature_names_out(['Género', 'Compra'])
df_encoded_drop = pd.DataFrame(encoded_drop, columns=cols_drop)
df_encoded_drop
| Género_M | Compra_Sí | |
|---|---|---|
| 0 | 1.0 | 1.0 |
| 1 | 0.0 | 0.0 |
| 2 | 0.0 | 1.0 |
| 3 | 1.0 | 0.0 |
| 4 | 1.0 | 1.0 |
# ---- One-Hot Encoding para Color sin eliminar columnas ----
encoder_full = OneHotEncoder(sparse=False)
encoded_full = encoder_full.fit_transform(df[['Color']])
cols_full = encoder_full.get_feature_names_out(['Color'])
df_encoded_full = pd.DataFrame(encoded_full, columns=cols_full)
df_encoded_full
| Color_Azul | Color_Rojo | Color_Verde | |
|---|---|---|---|
| 0 | 0.0 | 1.0 | 0.0 |
| 1 | 1.0 | 0.0 | 0.0 |
| 2 | 0.0 | 0.0 | 1.0 |
| 3 | 0.0 | 1.0 | 0.0 |
| 4 | 1.0 | 0.0 | 0.0 |
# Resultados sin eliminar una columna a Color:
pd.concat([df_encoded_drop, df_encoded_full, df_encoded_ord], axis=1)
| Género_M | Compra_Sí | Color_Azul | Color_Rojo | Color_Verde | Nivel_educacion | |
|---|---|---|---|---|---|---|
| 0 | 1.0 | 1.0 | 0.0 | 1.0 | 0.0 | 0.0 |
| 1 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 1.0 |
| 2 | 0.0 | 1.0 | 0.0 | 0.0 | 1.0 | 2.0 |
| 3 | 1.0 | 0.0 | 0.0 | 1.0 | 0.0 | 1.0 |
| 4 | 1.0 | 1.0 | 1.0 | 0.0 | 0.0 | 0.0 |
Ejemplo de codificación de variables categóricas solo con pandas:#
# Datos de ejemplo
df = pd.DataFrame({
'Género': ['M', 'F', 'F', 'M', 'M'],
'Nivel_educacion': ['Bajo', 'Medio', 'Alto', 'Medio', 'Bajo'],
'Color': ['Rojo', 'Azul', 'Verde', 'Rojo', 'Azul'],
'Compra': ['Sí', 'No', 'Sí', 'No', 'Sí']
})
print("Datos originales:")
df
Datos originales:
| Género | Nivel_educacion | Color | Compra | |
|---|---|---|---|---|
| 0 | M | Bajo | Rojo | Sí |
| 1 | F | Medio | Azul | No |
| 2 | F | Alto | Verde | Sí |
| 3 | M | Medio | Rojo | No |
| 4 | M | Bajo | Azul | Sí |
``pd.get_dummies()``: crea columnas binarias (0/1) a partir de variables categóricas.
``drop_first=True``: elimina la primera categoría de cada variable para evitar multicolinealidad en modelos lineales.
``drop_first=False``: mantiene todas las categorías, útil para modelos no lineales.
``.map({‘Sí’: 1, ‘No’: 0})``: convierte una variable binaria en formato texto a valores 0 y 1.
# Codificación ordinal manual para 'Nivel_educacion':
orden_edu = {'Bajo': 0, 'Medio': 1, 'Alto': 2}
df_ord = pd.DataFrame(df['Nivel_educacion'].map(orden_edu), columns=['Nivel_educacion'])
df_ord
| Nivel_educacion | |
|---|---|
| 0 | 0 |
| 1 | 1 |
| 2 | 2 |
| 3 | 1 |
| 4 | 0 |
# --- One-Hot Encoding eliminando una columna: ---
df_onehot_drop = pd.get_dummies(df[['Género', 'Compra']], drop_first=True)
df_onehot_drop
| Género_M | Compra_Sí | |
|---|---|---|
| 0 | 1 | 1 |
| 1 | 0 | 0 |
| 2 | 0 | 1 |
| 3 | 1 | 0 |
| 4 | 1 | 1 |
# --- One-Hot Encoding eliminado primera columna (para modelos lineales) ---
df_onehot_full = pd.get_dummies(df[['Color']], drop_first=True)
df_onehot_full
| Color_Rojo | Color_Verde | |
|---|---|---|
| 0 | 1 | 0 |
| 1 | 0 | 0 |
| 2 | 0 | 1 |
| 3 | 1 | 0 |
| 4 | 0 | 0 |
# Resultados
pd.concat([df_onehot_drop, df_onehot_full, df_ord], axis=1)
| Género_M | Compra_Sí | Color_Rojo | Color_Verde | Nivel_educacion | |
|---|---|---|---|---|---|
| 0 | 1 | 1 | 1 | 0 | 0 |
| 1 | 0 | 0 | 0 | 0 | 1 |
| 2 | 0 | 1 | 0 | 1 | 2 |
| 3 | 1 | 0 | 1 | 0 | 1 |
| 4 | 1 | 1 | 0 | 0 | 0 |
# --- One-Hot Encoding sin eliminar columnas (para modelos no lineales) ---
df_onehot_full = pd.get_dummies(df[['Color']], drop_first=False)
df_onehot_full
| Color_Azul | Color_Rojo | Color_Verde | |
|---|---|---|---|
| 0 | 0 | 1 | 0 |
| 1 | 1 | 0 | 0 |
| 2 | 0 | 0 | 1 |
| 3 | 0 | 1 | 0 |
| 4 | 1 | 0 | 0 |
# Resultados
pd.concat([df_onehot_drop, df_onehot_full, df_ord], axis=1)
| Género_M | Compra_Sí | Color_Azul | Color_Rojo | Color_Verde | Nivel_educacion | |
|---|---|---|---|---|---|---|
| 0 | 1 | 1 | 0 | 1 | 0 | 0 |
| 1 | 0 | 0 | 1 | 0 | 0 | 1 |
| 2 | 0 | 1 | 0 | 0 | 1 | 2 |
| 3 | 1 | 0 | 0 | 1 | 0 | 1 |
| 4 | 1 | 1 | 1 | 0 | 0 | 0 |
Escalado de variables:#
El escalado de variables es el proceso de transformar los valores numéricos para que estén en un rango o distribución específica.
Se utiliza porque muchos algoritmos de Machine Learning son sensibles a la magnitud de las variables, y sin escalado, las variables con valores más grandes pueden dominar el modelo.
Ejemplos de modelos sensibles al escalado: regresión logística, SVM, KNN, redes neuronales, PCA.
Modelos poco sensibles al escalado: árboles de decisión, random forest, XGBoost (basados en árboles).
¿Por qué escalar?
Evita que variables con rangos muy diferentes tengan mayor influencia en el modelo.
Acelera la convergencia de algoritmos de optimización como gradiente descendente.
Mejora la estabilidad numérica de los cálculos.
Alternativas de escalado:#
1. Min-Max Scaling (Normalización):
Transforma los datos a un rango fijo, comúnmente [0, 1].
Fórmula:
Ventajas:
Mantiene la forma de la distribución original.
Útil cuando se requiere un rango específico (ej. redes neuronales con activación sigmoide).
Desventajas:
Muy sensible a valores atípicos (outliers).
2. Standard Scaling (Estandarización):
Transforma los datos para que tengan media 0 y desviación estándar 1.
Fórmula:
donde \(\mu\) es la media y \(\sigma\) la desviación estándar.
Ventajas:
Menos sensible a cambios de escala que Min-Max.
Útil para algoritmos que asumen datos centrados en 0 (ej. PCA, SVM).
Desventajas:
Puede verse afectado por outliers, aunque menos que Min-Max.
3. Robust Scaling:
Escala los datos usando la mediana y el rango intercuartílico (IQR), lo que lo hace resistente a outliers.
Fórmula:
Ventajas:
Robusto ante outliers.
Desventajas:
No garantiza un rango fijo como [0, 1].
4. MaxAbs Scaling:
Escala los datos dividiendo por el valor absoluto máximo.
Fórmula:
Ventajas:
Mantiene la dispersión de los datos.
Útil cuando los datos ya están centrados en 0 y se quiere solo ajustar magnitudes.
Desventajas:
Sensible a outliers.
Alternativa más común:
La estandarización (StandardScaler) es la más usada en Machine
Learning, especialmente para algoritmos lineales y métodos basados en
distancia, porque centra los datos y les da varianza unitaria.
¿El escalado cambia las propiedades estadísticas de las variables?#
Sí, al aplicar métodos como MinMaxScaler o StandardScaler, las propiedades estadísticas de las variables cambian.
MinMaxScaler:
Media: cambia, ya que los valores se ajustan a un nuevo rango (por ejemplo, [0, 1]).
Desviación estándar: cambia, porque la dispersión ahora está limitada al rango elegido.
Distribución: la forma relativa de la distribución se mantiene (no altera la relación entre los valores), pero los valores absolutos cambian.
StandardScaler:
Media: pasa a ser 0.
Desviación estándar: pasa a ser 1.
Distribución: la forma de la distribución (asimetría, curtosis) se mantiene, pero se centra y se escala.
Conclusión
El escalado sí modifica medidas como media y desviación estándar.
No altera la forma relativa de la distribución (no cambia qué valor es mayor o menor que otro), pero sí cambia su escala y centro.
Esto es importante para interpretar coeficientes en modelos lineales, ya que estarán en la escala transformada.
¿El escalado cambia las correlaciones entre las variables?#
En general, el escalado no cambia las correlaciones entre variables.
Por qué no cambian:
La correlación de Pearson mide la relación lineal estandarizada entre dos variables.
Si se aplica una transformación lineal (como en MinMaxScaler o StandardScaler), la correlación se mantiene, porque no se altera la proporcionalidad entre los valores.
Cuándo podría cambiar: Si se usan transformaciones no lineales (logaritmo, raíz cuadrada, exponencial, etc.), la relación entre las variables puede cambiar, y por tanto la correlación también.
Ejemplo en Python: MinMaxScaler y StandardScaler:#
import pandas as pd
from sklearn.preprocessing import MinMaxScaler, StandardScaler
# Datos de ejemplo
df = pd.DataFrame({
'Variable_continua': [10, 20, 30, 40, 50],
'Variable_binaria_1': [0, 1, 0, 1, 1],
'Variable_binaria_2': [1, 1, 1, 1, 0]
})
print("Datos originales:")
df
Datos originales:
| Variable_continua | Variable_binaria_1 | Variable_binaria_2 | |
|---|---|---|---|
| 0 | 10 | 0 | 1 |
| 1 | 20 | 1 | 1 |
| 2 | 30 | 0 | 1 |
| 3 | 40 | 1 | 1 |
| 4 | 50 | 1 | 0 |
# --- Min-Max Scaling ---
scaler_minmax = MinMaxScaler()
df_minmax = pd.DataFrame(scaler_minmax.fit_transform(df), columns=df.columns)
df_minmax
| Variable_continua | Variable_binaria_1 | Variable_binaria_2 | |
|---|---|---|---|
| 0 | 0.00 | 0.0 | 1.0 |
| 1 | 0.25 | 1.0 | 1.0 |
| 2 | 0.50 | 0.0 | 1.0 |
| 3 | 0.75 | 1.0 | 1.0 |
| 4 | 1.00 | 1.0 | 0.0 |
# --- Standard Scaling ---
scaler_standard = StandardScaler()
df_standard = pd.DataFrame(scaler_standard.fit_transform(df), columns=df.columns)
df_standard
| Variable_continua | Variable_binaria_1 | Variable_binaria_2 | |
|---|---|---|---|
| 0 | -1.414214 | -1.224745 | 0.5 |
| 1 | -0.707107 | 0.816497 | 0.5 |
| 2 | 0.000000 | -1.224745 | 0.5 |
| 3 | 0.707107 | 0.816497 | 0.5 |
| 4 | 1.414214 | 0.816497 | -2.0 |