Estacionariedad precio del Café#
Precio interno base de compra del café colombiano - Promedio Mensual
Pesos por carga de 125 kg. de café pergamino seco
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
# Cargar el archivo xlsx:
df = pd.read_excel('Precio_interno_cafe.xlsx')
# Corregir nombres de columnas si tienen espacios
df.columns = df.columns.str.strip()
# Convertir 'Fecha' a datetime y usar como índice
df['Fecha'] = pd.to_datetime(df['Fecha'])
df.set_index('Fecha', inplace=True)
# Ordenar por fecha por si acaso
df = df.sort_index()
# Establecer frecuencia explícita para evitar el warning de statsmodels
df.index.freq = df.index.inferred_freq
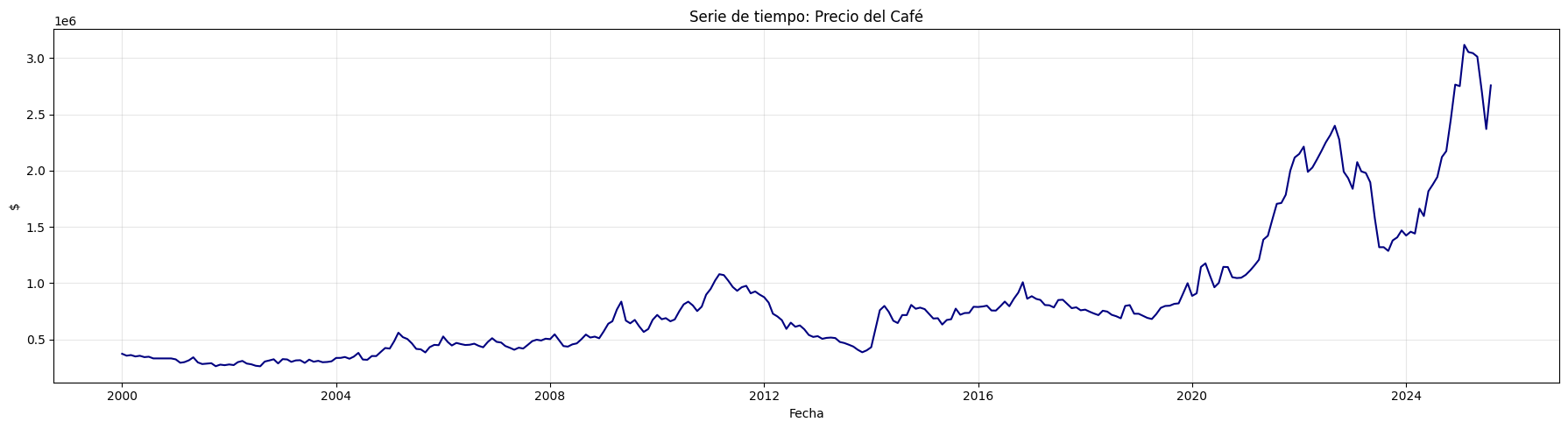
plt.figure(figsize=(18, 5))
plt.plot(df, color='navy')
plt.title("Serie de tiempo: Precio del Café")
plt.xlabel("Fecha")
plt.ylabel("$")
plt.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
df.head()
| Precio | |
|---|---|
| Fecha | |
| 2000-01-01 | 371375.0 |
| 2000-02-01 | 354297.0 |
| 2000-03-01 | 360016.0 |
| 2000-04-01 | 347538.0 |
| 2000-05-01 | 353750.0 |
Descomposición:#
serie = df.copy()
from statsmodels.tsa.seasonal import seasonal_decompose
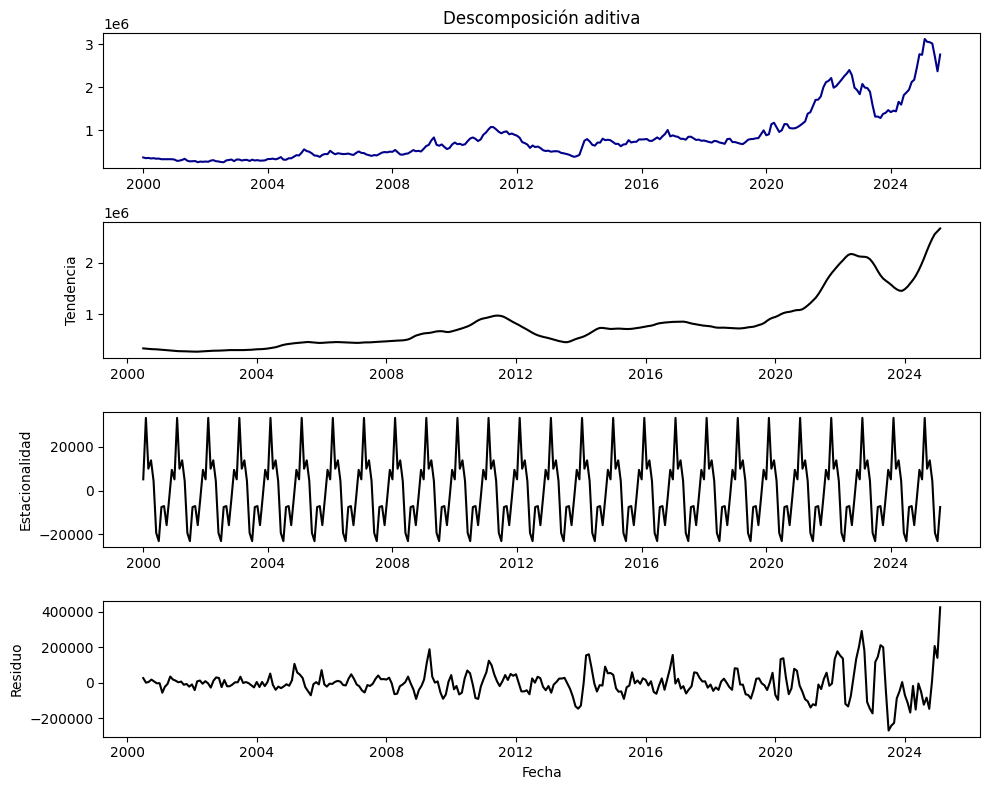
# Descomposición aditiva (periodo de 12 meses)
result_add = seasonal_decompose(serie, model="additive", period=12)
# Graficar
plt.figure(figsize=(10, 8))
plt.subplot(4, 1, 1)
plt.plot(result_add.observed, color="darkblue")
plt.title("Descomposición aditiva")
plt.subplot(4, 1, 2)
plt.plot(result_add.trend, color="black")
plt.ylabel("Tendencia")
plt.subplot(4, 1, 3)
plt.plot(result_add.seasonal, color="black")
plt.ylabel("Estacionalidad")
plt.subplot(4, 1, 4)
plt.plot(result_add.resid, color="black")
plt.ylabel("Residuo")
plt.xlabel("Fecha")
plt.tight_layout()
plt.show()
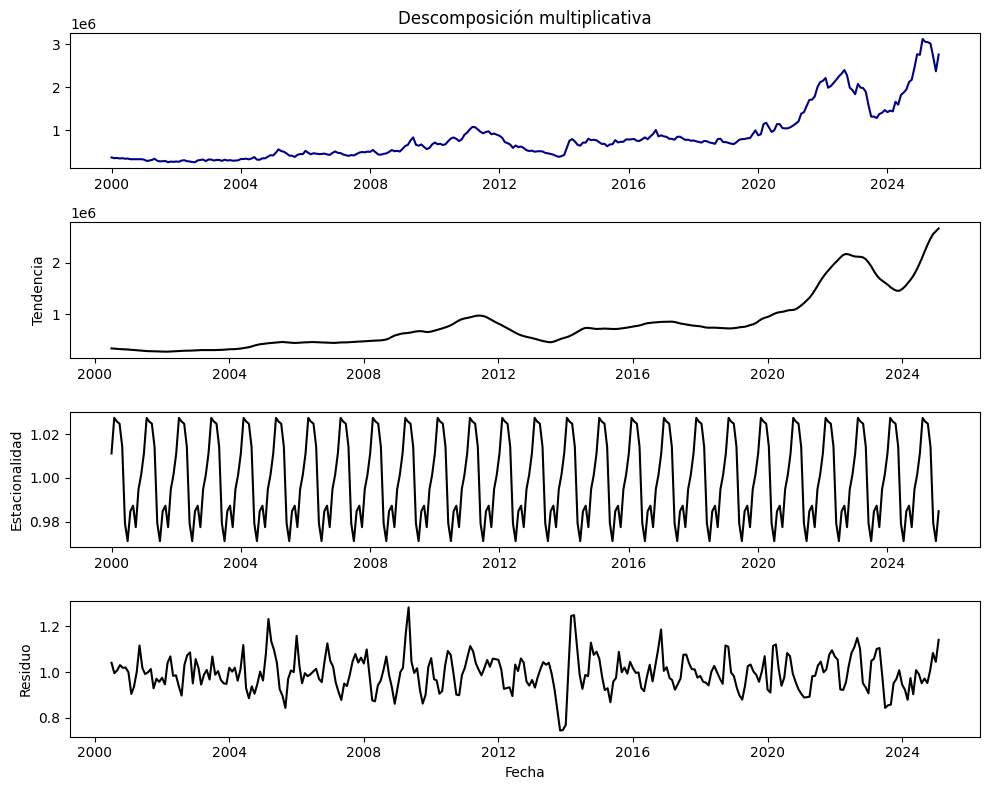
# Descomposición multiplicativa (periodo de 12 meses)
result_add = seasonal_decompose(serie, model="multiplicative", period=12)
# Graficar
plt.figure(figsize=(10, 8))
plt.subplot(4, 1, 1)
plt.plot(result_add.observed, color="darkblue")
plt.title("Descomposición multiplicativa")
plt.subplot(4, 1, 2)
plt.plot(result_add.trend, color="black")
plt.ylabel("Tendencia")
plt.subplot(4, 1, 3)
plt.plot(result_add.seasonal, color="black")
plt.ylabel("Estacionalidad")
plt.subplot(4, 1, 4)
plt.plot(result_add.resid, color="black")
plt.ylabel("Residuo")
plt.xlabel("Fecha")
plt.tight_layout()
plt.show()
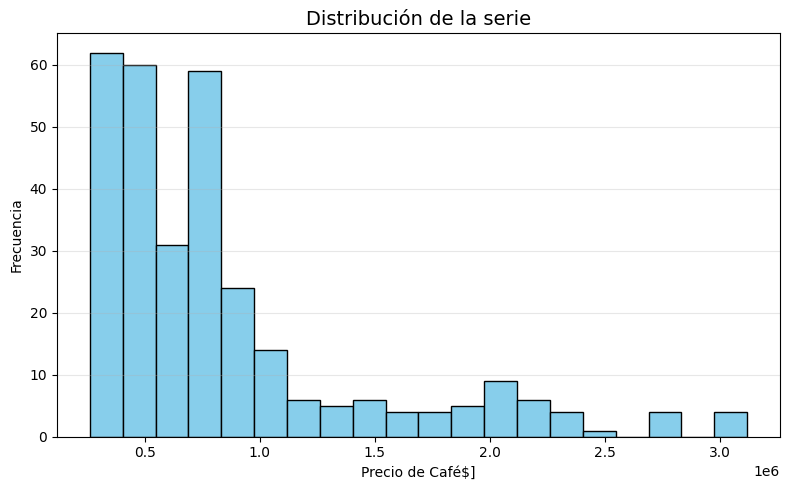
plt.figure(figsize=(8, 5))
plt.hist(serie, bins=20, color='skyblue', edgecolor='black')
plt.title("Distribución de la serie", fontsize=14)
plt.xlabel("Precio de Café$]")
plt.ylabel("Frecuencia")
plt.grid(axis='y', alpha=0.3)
plt.tight_layout()
plt.show()
Cosechas en Colombia:
En Colombia, la cosecha de café generalmente ocurre dos veces al año, con una cosecha principal entre abril y junio y una segunda cosecha o cosecha de mitaca (o traviesa) entre septiembre y diciembre.
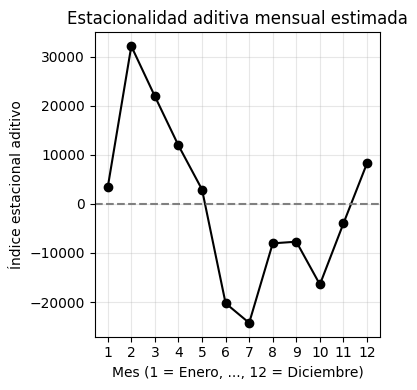
# 1. Calcular la tendencia con media móvil centrada de 12 meses
tendencia = serie.rolling(window=12, center=True).mean()
# 2. Calcular la serie sin tendencia
detrended = serie - tendencia
# 3. Calcular el promedio mensual de la serie sin tendencia
# Agrupar por mes calendario (1=enero, ..., 12=diciembre)
promedio_mensual = detrended.groupby(detrended.index.month).mean()
# 4. Centrar los valores mensuales (que sumen cero)
estacionalidad = promedio_mensual - promedio_mensual.mean()
estacionalidad.index.name = "Mes"
estacionalidad.name = "Índice estacional aditivo"
plt.figure(figsize=(4, 4))
plt.plot(estacionalidad.index, estacionalidad.values, marker='o', linestyle='-', color='black')
plt.axhline(0, color='gray', linestyle='--')
plt.title("Estacionalidad aditiva mensual estimada")
plt.xlabel("Mes (1 = Enero, ..., 12 = Diciembre)")
plt.ylabel("Índice estacional aditivo")
plt.xticks(ticks=range(1, 13))
plt.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
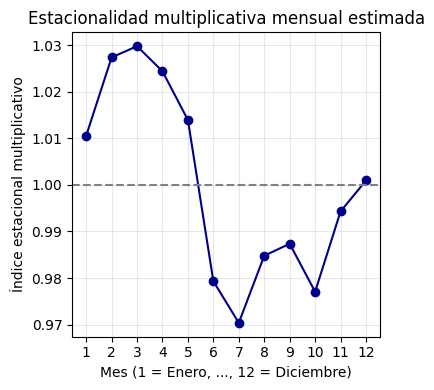
# 1. Calcular la tendencia con media móvil centrada de 12 meses
tendencia = serie.rolling(window=12, center=True).mean()
# 2. Calcular la serie sin tendencia (ahora con división)
detrended = serie / tendencia
# 3. Calcular el promedio mensual de la serie sin tendencia (multiplicativa)
promedio_mensual = detrended.groupby(detrended.index.month).mean()
# 4. Centrar los valores mensuales para que el promedio sea 1 (multiplicativo)
estacionalidad_mult = promedio_mensual / promedio_mensual.mean()
estacionalidad_mult.index.name = "Mes"
estacionalidad_mult.name = "Índice estacional multiplicativo"
# 5. Graficar
plt.figure(figsize=(4, 4))
plt.plot(estacionalidad_mult.index, estacionalidad_mult.values, marker='o', linestyle='-', color='darkblue')
plt.axhline(1, color='gray', linestyle='--')
plt.title("Estacionalidad multiplicativa mensual estimada")
plt.xlabel("Mes (1 = Enero, ..., 12 = Diciembre)")
plt.ylabel("Índice estacional multiplicativo")
plt.xticks(ticks=range(1, 13))
plt.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
Prueba de estacionariedad:#
from statsmodels.tsa.stattools import adfuller
adf_result = adfuller(serie, regression='ctt')
print(f'Estadístico ADF: {adf_result[0]}')
print(f'Valor p: {adf_result[1]}')
# Interpretación del resultado
alpha = 0.05
if adf_result[1] < alpha:
print("Rechazamos la hipótesis nula: La serie es estacionaria.")
else:
print("No podemos rechazar la hipótesis nula: La serie no es estacionaria.")
Estadístico ADF: -2.781278277472542
Valor p: 0.408614276283159
No podemos rechazar la hipótesis nula: La serie no es estacionaria.
Transformaciones:#
Primera diferencia:
# Transformación: diferenciación:
df_diff = serie.diff().dropna()
plt.figure(figsize=(18, 5))
plt.plot(df_diff, color='darkgreen')
plt.title("Serie de tiempo: Precio del Café (primera diferencia)")
plt.xlabel("Fecha")
plt.ylabel("Valor Diferenciado")
plt.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
adf_result = adfuller(df_diff, regression='n') # 'n' para no incluir constante ni tendencia
print(f'Estadístico ADF: {adf_result[0]}')
print(f'Valor p: {adf_result[1]}')
# Interpretación del resultado
alpha = 0.05
if adf_result[1] < alpha:
print("Rechazamos la hipótesis nula: La serie es estacionaria.")
else:
print("No podemos rechazar la hipótesis nula: La serie no es estacionaria.")

Estadístico ADF: -5.573149232135553
Valor p: 7.412548013102314e-08
Rechazamos la hipótesis nula: La serie es estacionaria.
Transformación logarítmica:
# Transformación: Logaritmo
df_log = np.log(serie)
plt.figure(figsize=(18, 5))
plt.plot(df_log, color='darkgreen')
plt.title("Serie de tiempo: Precio del Café (Logaritmo)")
plt.xlabel("Fecha")
plt.ylabel("Log(Valor)")
plt.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
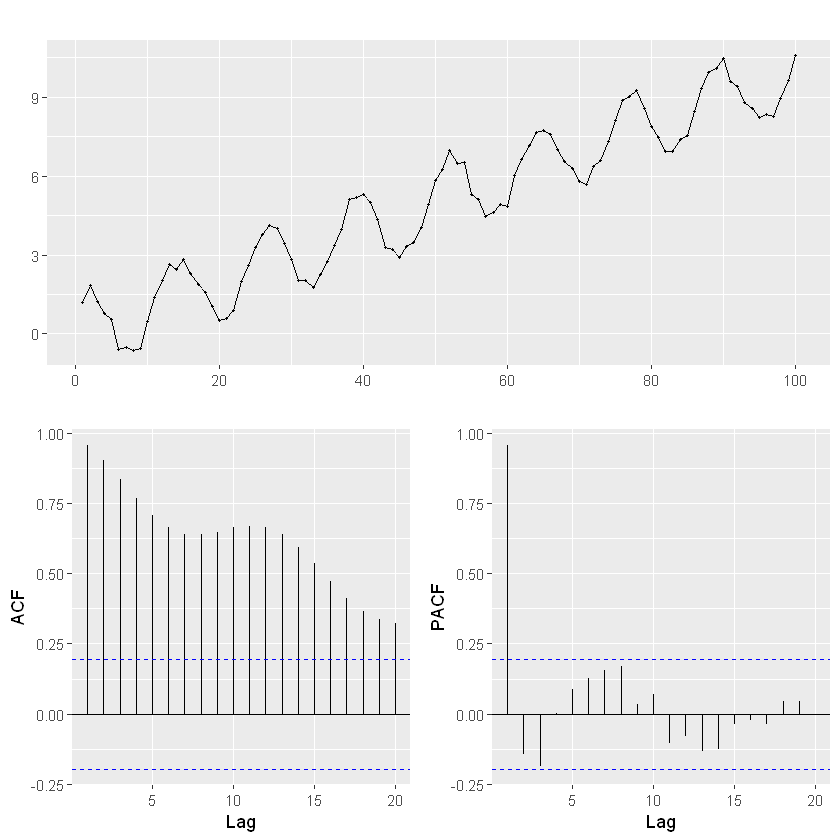
adf_result = adfuller(df_log, regression='ct') # 'ct' Cuando la serie muestra una tendencia lineal creciente o decreciente
print(f'Estadístico ADF: {adf_result[0]}')
print(f'Valor p: {adf_result[1]}')
# Interpretación del resultado
alpha = 0.05
if adf_result[1] < alpha:
print("Rechazamos la hipótesis nula: La serie es estacionaria.")
else:
print("No podemos rechazar la hipótesis nula: La serie no es estacionaria.")
Estadístico ADF: -3.2308799188259503
Valor p: 0.07842224060300443
No podemos rechazar la hipótesis nula: La serie no es estacionaria.
Transformación: diferenciación del logaritmo:
# Transformación: diferenciación del logaritmo
df_log_diff = df_log.diff().dropna()
plt.figure(figsize=(18, 5))
plt.plot(df_log_diff, color='darkgreen')
plt.title("Serie de tiempo: Precio del Café (Diferenciación del Logaritmo)")
plt.xlabel("Fecha")
plt.ylabel("Diferencia del Log(Valor)")
plt.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
adf_result = adfuller(df_log_diff, regression='n') # 'n' para no incluir constante ni tendencia
print(f'Estadístico ADF: {adf_result[0]}')
print(f'Valor p: {adf_result[1]}')
# Interpretación del resultado
alpha = 0.05
if adf_result[1] < alpha:
print("Rechazamos la hipótesis nula: La serie es estacionaria.")
else:
print("No podemos rechazar la hipótesis nula: La serie no es estacionaria.")
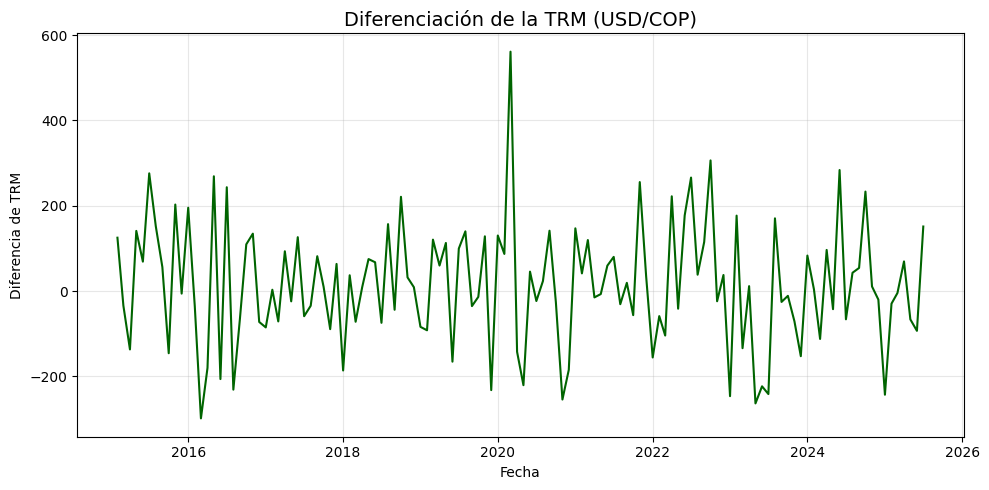
Estadístico ADF: -4.476002005356018
Valor p: 1.0454734547411791e-05
Rechazamos la hipótesis nula: La serie es estacionaria.
Devolver transformaciones:#
1. Diferenciación (primera diferencia):
Transformación:
Para revertir (recuperar la serie original):
Donde \(y_{t-1}\) es el valor original (sin transformar) del periodo anterior.
2. Transformación logarítmica:
Transformación:
Para revertir (recuperar la serie original):
Cuando se combinan transformaciones (ejemplo: primero log, luego diferencia), debes revertir en el orden inverso:
Primero “deshaces” la diferencia,
luego “deshaces” el logaritmo.
Siempre asegúrate de conservar el primer valor original (\(y_0\)) para poder recuperar toda la serie.
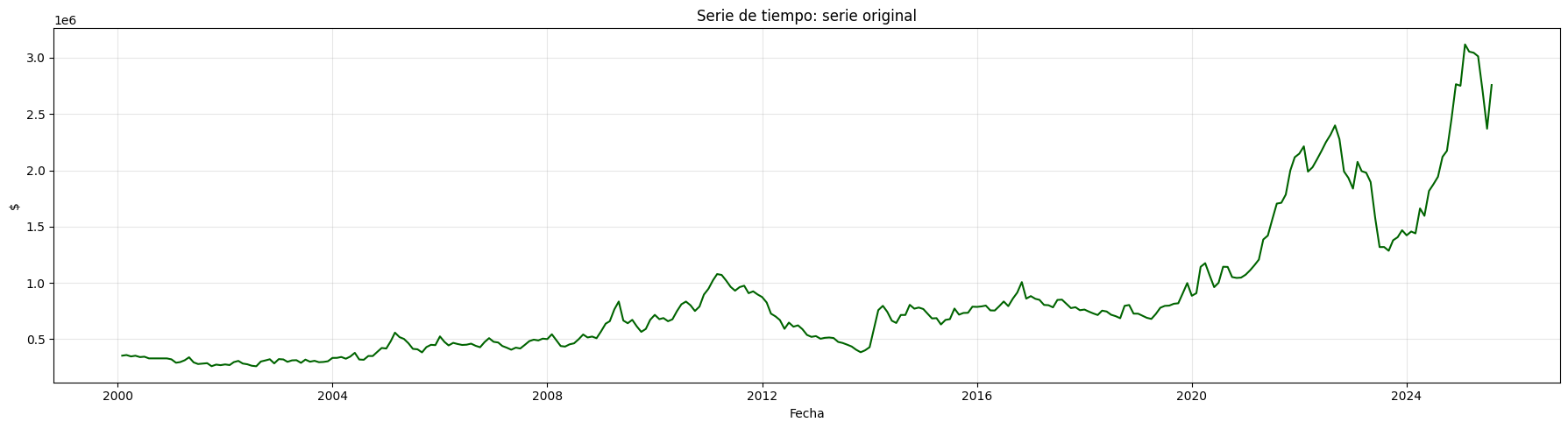
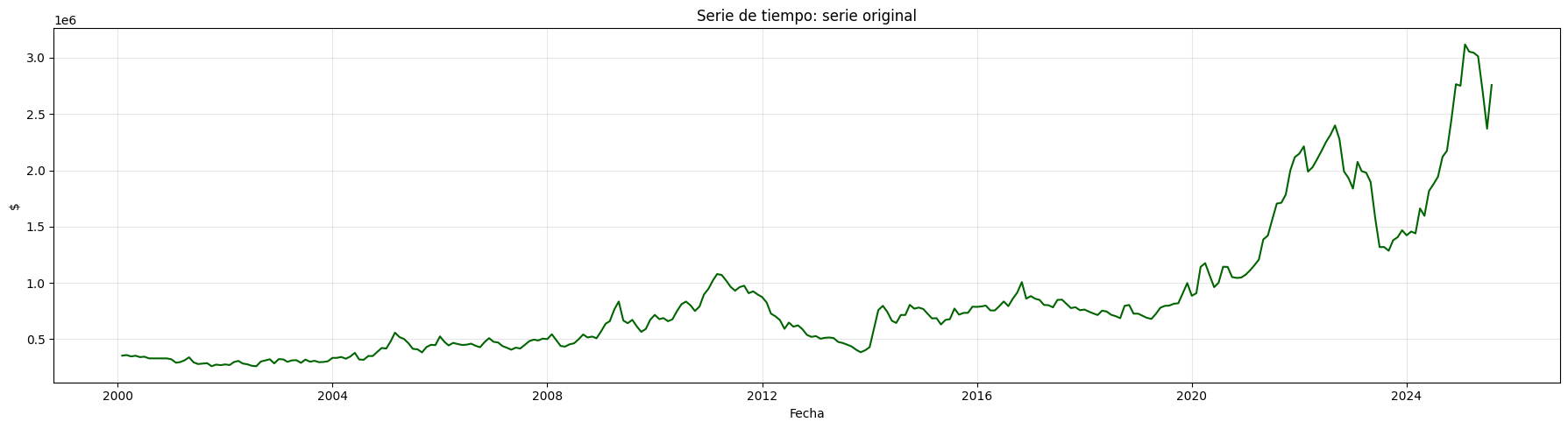
# Recupera la serie original (excepto el primer valor)
inverse_diff = df_diff.cumsum() + serie.iloc[0]
plt.figure(figsize=(18, 5))
plt.plot(inverse_diff, color='darkgreen')
plt.title("Serie de tiempo: serie original")
plt.xlabel("Fecha")
plt.ylabel("$")
plt.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
inverse_log = np.exp(df_log)
plt.figure(figsize=(18, 5))
plt.plot(inverse_log, color='darkgreen')
plt.title("Serie de tiempo: serie original")
plt.xlabel("Fecha")
plt.ylabel("$")
plt.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
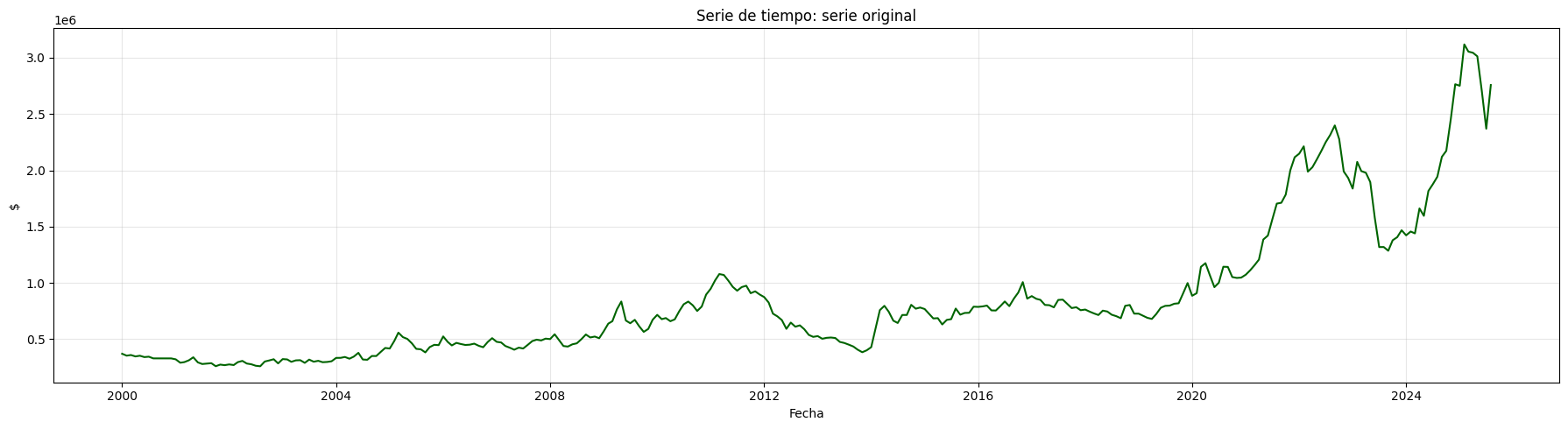
# Recuperar la serie logarítmica original
inverse_log = df_log_diff.cumsum() + df_log.iloc[0]
# Recuperar la serie original (deshacer el log)
inverse_log_diff = np.exp(inverse_log)
plt.figure(figsize=(18, 5))
plt.plot(inverse_log_diff, color='darkgreen')
plt.title("Serie de tiempo: serie original")
plt.xlabel("Fecha")
plt.ylabel("$")
plt.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()