Ajuste SARIMA Irradiancia#
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib.dates as mdates
from statsmodels.tsa.stattools import adfuller
from statsmodels.graphics.tsaplots import plot_acf, plot_pacf
from scipy.stats import boxcox
from statsmodels.tsa.statespace.sarimax import SARIMAX
import statsmodels.api as sm
from scipy.stats import norm
Funciones#
def plot_serie_tiempo(
serie: pd.DataFrame,
nombre: str,
unidades: str = None,
columna: str = None,
fecha_inicio: str = None,
fecha_fin: str = None,
color: str = 'navy',
linewidth: float = 2,
num_xticks: int = 12,
estacionalidad: str = None, # 'diciembre', 'enero', 'semana', 'semestre', 'custom_month'
custom_month: int = None, # Si quieres marcar otro mes (ejemplo: 3 para marzo)
vline_label: str = None, # Etiqueta para la(s) línea(s) vertical(es)
hlines: list = None, # lista de valores horizontales a marcar
hlines_labels: list = None, # lista de etiquetas para líneas horizontales
color_estacion: str = 'darkgray', # color de las líneas estacionales
alpha_estacion: float = 0.3, # transparencia de líneas estacionales
color_hline: str = 'gray', # color de las líneas horizontales
alpha_hline: float = 0.7 # transparencia de líneas horizontales
):
"""
Gráfico elegante de serie de tiempo.
- Eje X alineado con la primera fecha real de la serie.
- Opcional: marcar estacionalidades (diciembres, semanas, semestres, mes personalizado) con etiqueta.
- Líneas horizontales con etiqueta opcional (legend).
"""
df = serie.copy()
if columna is None:
columna = df.columns[0]
if fecha_inicio:
df = df[df.index >= fecha_inicio]
if fecha_fin:
df = df[df.index <= fecha_fin]
# Asegura que el índice sea datetime y esté ordenado
df = df.sort_index()
df.index = pd.to_datetime(df.index)
plt.style.use('ggplot')
fig, ax = plt.subplots(figsize=(14, 6))
# Gráfica principal
ax.plot(df.index, df[columna], color=color, linewidth=linewidth, label=nombre)
ax.set_title(f"Serie de tiempo: {nombre}", fontsize=20, weight='bold',
color='black')
ax.set_xlabel("Fecha", fontsize=15, color='black')
ax.set_ylabel(unidades, fontsize=15, color='black')
ax.tick_params(axis='both', colors='black', labelsize=13)
for label in ax.get_xticklabels() + ax.get_yticklabels():
label.set_color('black')
# Limita el rango del eje X exactamente al rango de fechas de la serie (no corrido)
ax.set_xlim(df.index.min(), df.index.max())
# Ticks equidistantes en eje X, asegurando que empieza en la primera fecha
idx = df.index
if len(idx) > num_xticks:
ticks = np.linspace(0, len(idx)-1, num_xticks, dtype=int)
ticks[0] = 0 # asegúrate que arranque en la primera fecha
ticklabels = [idx[i] for i in ticks]
ax.set_xticks(ticklabels)
ax.set_xticklabels([pd.to_datetime(t).strftime('%b %Y') for t in ticklabels], rotation=0, color='black')
else:
ax.xaxis.set_major_formatter(mdates.DateFormatter('%b %Y'))
fig.autofmt_xdate(rotation=0)
# ==============================
# LÍNEAS VERTICALES: Estacionalidad (con etiqueta en leyenda si se desea)
# ==============================
vlines_plotted = False
if estacionalidad is not None:
if estacionalidad == 'diciembre':
fechas_mark = df[df.index.month == 12].index
elif estacionalidad == 'enero':
fechas_mark = df[df.index.month == 1].index
elif estacionalidad == 'semana':
fechas_mark = df[df.index.weekday == 0].index
elif estacionalidad == 'semestre':
fechas_mark = df[df.index.month.isin([6, 12])].index
elif estacionalidad == 'custom_month' and custom_month is not None:
fechas_mark = df[df.index.month == custom_month].index
else:
fechas_mark = []
for i, f in enumerate(fechas_mark):
# Solo pone la etiqueta una vez (la primera línea)
if not vlines_plotted and vline_label is not None:
ax.axvline(f, color=color_estacion, alpha=alpha_estacion, linewidth=2, linestyle='--', zorder=0, label=vline_label)
vlines_plotted = True
else:
ax.axvline(f, color=color_estacion, alpha=alpha_estacion, linewidth=2, linestyle='--', zorder=0)
# ==============================
# LÍNEAS HORIZONTALES OPCIONALES, con leyenda
# ==============================
if hlines is not None:
if hlines_labels is None:
hlines_labels = [None] * len(hlines)
for i, h in enumerate(hlines):
if hlines_labels[i] is not None:
ax.axhline(h, color=color_hline, alpha=alpha_hline, linewidth=1.5, linestyle='--', zorder=0, label=hlines_labels[i])
else:
ax.axhline(h, color=color_hline, alpha=alpha_hline, linewidth=1.5, linestyle='--', zorder=0)
# Coloca la leyenda solo si hay etiquetas
handles, labels = ax.get_legend_handles_labels()
if any(labels):
ax.legend(loc='best', fontsize=13, frameon=True)
ax.grid(True, alpha=0.4)
plt.tight_layout()
plt.show()
##################################################################################
def analisis_estacionariedad_full(
serie: pd.Series,
nombre: str = None,
lags: int = 24,
xtick_interval: int = 3
):
"""
Gráfica y análisis de estacionariedad para una serie de tiempo con múltiples transformaciones:
- Serie original
- Diferenciación
- Logaritmo
- Diferenciación del Logaritmo
- Raíz cuadrada
- Diferenciación de la raíz cuadrada
- Box-Cox (con corrimiento si hay valores <= 0)
- Diferenciación del Box-Cox
Para cada transformación se grafica:
- Serie transformada en el tiempo
- ACF
- PACF
- Resultado de la prueba ADF con interpretación
Args:
serie: Serie de tiempo (índice datetime, pandas.Series)
nombre: Nombre de la serie (para títulos)
lags: Número de rezagos para ACF/PACF
xtick_interval: Mostrar ticks en X cada este número de lags, incluyendo siempre el lag 1
Return:
dict con los resultados de la ADF para cada transformación
"""
if nombre is None:
nombre = serie.name if serie.name is not None else "Serie"
serie = serie.astype(float).copy()
serie_orig = serie.copy()
serie_diff = serie_orig.diff().dropna()
# Logaritmo
if (serie_orig <= 0).any():
log_ok = False
serie_log = pd.Series([np.nan]*len(serie_orig), index=serie_orig.index)
serie_log_diff = pd.Series([np.nan]*len(serie_orig), index=serie_orig.index)
else:
log_ok = True
serie_log = np.log(serie_orig)
serie_log_diff = serie_log.diff().dropna()
# Raíz cuadrada
if (serie_orig < 0).any():
sqrt_ok = False
serie_sqrt = pd.Series([np.nan]*len(serie_orig), index=serie_orig.index)
serie_sqrt_diff = pd.Series([np.nan]*len(serie_orig), index=serie_orig.index)
else:
sqrt_ok = True
serie_sqrt = np.sqrt(serie_orig)
serie_sqrt_diff = serie_sqrt.diff().dropna()
# Box–Cox
if (serie_orig <= 0).any():
shift_bc = 1 - serie_orig.min()
else:
shift_bc = 0.0
serie_bc_input = serie_orig + shift_bc
if (serie_bc_input <= 0).any():
bc_ok = False
serie_boxcox = pd.Series([np.nan]*len(serie_orig), index=serie_orig.index)
serie_boxcox_diff = pd.Series([np.nan]*len(serie_orig), index=serie_orig.index)
lambda_bc = np.nan
else:
bc_ok = True
bc_vals, lambda_bc = boxcox(serie_bc_input.values)
serie_boxcox = pd.Series(bc_vals, index=serie_orig.index)
serie_boxcox_diff = serie_boxcox.diff().dropna()
# --- Títulos actualizados ---
titulos = [
f"Serie original: {nombre}",
"Diferenciación",
"Logaritmo" + ("" if log_ok else " (no aplicable)"),
"Diferenciación del Logaritmo" + ("" if log_ok else " (no aplicable)"),
"Raíz cuadrada" + ("" if sqrt_ok else " (no aplicable)"),
"Diferenciación de la raíz cuadrada" + ("" if sqrt_ok else " (no aplicable)"),
"Box-Cox" + (f" (λ = {lambda_bc:.4f})" if bc_ok else " (no aplicable)"),
"Diferenciación del Box-Cox" + ("" if bc_ok else " (no aplicable)")
]
series = [
serie_orig,
serie_diff,
serie_log,
serie_log_diff,
serie_sqrt,
serie_sqrt_diff,
serie_boxcox,
serie_boxcox_diff
]
# --- ADF ---
resultados_adf = []
interpretaciones = []
for i, s in enumerate(series):
s_ = s.dropna()
if len(s_) < 5:
resultados_adf.append((np.nan, np.nan))
interpretaciones.append("No evaluable")
continue
regression_type = 'ct' if i in [0, 2, 4, 6] else 'c'
try:
adf_res = adfuller(s_, regression=regression_type, autolag='AIC')
estadistico = adf_res[0]
pvalue = adf_res[1]
except Exception:
estadistico = np.nan
pvalue = np.nan
resultados_adf.append((estadistico, pvalue))
interpretaciones.append("Estacionaria" if (pvalue is not None and pvalue < 0.05) else "No estacionaria")
# --- Gráficos ---
filas = len(series)
fig, axes = plt.subplots(filas, 3, figsize=(18, 4*filas), squeeze=False)
colores = ['black'] * filas
for fila in range(filas):
serie_fila = series[fila]
# Serie temporal
axes[fila, 0].plot(serie_fila, color=colores[fila], lw=1)
axes[fila, 0].set_title(titulos[fila], color='black')
axes[fila, 0].set_xlabel("Fecha", color='black')
if fila == 0:
ylabel = "Valor"
elif fila == 1:
ylabel = "Δ Valor"
elif fila == 2:
ylabel = "Log(Valor)"
elif fila == 3:
ylabel = "Δ Log(Valor)"
elif fila == 4:
ylabel = "√Valor"
elif fila == 5:
ylabel = "Δ √Valor"
elif fila == 6:
ylabel = "Box-Cox"
else:
ylabel = "Δ Box-Cox"
axes[fila, 0].set_ylabel(ylabel, color='black')
axes[fila, 0].grid(True, alpha=0.3)
axes[fila, 0].tick_params(axis='both', labelsize=11, colors='black')
adf_est, adf_p = resultados_adf[fila]
axes[fila, 0].text(
0.02, 0.85,
f"ADF: {adf_est:.2f}\np-valor: {adf_p:.4f}\n{interpretaciones[fila]}",
transform=axes[fila, 0].transAxes,
fontsize=11,
bbox=dict(facecolor='white', alpha=0.85),
color='black'
)
# ACF
try:
plot_acf(serie_fila.dropna(), lags=lags, ax=axes[fila, 1], zero=False, color=colores[fila])
except Exception:
axes[fila, 1].text(0.5, 0.5, "ACF no disponible", ha='center', va='center')
axes[fila, 1].set_title("ACF", color='black')
xticks = [1] + list(range(xtick_interval, lags + 1, xtick_interval))
axes[fila, 1].set_xticks(sorted(set(xticks)))
axes[fila, 1].tick_params(axis='both', labelsize=11, colors='black')
axes[fila, 1].set_xlabel("Lag", color='black')
# PACF
try:
plot_pacf(serie_fila.dropna(), lags=lags, ax=axes[fila, 2], zero=False, color=colores[fila])
except Exception:
axes[fila, 2].text(0.5, 0.5, "PACF no disponible", ha='center', va='center')
axes[fila, 2].set_title("PACF", color='black')
axes[fila, 2].set_xticks(sorted(set(xticks)))
axes[fila, 2].tick_params(axis='both', labelsize=11, colors='black')
axes[fila, 2].set_xlabel("Lag", color='black')
plt.tight_layout()
plt.show()
# --- Resumen ADF ---
adf_dict = {
titulos[i]: {
"estadístico ADF": resultados_adf[i][0],
"p-valor": resultados_adf[i][1],
"interpretación": interpretaciones[i],
"nota_boxcox": (
f"lambda Box-Cox = {lambda_bc:.4f}, shift aplicado = {shift_bc:.4f}"
if ("Box-Cox" in titulos[i] and bc_ok)
else ("Box-Cox no aplicable" if "Box-Cox" in titulos[i] and not bc_ok else None)
)
}
for i in range(filas)
}
return adf_dict
##################################################################################
def analisis_residuales(
residuals,
nombre: str = "Serie de tiempo",
lags: int = 24,
color_resid: str = "navy",
color_qq: str = "navy",
color_acf_pacf: str = "navy"
):
"""
Análisis gráfico de residuales:
- Residuales en el tiempo (toda la fila superior)
- Histograma + curva normal (izq), QQ-plot (der)
- ACF (izq), PACF (der) con bandas y barras color navy
"""
residuals = residuals[1:].dropna()
mu = residuals.mean()
sigma = residuals.std(ddof=1)
x = np.linspace(residuals.min(), residuals.max(), 400)
pdf = norm.pdf(x, loc=mu, scale=sigma)
fig = plt.figure(constrained_layout=True, figsize=(14, 11))
gs = fig.add_gridspec(3, 2, height_ratios=[1, 1, 1])
# 1. Residuales en el tiempo
ax_time = fig.add_subplot(gs[0, :])
ax_time.scatter(residuals.index, residuals, color=color_resid, alpha=0.7, s=20)
ax_time.axhline(0, ls="--", color="black")
ax_time.set_title(f"Residuales en el tiempo: {nombre}", color='black')
ax_time.set_xlabel("Tiempo", color='black')
ax_time.set_ylabel("Residual", color='black')
ax_time.tick_params(axis='both', labelsize=11, colors='black')
# 2. Histograma + curva Normal
ax_hist = fig.add_subplot(gs[1, 0])
ax_hist.hist(residuals, bins="auto", density=True, alpha=0.6, edgecolor="k", color="royalblue")
ax_hist.plot(x, pdf, lw=2, label=f"N({mu:.3f}, {sigma:.3f}²)", color="darkred")
ax_hist.set_title("Histograma residuaes y ajuste Normal", color='black')
ax_hist.set_xlabel("Residual", color='black')
ax_hist.set_ylabel("Densidad", color='black')
ax_hist.legend(fontsize=9)
ax_hist.grid(alpha=0.18)
ax_hist.tick_params(axis='both', labelsize=10, colors='black')
# 3. QQ-plot
ax_qq = fig.add_subplot(gs[1, 1])
qq = sm.qqplot(residuals, line='45', fit=True, ax=ax_qq, markerfacecolor=color_qq, markeredgecolor=color_qq, marker='o')
lines = ax_qq.get_lines()
if len(lines) >= 1:
lines[0].set_color(color_qq)
lines[0].set_marker('o')
lines[0].set_linestyle('None')
if len(lines) >= 2:
lines[1].set_color("black")
lines[1].set_linestyle("--")
ax_qq.set_title("Q-Q Plot de los residuales", color='black')
ax_qq.set_xlabel("Cuantiles teóricos (Normal)", color='black')
ax_qq.set_ylabel("Cuantiles de los residuales", color='black')
ax_qq.tick_params(axis='both', labelsize=10, colors='black')
for l in ax_qq.get_xticklabels() + ax_qq.get_yticklabels():
l.set_color('black')
# 4. ACF (usando color navy en barras y bandas)
ax_acf = fig.add_subplot(gs[2, 0])
sm.graphics.tsa.plot_acf(residuals, lags=lags, ax=ax_acf, zero=False, color=color_acf_pacf)
ax_acf.set_title("ACF de los residuales", color='black')
ax_acf.set_xlabel("Rezagos", color='black')
ax_acf.set_ylabel("Autocorrelación", color='black')
ax_acf.tick_params(axis='both', labelsize=10, colors='black')
# 5. PACF (usando color navy en barras y bandas)
ax_pacf = fig.add_subplot(gs[2, 1])
sm.graphics.tsa.plot_pacf(residuals, lags=lags, ax=ax_pacf, zero=False, color=color_acf_pacf)
ax_pacf.set_title("PACF de los residuales", color='black')
ax_pacf.set_xlabel("Rezagos", color='black')
ax_pacf.set_ylabel("Autocorrelación parcial", color='black')
ax_pacf.tick_params(axis='both', labelsize=10, colors='black')
plt.show()
return
##################################################################################
def analizar_ajuste_serie(
serie_original,
fitted_values,
results,
test,
n_forecast,
transformacion=None, # 'log', 'boxcox', 'sqrt', o None
lambda_bc=None, # solo si boxcox
nombre="Serie"
):
"""
Analiza el ajuste de un modelo y grafica ajuste+pronóstico sobre la serie original,
devolviendo predicciones revertidas a la escala original.
Args:
serie_original: Serie original (sin transformar, index datetime)
fitted_values: Serie de fittedvalues (en escala transformada)
results: Modelo ajustado de statsmodels (debe soportar .append, .get_forecast)
test: Serie de test (index datetime)
n_forecast: Períodos a pronosticar por fuera de la muestra
transformacion: 'log', 'boxcox', 'sqrt' o None
lambda_bc: Valor de lambda para boxcox (si aplica)
nombre: Nombre para los ejes y leyenda
Returns:
Diccionario con:
- y_pred_train, y_pred_test, forecasting_orig, lower_bt, upper_bt
- Fechas de pronóstico futuro: future_dates
"""
# Alinear índices por seguridad
fitted_values = fitted_values.reindex(serie_original.index.intersection(fitted_values.index))
test = test.copy()
# ----------- PRONÓSTICO EN TEST (fuera de muestra, recursivo) -----------
current_results = results
forecasted_test = []
lower_ci_test = []
upper_ci_test = []
for i in range(len(test)):
forecaster = current_results.get_forecast(steps=1)
forecast_mean_test = forecaster.predicted_mean.iloc[0]
ci_i_test = forecaster.conf_int(alpha=0.05).iloc[0]
forecasted_test.append(forecast_mean_test)
lower_ci_test.append(ci_i_test.iloc[0])
upper_ci_test.append(ci_i_test.iloc[1])
# Recursivo: alimentar el modelo con el valor real observado
current_results = current_results.append(endog=[test.iloc[i]], refit=False)
forecasted_test = pd.Series(forecasted_test, index=test.index, name='forecast_test')
lower_ci_test = pd.Series(lower_ci_test, index=test.index, name='lower_test')
upper_ci_test = pd.Series(upper_ci_test, index=test.index, name='upper_test')
# ----------- PRONÓSTICO FUTURO (n_forecast meses) -----------
current_results = results.append(endog=test, refit=False)
forecasting = []
lower_ci = []
upper_ci = []
for i in range(n_forecast):
forecaster = current_results.get_forecast(steps=1)
forecast_mean = forecaster.predicted_mean.iloc[0]
ci_i = forecaster.conf_int(alpha=0.05).iloc[0]
forecasting.append(forecast_mean)
lower_ci.append(ci_i.iloc[0])
upper_ci.append(ci_i.iloc[1])
current_results = current_results.append(endog=[forecast_mean], refit=False)
# Fechas futuras mensuales (puedes personalizar)
last_date = test.index[-1]
future_dates = pd.date_range(start=last_date + pd.offsets.MonthBegin(1),
periods=n_forecast, freq='MS')
forecasting = pd.Series(forecasting, index=future_dates, name='forecast')
lower_ci = pd.Series(lower_ci, index=future_dates, name='lower')
upper_ci = pd.Series(upper_ci, index=future_dates, name='upper')
# ----------- REVERSIÓN DE TRANSFORMACIÓN -----------
if transformacion == "log":
y_pred_train = np.exp(fitted_values)
y_pred_test = np.exp(forecasted_test)
forecasting_orig = np.exp(forecasting)
lower_bt = np.exp(lower_ci)
upper_bt = np.exp(upper_ci)
elif transformacion == "boxcox":
if lambda_bc is None:
raise ValueError("Debes indicar lambda_bc para la transformación Box-Cox")
y_pred_train = np.power((lambda_bc * fitted_values + 1), 1 / lambda_bc)
y_pred_test = np.power((lambda_bc * forecasted_test + 1), 1 / lambda_bc)
forecasting_orig = np.power((lambda_bc * forecasting + 1), 1 / lambda_bc)
lower_bt = np.power((lambda_bc * lower_ci + 1), 1 / lambda_bc)
upper_bt = np.power((lambda_bc * upper_ci + 1), 1 / lambda_bc)
elif transformacion == "sqrt":
y_pred_train = fitted_values ** 2
y_pred_test = forecasted_test ** 2
forecasting_orig = forecasting ** 2
lower_bt = lower_ci ** 2
upper_bt = upper_ci ** 2
elif transformacion is None or transformacion == "none":
y_pred_train = fitted_values
y_pred_test = forecasted_test
forecasting_orig = forecasting
lower_bt = lower_ci
upper_bt = upper_ci
else:
raise ValueError("Transformación no soportada. Usa 'log', 'boxcox', 'sqrt' o None.")
# ----------- GRÁFICO -----------
plt.figure(figsize=(12,6))
# Serie original
plt.plot(serie_original[1:], label=nombre, color='black')
# Ajuste en train
plt.plot(y_pred_train[1:], label='Ajuste en train', color='tab:blue')
# Ajuste en test
plt.plot(y_pred_test, label='Pronóstico en test', color='tab:green')
# Pronóstico futuro + IC
plt.plot(forecasting_orig, label='Pronóstico futuro', color='tab:red', linestyle='--')
plt.fill_between(future_dates, lower_bt.values, upper_bt.values, color='tab:red', alpha=0.2, label='IC 95%')
plt.title(f'Ajuste y pronóstico - {nombre}')
plt.xlabel('Tiempo')
plt.ylabel('Valor')
plt.legend()
plt.tight_layout()
plt.show()
# ----------- Devuelve resultados clave -----------
return {
'y_pred_train': y_pred_train,
'y_pred_test': y_pred_test,
'forecasting_orig': forecasting_orig,
'lower_bt': lower_bt,
'upper_bt': upper_bt,
'future_dates': future_dates
}
##################################################################################
def _inverse_transform(y, transformacion=None, lambda_bc=None):
"""Revierte la transformación aplicada a una Serie o arreglo."""
if y is None:
return None
y_vals = y.values if isinstance(y, (pd.Series, pd.Index)) else np.asarray(y)
if transformacion is None or str(transformacion).lower() in ("none", ""):
inv = y_vals
elif str(transformacion).lower() == "log":
inv = np.exp(y_vals)
elif str(transformacion).lower() == "sqrt":
inv = np.power(y_vals, 2)
elif str(transformacion).lower() == "boxcox":
if lambda_bc is None:
raise ValueError("Para 'boxcox' debes proporcionar lambda_bc.")
inv = np.power((lambda_bc * y_vals + 1.0), 1.0 / lambda_bc)
else:
raise ValueError("Transformación no soportada. Usa 'log', 'boxcox', 'sqrt' o None.")
if isinstance(y, pd.Series):
return pd.Series(inv, index=y.index, name=y.name)
else:
return inv
def _recursive_forecast_over_test(results, test):
"""Pronóstico recursivo 1-paso-ahead sobre TEST."""
current_results = results
preds, lowers, uppers = [], [], []
for i in range(len(test)):
forecaster = current_results.get_forecast(steps=1)
mean_i = forecaster.predicted_mean.iloc[0]
ci_i = forecaster.conf_int(alpha=0.05).iloc[0]
preds.append(mean_i)
lowers.append(ci_i.iloc[0])
uppers.append(ci_i.iloc[1])
# Se alimenta el valor real observado
current_results = current_results.append(endog=[test.iloc[i]], refit=False)
y_pred_test = pd.Series(preds, index=test.index, name="forecast_test")
lower_ci = pd.Series(lowers, index=test.index, name="lower_test")
upper_ci = pd.Series(uppers, index=test.index, name="upper_test")
return y_pred_test, lower_ci, upper_ci
def _ajustado(r2, n, p):
"""Calcula el R² ajustado."""
if n - p - 1 <= 0:
return np.nan
return 1 - (1 - r2) * (n - 1) / (n - p - 1)
def evaluar_metricas_desempeno(
train,
test,
results,
transformacion=None, # 'log', 'boxcox', 'sqrt' o None
lambda_bc=None, # solo si boxcox
nombre="Precio de electricidad",
imprimir=True
):
"""
Calcula las métricas (R², R² ajustado, RMSE, MAPE, Max Error)
para TRAIN y TEST en la escala original, usando sklearn.
"""
# 1) Fitted values en escala transformada
fitted_transf = results.fittedvalues
fitted_transf = fitted_transf.reindex(train.index)
# 2) Pronóstico recursivo en TEST
y_pred_test_transf, lower_ci_transf, upper_ci_transf = _recursive_forecast_over_test(results, test)
# 3) Revertir transformaciones
y_train_orig = _inverse_transform(train, transformacion, lambda_bc)
y_test_orig = _inverse_transform(test, transformacion, lambda_bc)
y_pred_train_orig = _inverse_transform(fitted_transf, transformacion, lambda_bc)
y_pred_test_orig = _inverse_transform(y_pred_test_transf, transformacion, lambda_bc)
lower_test_orig = _inverse_transform(lower_ci_transf, transformacion, lambda_bc)
upper_test_orig = _inverse_transform(upper_ci_transf, transformacion, lambda_bc)
# 4) Extraer cantidad de parámetros (para R² ajustado)
try:
p_eff = int(getattr(results, "k_params", 1))
except Exception:
p_eff = 1
# 5) Cálculo de métricas con sklearn
n_train = len(y_train_orig)
n_test = len(y_test_orig)
r2_train = r2_score(y_train_orig, y_pred_train_orig)
rmse_train = np.sqrt(mean_squared_error(y_train_orig, y_pred_train_orig))
mape_train = mean_absolute_percentage_error(y_train_orig, y_pred_train_orig) * 100
maxerr_train = max_error(y_train_orig, y_pred_train_orig)
r2adj_train = _ajustado(r2_train, n_train, p_eff)
r2_test = r2_score(y_test_orig, y_pred_test_orig)
rmse_test = np.sqrt(mean_squared_error(y_test_orig, y_pred_test_orig))
mape_test = mean_absolute_percentage_error(y_test_orig, y_pred_test_orig) * 100
maxerr_test = max_error(y_test_orig, y_pred_test_orig)
r2adj_test = _ajustado(r2_test, n_test, p_eff)
# 6) Tabla resumen
tabla = pd.DataFrame({
"Train": [rmse_train, mape_train, maxerr_train, r2_train, r2adj_train],
"Test": [rmse_test, mape_test, maxerr_test, r2_test, r2adj_test]
}, index=["RMSE", "MAPE (%)", "Max Error", "R2", "R2 Ajustado"])
if imprimir:
titulo = f"Métricas de desempeño - {nombre}"
print("\n" + titulo)
print("-" * len(titulo))
display(tabla.style.format({
"Train": "{:,.4f}",
"Test": "{:,.4f}"
}))
return {
"tabla_metricas": tabla,
"y_train_orig": y_train_orig,
"y_test_orig": y_test_orig,
"y_pred_train_orig": y_pred_train_orig,
"y_pred_test_orig": y_pred_test_orig,
"lower_test_orig": lower_test_orig,
"upper_test_orig": upper_test_orig
}
Precio interno del Café#
# Cargar el archivo
serie = pd.read_excel('Irradiancia Medellín.xlsx')
# Corregir nombres de columnas si tienen espacios
serie.columns = serie.columns.str.strip()
# Convertir 'Fecha' a datetime y usar como índice
serie['Fecha'] = pd.to_datetime(serie['Fecha'])
serie.set_index('Fecha', inplace=True)
# Ordenar por fecha por si acaso
serie = serie.sort_index()
# Establecer frecuencia explícita para evitar el warning de statsmodels
serie.index.freq = serie.index.inferred_freq
serie.head()
| Irradiancia | |
|---|---|
| Fecha | |
| 1984-01-01 | 4.5926 |
| 1984-02-01 | 4.3133 |
| 1984-03-01 | 4.9030 |
| 1984-04-01 | 4.8943 |
| 1984-05-01 | 4.7242 |
plot_serie_tiempo(
serie,
nombre="Irradiancia de Medellín",
columna='Irradiancia',
unidades='$\\mathrm{kWh\\,m^{-2}\\,día^{-1}}$',
estacionalidad='diciembre',
vline_label="Diciembre",
num_xticks = 14
)
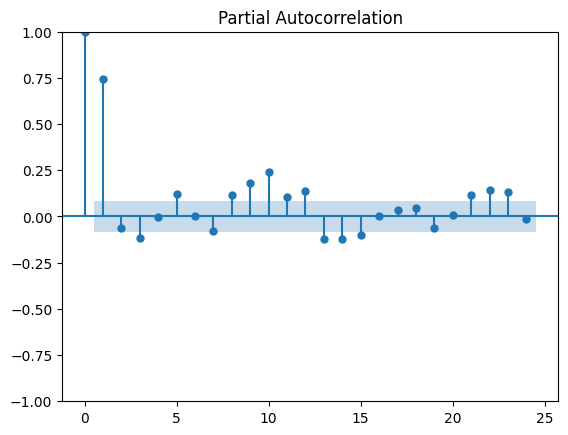
adf_resultados = analisis_estacionariedad_full(
serie['Irradiancia'],
nombre="Irradiancia de Medellín",
lags=48,
xtick_interval=3
)
La mejor transformación es la primera diferenciación
Conjunto de train y test:#
# Dividir en train y test (por ejemplo, 80% train, 20% test)
split = int(len(serie) * 0.8)
train, test = serie[:split], serie[split:]
# Graficar train y test:
plt.figure(figsize=(12, 5))
plt.plot(train, label='Train', color='navy')
plt.plot(test, label='Test', color='orange')
plt.title("Conjunto de train y test")
plt.xlabel("Fecha")
plt.ylabel("Valor")
plt.legend()
plt.grid(True, alpha=0.3)
plt.tight_layout()
import itertools
from statsmodels.tsa.statespace.sarimax import SARIMAX
Silenciar solo los warning:
import warnings
from statsmodels.tools.sm_exceptions import ConvergenceWarning
warnings.filterwarnings("ignore",
message="Non-invertible starting MA parameters",
category=UserWarning)
warnings.filterwarnings("ignore",
message="Non-stationary starting autoregressive parameters",
category=UserWarning)
warnings.filterwarnings("ignore", category=ConvergenceWarning)
warnings.filterwarnings("ignore",
message="Non-stationary starting seasonal autoregressive")
Auto-ARIMA#
La serie de irradiancia mensual presenta una estacionalidad anual evidente, observable en la ACF con picos repetidos cada 12 meses. Sin embargo, esta estacionalidad no implica que los parámetros no estacionales del ARIMA (p y q) deban evaluarse hasta 12.
En un modelo SARIMA, la estacionalidad se captura exclusivamente mediante los parámetros estacionales (P, D, Q) y el periodo m = 12, no con p y q altos.
Elegir p = q = 12 generaría modelos innecesariamente grandes, con riesgo de sobreajuste, inestabilidad numérica, no estacionariedad, no invertibilidad y AIC elevado.
Por ello, la práctica recomendada es permitir que auto-ARIMA explore rangos pequeños para p y q (0–3) y rangos moderados para P y Q (0–2), con periodo estacional 12, lo cual es suficiente para capturar la ciclicidad anual propia de la irradiancia.
Dado que la serie presenta una estacionalidad anual marcada, si no se realiza la diferenciación estacional (D = 0), la componente estacional permanece no estacionaria. En estas condiciones, el modelo SARIMA intenta ajustar términos AR/MA estacionales sobre una serie que aún conserva una raíz unitaria estacional, lo cual genera inestabilidad y problemas de identificación. Por esta razón, es necesario considerar modelos con diferenciación estacional con D = 1.
p = range(0, 4) # range no toma el último, por tanto se debe indicar un valor adicional.
q = range(0, 4)
d = [1] # para evaluar d = 0 poner d = [0, 1]
pdq = list(itertools.product(p, d, q)) # Todas las combinaciones posibles
# Componente estacional:
P = range(0, 3) # range no toma el último, por tanto se debe indicar un valor adicional.
Q = range(0, 3)
D = [1] # para evaluar d = 0 poner d = [0, 1]
s = 12
PDQ = list(itertools.product(P, D, Q, [s])) # Todas las combinaciones posibles siempre con s = 12
trend = 'n' # 'c' = constante, 't' = tendencia, 'ct' = constante + tendencia, 'n' = sin tendencia
best_aic = float("inf")
best_order = None
best_seasonal_order = None
for seasonal_order in PDQ:
for order in pdq:
try:
model = SARIMAX(train, order=order,
seasonal_order=seasonal_order,
trend=trend)
results = model.fit(disp=False)
if results.aic < best_aic:
best_aic = results.aic
best_order = order
best_seasonal_order = seasonal_order
except:
continue
print(f"Mejor modelo SARIMA{best_order}{best_seasonal_order} con AIC={best_aic}")
Mejor modelo SARIMA(2, 1, 1)(0, 1, 1, 12) con AIC=177.3481614195116
Modelo seleccionado#
SARIMA(2,1,1)(0,1,1,12)
# Definir los parámetros del modelo ARIMA (p, d, q)
order = (2, 1, 1) # Puedes ajustar según el análisis de ACF y PACF
trend = 'n' # 'c' = constante, 't' = tendencia, 'ct' = constante + tendencia, 'n' = sin tendencia
seasonal_order = (0, 1, 1, 12) # Parámetros de la estacionalidad (P, D, Q, s)
# Ajustar el modelo con los datos de entrenamiento
model = SARIMAX(train, order=order, seasonal_order=seasonal_order, trend=trend)
results = model.fit()
# Mostrar resumen del modelo
print(results.summary())
SARIMAX Results
==========================================================================================
Dep. Variable: Irradiancia No. Observations: 396
Model: SARIMAX(2, 1, 1)x(0, 1, 1, 12) Log Likelihood -83.674
Date: Mon, 17 Nov 2025 AIC 177.348
Time: 22:17:59 BIC 197.088
Sample: 01-01-1984 HQIC 185.179
- 12-01-2016
Covariance Type: opg
==============================================================================
coef std err z P>|z| [0.025 0.975]
------------------------------------------------------------------------------
ar.L1 0.1363 0.054 2.520 0.012 0.030 0.242
ar.L2 0.1581 0.052 3.048 0.002 0.056 0.260
ma.L1 -0.9739 0.018 -54.025 0.000 -1.009 -0.939
ma.S.L12 -0.9250 0.039 -23.744 0.000 -1.001 -0.849
sigma2 0.0843 0.006 13.155 0.000 0.072 0.097
===================================================================================
Ljung-Box (L1) (Q): 0.06 Jarque-Bera (JB): 0.17
Prob(Q): 0.81 Prob(JB): 0.92
Heteroskedasticity (H): 1.02 Skew: 0.01
Prob(H) (two-sided): 0.91 Kurtosis: 2.90
===================================================================================
Warnings:
[1] Covariance matrix calculated using the outer product of gradients (complex-step).
Ajuste y pronóstico en la serie original#
Recordar que solo se ajustó a la transformación de primera diferencia \(d=1\)
fitted_values = results.fittedvalues
y_pred_train = fitted_values # Sin transformación
y_pred = y_pred_train[1:]
y_real = serie["Irradiancia"][1:split]
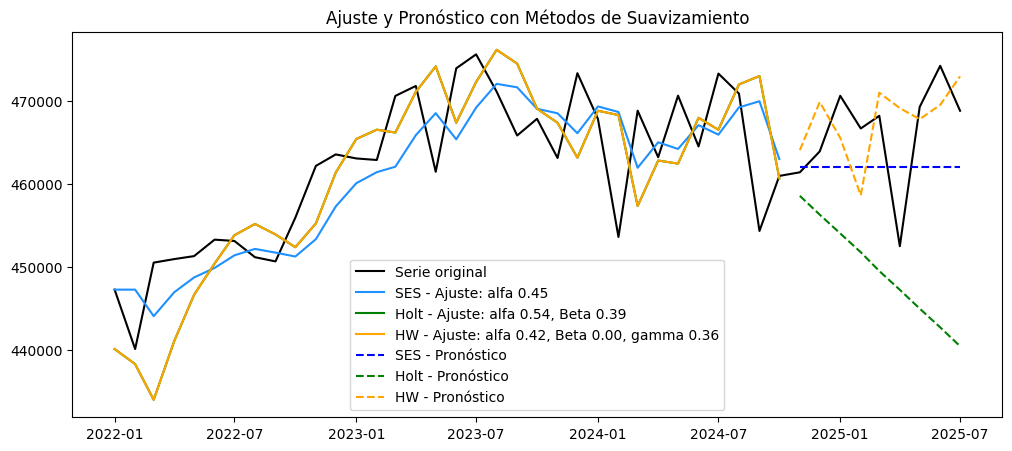
resultados = analizar_ajuste_serie(
serie, # Serie original (sin transformar)
fitted_values, # Ajuste en train
results, # Modelo ajustado
test, # Datos test
n_forecast=12, # Periodos futuros
transformacion=None, # 'log', 'boxcox', 'sqrt' o None SIN TRANSFORMACIÓN
nombre="Irradiancia de Medellín"
)
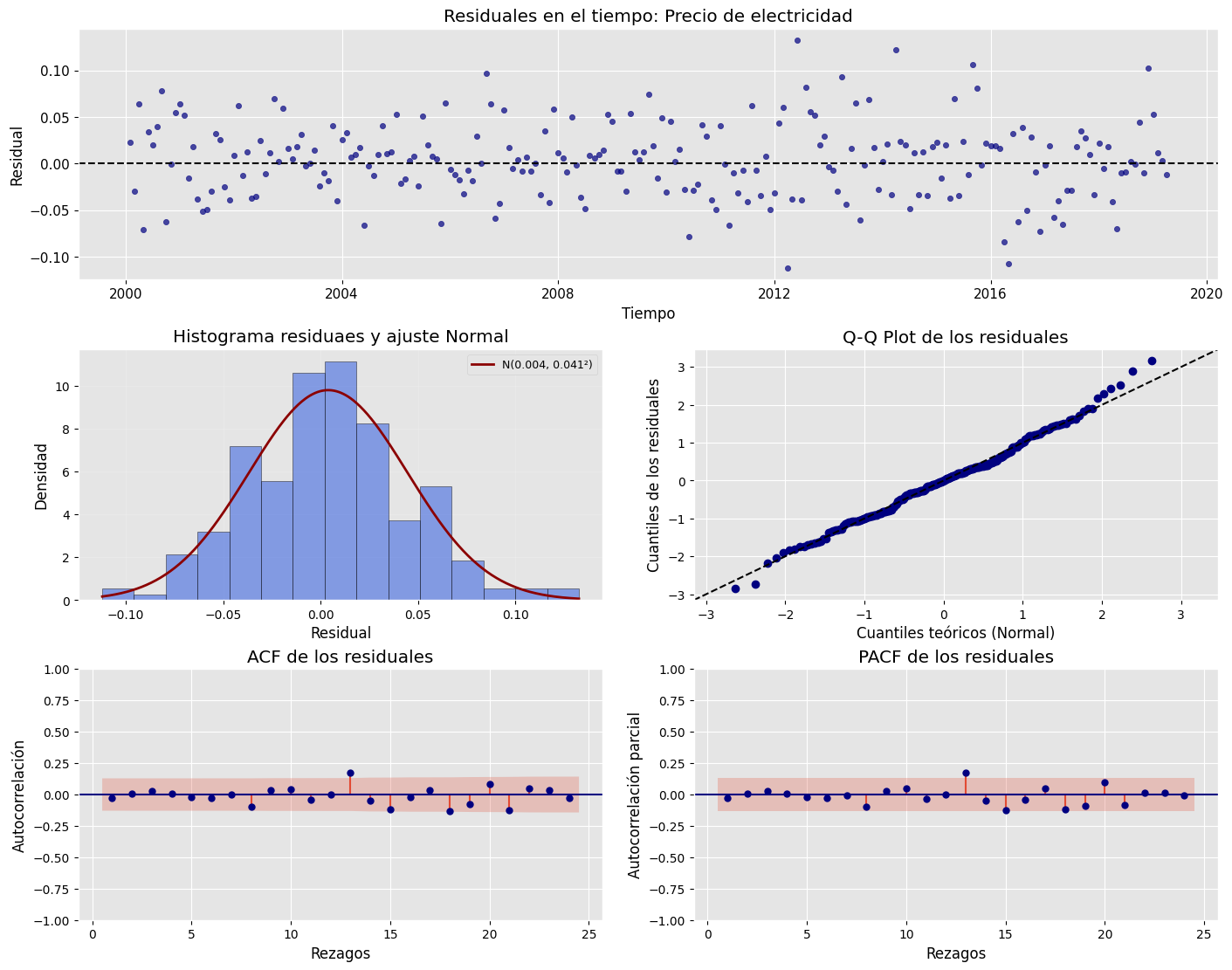
### Gráfico de valores predichos vs. valores reales
plt.figure(figsize=(6,6))
plt.scatter(y_real, y_pred, color='blue', alpha=0.6, edgecolor='k')
# Línea de identidad (y = x)
min_val = min(y_real.min(), y_pred.min())
max_val = max(y_real.max(), y_pred.max())
plt.plot([min_val, max_val], [min_val, max_val], color='black', lw=2)
plt.title("Valores predichos vs. valores reales", fontsize=12)
plt.xlabel("Valores reales")
plt.ylabel("Valores predichos")
plt.axis("equal") # asegura proporciones iguales para la diagonal
plt.grid(alpha=0.3)
plt.tight_layout()
plt.show()
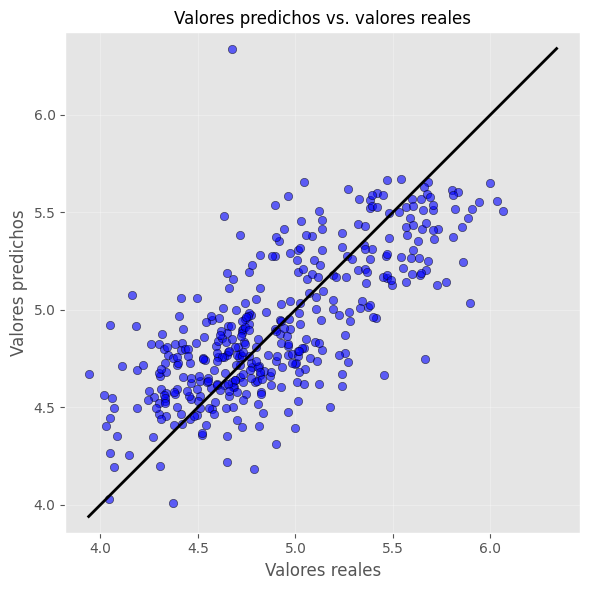
Análisis de los residuales#
analisis_residuales(
results.resid, # Agregar los residuales
nombre="Irradiancia de Medellín",
)