Random Forest#
Random Forest es un poderoso algoritmo de aprendizaje automático utilizado para tareas de clasificación y regresión. Se basa en la idea de combinar múltiples modelos, específicamente árboles de decisión, para crear un modelo más robusto y preciso. Este enfoque se denomina método de conjunto y es muy efectivo para reducir el riesgo de sobreajuste y mejorar la capacidad de generalización del modelo.
Conceptos clave:#
1. Árboles de Decisión:
Los árboles de decisión son modelos simples y fáciles de interpretar que dividen los datos en subconjuntos más pequeños basados en preguntas binarias sobre las características de los datos.
Cada nodo del árbol representa una pregunta sobre una característica, y cada hoja del árbol representa una predicción final.
2. Bagging (Bootstrap Aggregating):
Bagging es una técnica que mejora la precisión del modelo al entrenar múltiples instancias del mismo modelo con diferentes subconjuntos de datos.
Cada modelo se entrena con una muestra aleatoria con reemplazo del conjunto de datos original, lo que introduce diversidad en los modelos individuales.
3. Random Forest:
Un Random Forest es un conjunto de árboles de decisión, generalmente entrenados mediante el método de bagging.
En lugar de usar todo el conjunto de características para dividir en cada nodo, Random Forest selecciona aleatoriamente un subconjunto de características para considerar, aumentando así la diversidad entre los árboles y mejorando la robustez del modelo.
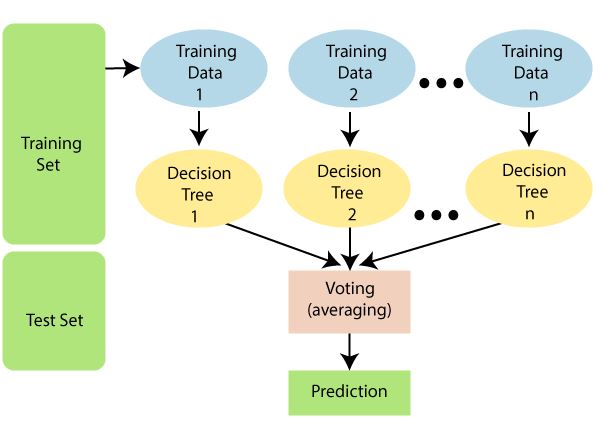
RF#
Ventajas de Random Forest:
1. Precisión mejorada: Al combinar los resultados de múltiples árboles, Random Forest generalmente ofrece una precisión superior en comparación con un solo árbol de decisión.
2. Reducción del sobreajuste: La combinación de múltiples árboles reduce la varianza del modelo, disminuyendo el riesgo de sobreajuste a los datos de entrenamiento.
3. Robustez: Random Forest maneja bien los datos faltantes y es robusto frente a los outliers y ruido en los datos.
4. Importancia de las características: Random Forest proporciona una medida clara de la importancia relativa de cada característica en la predicción, lo cual es muy útil para la interpretación del modelo.
Desventajas de Random Forest:
1. Mayor complejidad computacional: Entrenar múltiples árboles es computacionalmente más costoso que entrenar un único árbol de decisión.
2. Menor interpretabilidad: Aunque cada árbol individual es interpretable, el conjunto de árboles es menos intuitivo de interpretar.
Extra-Trees: una variante de Random Forest:#
Extra-Trees (Árboles Extremadamente Aleatorizados) es una variante de Random Forest que introduce aún más aleatoriedad al proceso de crecimiento de los árboles. En lugar de buscar el mejor umbral para dividir cada nodo, Extra-Trees selecciona un umbral aleatorio para cada característica. Esto puede hacer que los árboles sean más diversos y el modelo más rápido de entrenar.
Comparación entre Random Forest y Extra-Trees:
Es difícil predecir cuál de los dos algoritmos funcionará mejor para un problema específico. La mejor práctica es probar ambos y comparar su rendimiento utilizando validación cruzada. Ajustar los hiperparámetros de ambos modelos a través de una búsqueda en cuadrícula (grid search) puede proporcionar resultados aún mejores.
Importancia de las características:
Una de las ventajas notables de Random Forest es su capacidad para medir la importancia de cada característica en el conjunto de datos. Scikit-Learn calcula automáticamente la importancia de las características después del entrenamiento del modelo, basada en la reducción de impureza que cada característica contribuye a lo largo de todos los árboles.