Regresión Logística#
Un método de clasificación binaria:
La regresión logística, también conocida como Logit, es un clasificador binario utilizado para modelar variables categóricas, particularmente variables binarias o dicotómicas. La variable dependiente puede tener solo dos valores: 0 o 1, representando “sí” y “no”, “éxito” y “fracaso”, o “verdadero” y “falso”. Estas asignaciones son arbitrarias y se aplican a características cualitativas. La regresión logística clasifica las observaciones en estas dos categorías según la probabilidad estimada en el modelo. Por tanto, no se predice directamente si una observación es 1 o 0, sino la probabilidad de que pertenezca a la categoría 1.
La variable respuesta \(𝑦\) una variable aleatoria Bernoulli con la siguiente distribución de probabilidad:
\(y=1\) con una probabilidad \(p\).
\(y=0\) con una probabilidad \(p-1\)
El valor esperado de \(y\) es \(p\), es decir, el valor esperado es la probabilidad de que la variable \(y\) tenga el valor de 1.
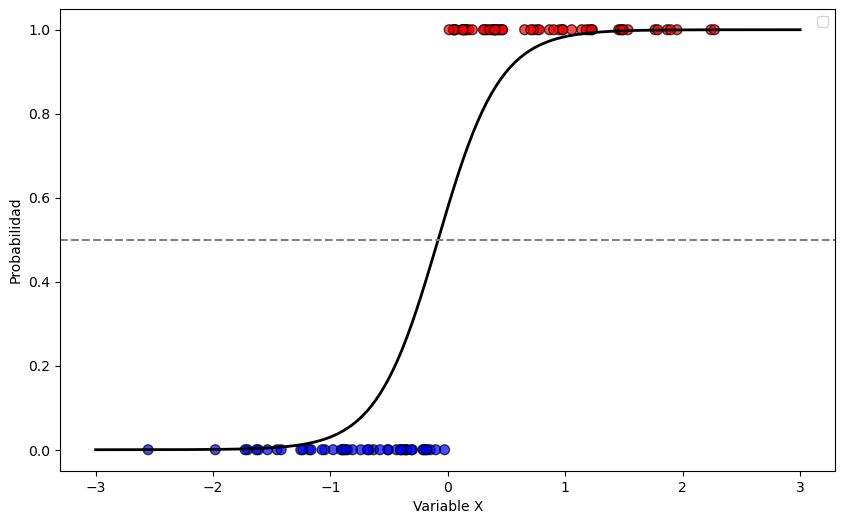
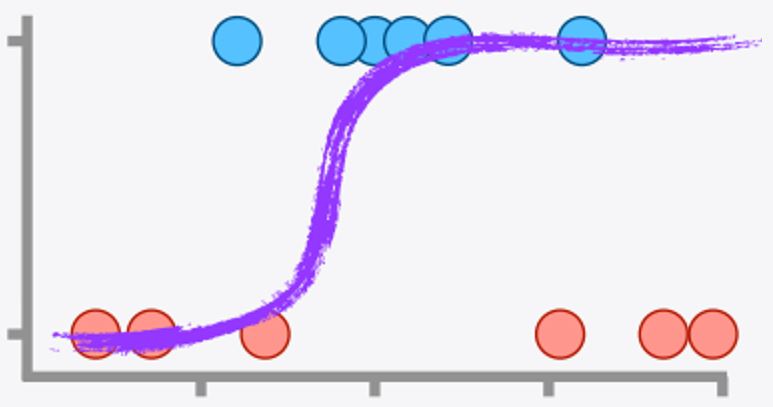
Dado que la variable respuesta \(y\) es binaria, se utiliza una función no lineal que puede ser creciente o decreciente en forma de “S” o “S” invertida. La función más utilizada es la función logística:
donde \(z\) es una combinación lineal de las características de entrada.
La función sigmoide transforma cualquier valor real en un valor entre 0 y 1, lo que puede interpretarse como una probabilidad.
En el denominador de esta ecuación aparece la ecuación de regresión lineal, pero tiene una transformación. Con esta función se garantiza que los valores predichos ven entre cero y uno, tal como se supone que lo hacen las probabilidades.
S#
En la regresión logística, el umbral (threshold) es el valor que se utiliza para decidir a qué clase se asigna una observación basada en la probabilidad predicha. La regresión logística calcula la probabilidad de que una observación pertenezca a la clase positiva (por ejemplo, clase 1). Por defecto, este umbral se establece en 0.5, lo que significa que:
Si la probabilidad predicha es mayor o igual a 0,5, la observación se clasifica como clase 1.
Si la probabilidad predicha es menor a 0,5, la observación se clasifica como clase 0.
El valor predeterminado de 0,5 puede no ser óptimo para todos los problemas. Dependiendo del contexto, puede ser necesario ajustar el umbral para equilibrar mejor las tasas de falsos positivos y falsos negativos, especialmente si las clases están desbalanceadas o si las consecuencias de errores de clasificación son diferentes.
Regression#
Interpretación en los coeficientes:#
La interpretación de los coeficientes \(\beta\) en la regresión logística es diferente a la de los modelos de regresión lineal.
Dado que:
Exponencial a ambos lados para obtener:
Se deduca que, para el modelo de regresión:
La interpretación de los coeficientes se hace a través de los odds ratio, aplicando la exponencial a los resultados estimados. Para una variable regresora \(𝑋_𝑗\), el odds ratio es igual a \(e^{\beta_j}\). Este valor representa el aumento estimado de la probabilidad de “éxito” (\(p\)), asociado a un cambio unitario en el valor de la variable predictora \(𝑋_𝑗\), suponiendo que las demás variables permanecen constantes.
Ejemplo de interpretación:
Supongamos que el coeficiente estimado \(\beta_1=0,1\). Esto implica que un aumento unitario en la variable \(𝑋_1\) incrementa en un 10% la probabilidad de obtener “éxito”. Si \(𝑋_1\) aumenta en 20 unidades, entonces \(e^{0,1\times20}= 7,39\), lo que indica que las probabilidades aumentan aproximadamente 7,39 veces.
Si en este ejemplo el coeficiente \(\beta_1\) fuera negativo, por ejemplo \(\beta_1=−0,1\), entonces el odds ratio sería menor que 1, específicamente \(e^{-0,1}= 0,91\). Esto se interpreta como que un aumento unitario en la variable \(𝑋_1\) reduce la probabilidad de éxito en aproximadamente un 9%.
Diferencia porcentual:
Otra forma de interpretar los coeficientes es a través de la diferencia porcentual. Con la ecuación anterior, podemos determinar el efecto que tienen los coeficientes \(\beta\) negativos sobre la variable resultado. Recuerde que a los coeficientes \(\beta\) se les aplica la función exponencial, que siempre toma valores positivos. Sin embargo, con valores negativos, el resultado de la exponencial es menor que la unidad.
Si \(\beta\) es negativo, entonces \(e^{\beta}\) es menor que 1. El resultado es el porcentaje en el que disminuye la variable resultado \(𝑝\) para un aumento unitario en la variable \(𝑋_𝑗\).
Si \(\beta\) es positivo, entonces \(e^{\beta}\) es mayor que 1. El resultado es el porcentaje en el que aumenta la variable resultado \(𝑝\) para un aumento unitario en la variable \(𝑋_𝑗\).
Por ejemplo, si \(\beta_1=0,1\), entonces \(e^{0,10}=1,105\). Esto indica que un aumento unitario en \(𝑋_1\) incrementa la probabilidad de éxito en aproximadamente un 10,5%. Si \(\beta_1=-0,1\), entonces \(e^{-0,10}=0,905\), lo que significa que un aumento unitario en \(𝑋_1\) reduce la probabilidad de éxito en aproximadamente un 9,5%.
Ajuste en scikit-learn:#
Durante el ajuste de un modelo de regresión logística, se utiliza un
algoritmo de optimización (como el método de máxima verosimilitud) para
encontrar los coeficientes del modelo que minimicen la función de
pérdida. Este proceso es iterativo y se repite hasta que se alcanza la
convergencia (es decir, hasta que los cambios en los coeficientes sean
muy pequeños entre una iteración y la siguiente) o hasta que se alcanza
el número máximo de iteraciones especificado por max_iter.
El valor predeterminado de max_iter es 100, lo que significa que el
algoritmo de optimización realizará como máximo 100 iteraciones para
intentar encontrar la solución óptima. Si el algoritmo no ha convergido
después de 100 iteraciones, puede ser necesario aumentar este valor.
El objetivo es encontrar la curva que maximice la verosimilitud. En la práctica, usualmente encontramos la curva óptima utilizando Gradiente descendente.
Desventajas de la regresión logística:#
La regresión logística es una técnica popular y efectiva para problemas de clasificación binaria. Sin embargo, presenta varias desventajas y limitaciones que deben tenerse en cuenta:
1. Relación lineal entre las variables independientes y el Logit:
La regresión logística asume una relación lineal entre las variables independientes y el logit de la variable dependiente. Si la relación real entre las variables no es lineal, el modelo puede no ajustarse bien a los datos.
2. Limitada a problemas binarios:
La regresión logística básica se utiliza para problemas de clasificación binaria. Aunque existen extensiones como la regresión logística multinomial para más de dos clases, estas pueden ser más complejas y no siempre proporcionan los mejores resultados en comparación con otros métodos.
3. Sensibilidad a outliers:
La regresión logística puede ser sensible a los valores atípicos (outliers). Estos valores extremos pueden afectar significativamente la estimación de los coeficientes y, en consecuencia, el rendimiento del modelo.
4. Suposiciones sobre las variables independientes:
La regresión logística asume que las variables independientes no están fuertemente correlacionadas entre sí (no hay multicolinealidad). La presencia de multicolinealidad puede inflar las varianzas de los coeficientes estimados y hacer que el modelo sea inestable.
5. No captura relaciones complejas:
La regresión logística no es adecuada para capturar relaciones no lineales o interacciones complejas entre las variables. Métodos como los Árboles de Decisión, las Máquinas de Vectores de Soporte o las redes neuronales pueden manejar mejor estas relaciones.
6. Rendimiento en conjuntos de datos desbalanceados:
La regresión logística puede tener problemas al manejar conjuntos de datos desbalanceados, donde una clase es mucho más frecuente que la otra. En estos casos, el modelo puede sesgarse hacia la clase mayoritaria, ignorando la clase minoritaria.
7. Escalabilidad:
En conjuntos de datos muy grandes, la regresión logística puede volverse computacionalmente costosa y lenta, especialmente si se requiere un ajuste fino de hiperparámetros.
8. Interpretación de coeficientes en modelos complejos:
Aunque los coeficientes de la regresión logística son interpretables, en modelos con muchas variables independientes, la interpretación puede volverse complicada y menos intuitiva.
No_S#