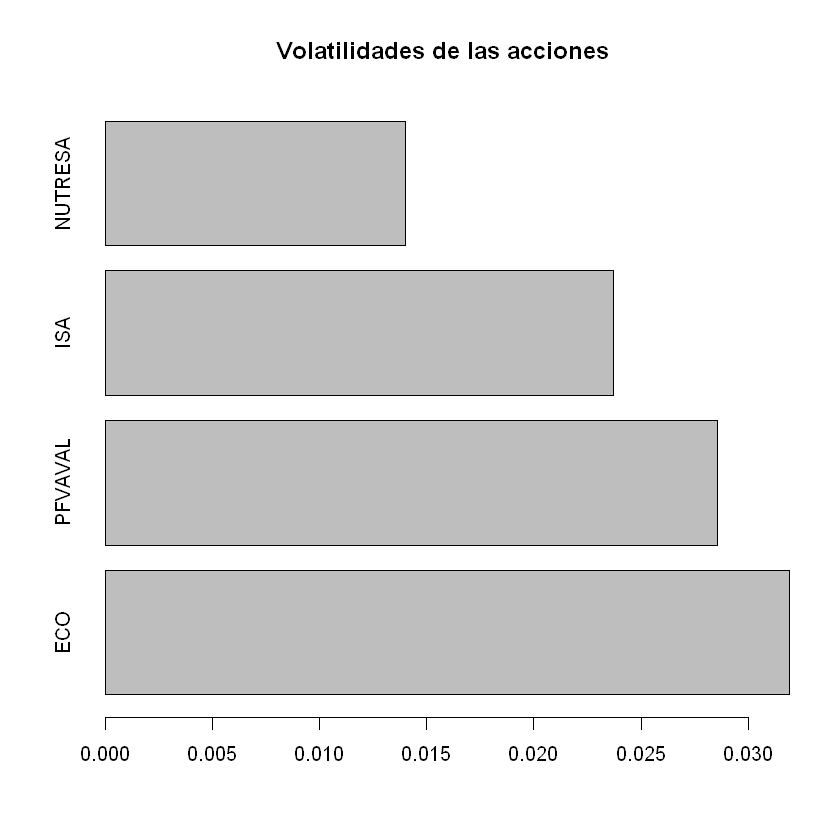
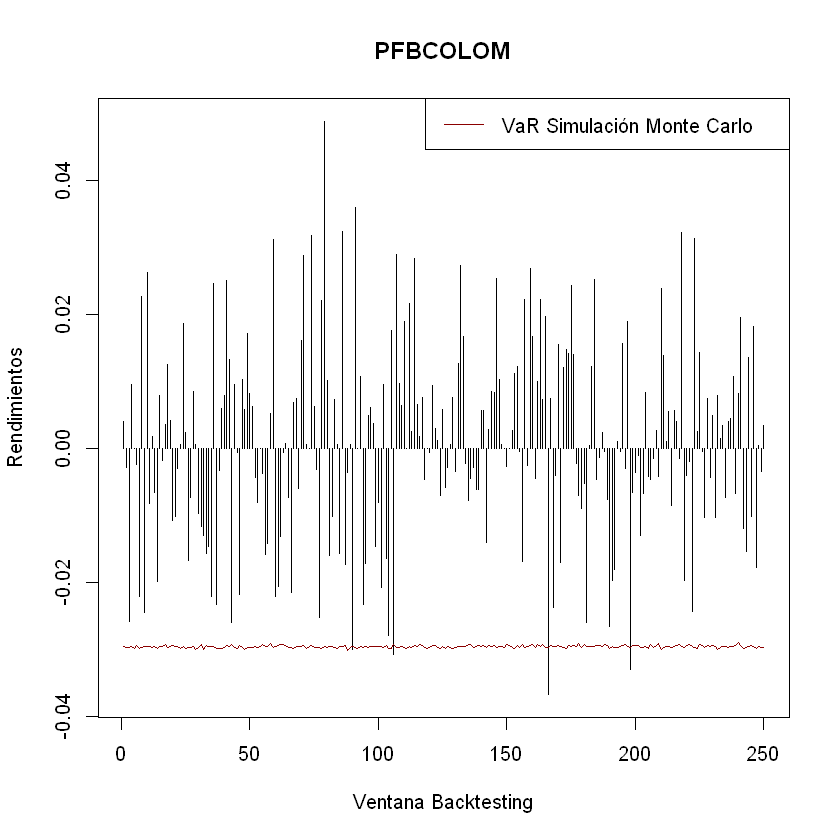
Ejercicio Clustering Estados Financieros#
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from scipy.cluster.hierarchy import dendrogram, linkage, fcluster, cophenet
from sklearn.cluster import AgglomerativeClustering
from scipy.spatial.distance import pdist
import seaborn as sns
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import silhouette_score
from sklearn.cluster import KMeans
from sklearn.cluster import DBSCAN
# Cargar los datos
data_pymes = pd.read_excel("../210030_Estado de situación financiera, corriente_no corriente_PYMES.xlsx")
data_grandes = pd.read_excel("../210030_Estado de situación financiera, corriente_no corriente.xlsx")
data_UN_grandes = pd.read_excel("../310030_Estado de resultado integral, resultado del periodo, por funcion de gasto.xlsx")
data_UN_pymes = pd.read_excel("../310030_Estado de resultado integral, resultado del periodo, por funcion de gasto_PYMES.xlsx")
data_UN_pymes.columns
Index(['Punto de Entrada', 'Nombre Formulario', 'NIT', 'Fecha de Corte',
'Razón social de la sociedad',
'Clasificación Industrial Internacional Uniforme Versión 4 A.C (CIIU)',
'Tipo societario',
'Dirección de notificación judicial registrada en Cámara de Comercio',
'Departamento de la dirección del domicilio',
'Ciudad de la dirección del domicilio', 'Periodo',
'Ingresos de actividades ordinarias (Revenue)',
'Costo de ventas (CostOfSales)', 'Ganancia bruta (GrossProfit)',
'Otros ingresos (OtherIncome)', 'Gastos de ventas (DistributionCosts)',
'Gastos de administración (AdministrativeExpense)',
'Otros gastos (OtherExpenseByFunction)',
'Otras ganancias (pérdidas) (OtherGainsLosses)',
'Ganancia (pérdida) por actividades de operación (GananciaPerdidaPorActividadesDeOperacion)',
'Ingresos financieros (FinanceIncome)',
'Costos financieros (FinanceCosts)',
'Ganancia (pérdida), antes de impuestos (ProfitLossBeforeTax)',
'Ingreso (gasto) por impuestos (IncomeTaxExpenseContinuingOperations)',
'Ganancia (pérdida) procedente de operaciones continuadas (ProfitLossFromContinuingOperations)',
'Ganancia (pérdida) procedente de operaciones discontinuadas (ProfitLossFromDiscontinuedOperations)',
'Ganancia (pérdida) (ProfitLoss)'],
dtype='object')
data_UN_grandes.columns
Index(['Punto de Entrada', 'Nombre Formulario', 'NIT', 'Fecha de Corte',
'Razón social de la sociedad',
'Clasificación Industrial Internacional Uniforme Versión 4 A.C (CIIU)',
'Tipo societario',
'Dirección de notificación judicial registrada en Cámara de Comercio',
'Departamento de la dirección del domicilio',
'Ciudad de la dirección del domicilio', 'Periodo',
'Ingresos de actividades ordinarias (Revenue)',
'Costo de ventas (CostOfSales)', 'Ganancia bruta (GrossProfit)',
'Otros ingresos (OtherIncome)', 'Gastos de ventas (DistributionCosts)',
'Gastos de administración (AdministrativeExpense)',
'Otros gastos (OtherExpenseByFunction)',
'Otras ganancias (pérdidas) (OtherGainsLosses)',
'Ganancia (pérdida) por actividades de operación (ProfitLossFromOperatingActivities)',
'Diferencia entre el importe en libros de dividendos pagaderos e importe en libros de activos distribuidos distintos al efectivo (DifferenceBetweenCarryingAmountOfDividendsPayableAndCarryingAmountOfNoncashAssetsDistributed)',
'Ganancias (pérdidas) que surgen de la baja en cuentas de activos financieros medidos al costo amortizado (GainLossArisingFromDerecognitionOfFinancialAssetsMeasuredAtAmortisedCost)',
'Ingresos financieros (FinanceIncome)',
'Costos financieros (FinanceCosts)',
'Deterioro de valor de ganancias y reversión de pérdidas por deterioro de valor (pérdidas por deterioro de valor) determinado de acuerdo con la NIIF 9 (ImpairmentLossImpairmentGainAndReversalOfImpairmentLossDeterminedInAccordanceWithIFRS9)',
'Ganancias (pérdidas) que surgen de diferencias entre el costo amortizado anterior y el valor razonable de activos financieros reclasificados de la categoría de medición costo amortizado a la categoría de medición de valor razonable con cambios en resultados (GainsLossesArisingFromDifferenceBetweenPreviousCarryingAmountAndFairValueOfFinancialAssetsReclassifiedAsMeasuredAtFairValue)',
'Ganancia (pérdida) acumulada anteriormente reconocida en otro resultado integral que surge de la reclasificación de activos financieros de la categoría de medición de valor razonable con cambios en otro resultado integral a la de valor razonable con cambios en resultados (CumulativeGainLossPreviouslyRecognisedInOtherComprehensiveIncomeArisingFromReclassificationOfFinancialAssetsOutOfFairValueThroughOtherComprehensiveIncomeIntoFairValueThroughProfitOrLossMeasurementCategory)',
'Ganancias (pérdidas) de cobertura por cobertura de un grupo de partidas con posiciones de riesgo compensadoras (HedgingGainsLossesForHedgeOfGroupOfItemsWithOffsettingRiskPositions)',
'Ganancia (pérdida), antes de impuestos (ProfitLossBeforeTax)',
'Ingreso (gasto) por impuestos (IncomeTaxExpenseContinuingOperations)',
'Ganancia (pérdida) procedente de operaciones continuadas (ProfitLossFromContinuingOperations)',
'Ganancia (pérdida) procedente de operaciones discontinuadas (ProfitLossFromDiscontinuedOperations)',
'Ganancia (pérdida) (ProfitLoss)'],
dtype='object')
# Función para filtrar, calcular indicadores y eliminar outliers
def filtrar_y_calcular(data, CIIU_1, CIIU_2, EF):
if EF == "BG":
filtered_data = data[
((data['Clasificación Industrial Internacional Uniforme Versión 4 A.C (CIIU)'] == CIIU_1) |
(data['Clasificación Industrial Internacional Uniforme Versión 4 A.C (CIIU)'] == CIIU_2)) &
(data['Periodo'] == 'Periodo Actual')
].copy()
# Calcular los indicadores de liquidez y endeudamiento utilizando los nombres exactos de las columnas
filtered_data.loc[:, 'Liquidez'] = filtered_data['Activos corrientes totales (CurrentAssets)'] / filtered_data['Pasivos corrientes totales (CurrentLiabilities)']
filtered_data.loc[:, 'Endeudamiento'] = filtered_data['Total pasivos (Liabilities)'] / filtered_data['Total de activos (Assets)']
filtered_data.loc[:, 'UtilidadesAcumuladas'] = filtered_data['Ganancias acumuladas (RetainedEarnings)']
variables = ['Razón social de la sociedad', 'Liquidez', 'Endeudamiento', 'UtilidadesAcumuladas']
filtered_data = filtered_data[variables].replace([np.inf, -np.inf], np.nan, inplace=False).dropna().copy()
elif EF == "ER":
filtered_data = data[
((data['Clasificación Industrial Internacional Uniforme Versión 4 A.C (CIIU)'] == CIIU_1) |
(data['Clasificación Industrial Internacional Uniforme Versión 4 A.C (CIIU)'] == CIIU_2)) &
(data['Periodo'] == 'Periodo Actual')
].copy()
# Verificar cuál de las columnas de Ganancia está presente
if 'Ganancia (pérdida) por actividades de operación (GananciaPerdidaPorActividadesDeOperacion)' in filtered_data.columns:
ganancia_col = 'Ganancia (pérdida) por actividades de operación (GananciaPerdidaPorActividadesDeOperacion)'
elif 'Ganancia (pérdida) por actividades de operación (ProfitLossFromOperatingActivities)' in filtered_data.columns:
ganancia_col = 'Ganancia (pérdida) por actividades de operación (ProfitLossFromOperatingActivities)'
else:
raise KeyError("No se encontró ninguna de las columnas de ganancia esperadas en el DataFrame.")
# Calcular los indicadores de liquidez y endeudamiento utilizando los nombres exactos de las columnas
filtered_data.loc[:, 'Margen_EBIT'] = filtered_data[ganancia_col] / filtered_data['Ingresos de actividades ordinarias (Revenue)']
variables = ['Razón social de la sociedad', 'Margen_EBIT']
filtered_data = filtered_data[variables].replace([np.inf, -np.inf], np.nan, inplace=False).dropna().copy()
# Identificar y eliminar valores atípicos usando el IQR
numeric_cols = filtered_data.select_dtypes(include=[np.number]).columns
Q1 = filtered_data[numeric_cols].quantile(0.25)
Q3 = filtered_data[numeric_cols].quantile(0.75)
IQR = Q3 - Q1
lower_bound = Q1 - 1.5 * IQR
upper_bound = Q3 + 1.5 * IQR
filtered_data = filtered_data[~((filtered_data[numeric_cols] < lower_bound) | (filtered_data[numeric_cols] > upper_bound)).any(axis=1)]
return filtered_data
# Filtrar y calcular indicadores
CIIU_1 = "G4711 - Comercio al por menor en establecimientos no especializados con surtido compuesto principalmente por alimentos, bebidas (alcohólicas y no alcohólicas) o tabaco"
CIIU_2 = ""
data_pymes_filtered = filtrar_y_calcular(data_pymes, CIIU_1, CIIU_2, EF="BG")
data_grandes_filtered = filtrar_y_calcular(data_grandes, CIIU_1, CIIU_2, EF="BG")
data_UN_pymes_filtered = filtrar_y_calcular(data_UN_pymes, CIIU_1, CIIU_2, EF="ER")
data_UN_grandes_filtered = filtrar_y_calcular(data_UN_grandes, CIIU_1, CIIU_2, EF="ER")
merged_data_pymes = pd.merge(data_pymes_filtered, data_UN_pymes_filtered, on='Razón social de la sociedad', how='inner')
merged_data_grandes = pd.merge(data_grandes_filtered, data_UN_grandes_filtered, on='Razón social de la sociedad', how='inner')
# Agregar etiquetas
merged_data_pymes['Tipo'] = 'Pyme'
merged_data_grandes['Tipo'] = 'Grande'
# Unir los datos
combined_data = pd.concat([merged_data_pymes, merged_data_grandes], ignore_index=True)
print("Cantidad empresas grandes: ", data_grandes_filtered.shape[0]+data_UN_grandes_filtered.shape[0])
print("Cantidad empresas pymes: ", data_pymes_filtered.shape[0]+data_UN_pymes_filtered.shape[0])
print(combined_data.head())
Cantidad empresas grandes: 25
Cantidad empresas pymes: 370
Razón social de la sociedad Liquidez Endeudamiento 0 PROVEEDORA LA AVENIDA SAS 1.452161 0.718850
1 JULIO CESAR RESTREPO Y CIA SA 0.630112 0.762482
2 MERCADOS FAMILIARES LTDA. MERCAFAM LTDA 2.348812 0.154581
3 EL SURTIDOR CAVIRI Y CIA SAS 1.196472 0.703666
4 RUBIO COLLAZOS RUCO SAS 1.207799 0.866774
UtilidadesAcumuladas Margen_EBIT Tipo
0 890909.0 0.020328 Pyme
1 1803534.0 -0.005176 Pyme
2 1327480.0 0.020362 Pyme
3 1211767.0 0.010259 Pyme
4 -51975.0 -0.015125 Pyme
df = combined_data.loc[
:, ["Liquidez", "Endeudamiento", "UtilidadesAcumuladas", "Margen_EBIT"]
]
df.head()
| Liquidez | Endeudamiento | UtilidadesAcumuladas | Margen_EBIT | |
|---|---|---|---|---|
| 0 | 1.452161 | 0.718850 | 890909.0 | 0.020328 |
| 1 | 0.630112 | 0.762482 | 1803534.0 | -0.005176 |
| 2 | 2.348812 | 0.154581 | 1327480.0 | 0.020362 |
| 3 | 1.196472 | 0.703666 | 1211767.0 | 0.010259 |
| 4 | 1.207799 | 0.866774 | -51975.0 | -0.015125 |
scaler = StandardScaler()
df_scaled = scaler.fit_transform(df)
sns.pairplot(df, palette="tab10")
plt.show()
Ajuste Cluster K-Means:#
Optimizar el hiperparámetro de n_clusters
wcss = []
silhouette_scores = []
K = range(2, 11)
for k in K:
kmeans = KMeans(n_clusters=k, random_state=34)
kmeans.fit(df_scaled)
wcss.append(kmeans.inertia_)
labels = kmeans.labels_
score = silhouette_score(df_scaled, labels)
silhouette_scores.append(score)
# Visualizar los resultados del método del codo y de la silueta
plt.figure(figsize=(16, 6))
plt.subplot(1, 2, 1)
plt.plot(K, wcss, "bo-")
plt.xlabel("Número de clústeres (K)")
plt.ylabel("WCSS")
plt.title("Método del Codo para determinar el número óptimo de clústeres")
plt.subplot(1, 2, 2)
plt.plot(K, silhouette_scores, "bo-")
plt.xlabel("Número de clústeres (K)")
plt.ylabel("Puntuación de la Silueta")
plt.title("Método de la Silueta para determinar el número óptimo de clústeres")
plt.tight_layout()
plt.show()
La mejor cantidad de clusters es 3.
k = 3
# Ajustar K-Means con el número óptimo de clústeres
kmeans = KMeans(n_clusters=k, random_state=34)
kmeans.fit(df_scaled)
labels = kmeans.labels_
# Agregar los clusters al DataFrame
df["cluster"] = labels
print("Cantidad de empresas por cluster:\n", df["cluster"].value_counts().sort_index())
Cantidad de empresas por cluster:
0 3
1 61
2 110
Name: cluster, dtype: int64
# Lista de variables que deseas graficar
variables = ["Liquidez", "Endeudamiento", "UtilidadesAcumuladas", "Margen_EBIT"]
# Crear una figura con subplots
fig, axes = plt.subplots(nrows=2, ncols=2, figsize=(20, 12))
# Aplanar el array de ejes para un fácil acceso
axes = axes.flatten()
# Iterar sobre cada variable para graficar en su respectivo subplot
for i, var in enumerate(variables):
sns.boxplot(x="cluster", y=var, data=df, palette="tab10", ax=axes[i])
axes[i].set_title(f"Boxplot de {var} por Cluster")
# Ajustar el layout para evitar solapamientos
plt.tight_layout()
plt.show()
sns.pairplot(df, hue="cluster", palette="tab10")
plt.show()
Ajuste Cluster jerárquico:#
Optimizar los siguientes hiperparámetros:
n_clusterslinkage
# Métodos de vinculación a probar
linkage_methods = ["single", "complete", "average", "ward"]
for method in linkage_methods:
# Crear la matriz de enlaces
Z = linkage(df_scaled, method=method)
# Calcular la correlación coefénica
c, coph_dists = cophenet(Z, pdist(df_scaled))
print(f"Método de vinculación: {method}, Correlación cofenética: {c:.4f}")
# Plot del dendrograma
plt.figure(figsize=(10, 7))
plt.title(f"Dendrograma ({method})")
dendrogram(Z)
plt.show()
Método de vinculación: single, Correlación cofenética: 0.7556
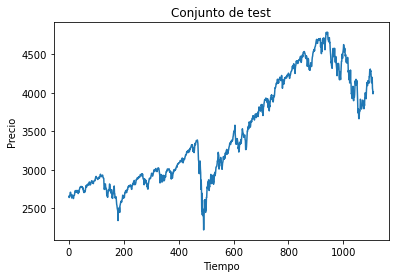
Método de vinculación: complete, Correlación cofenética: 0.7227
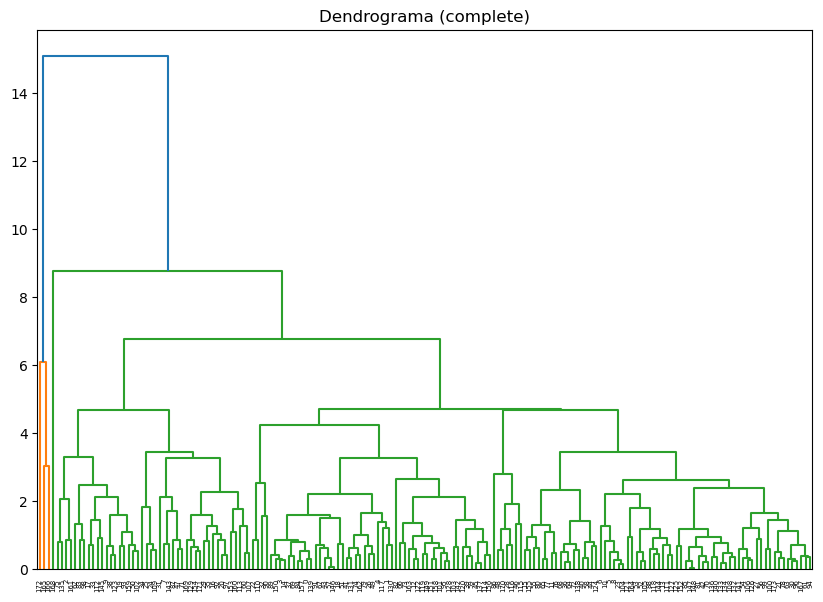
Método de vinculación: average, Correlación cofenética: 0.8431
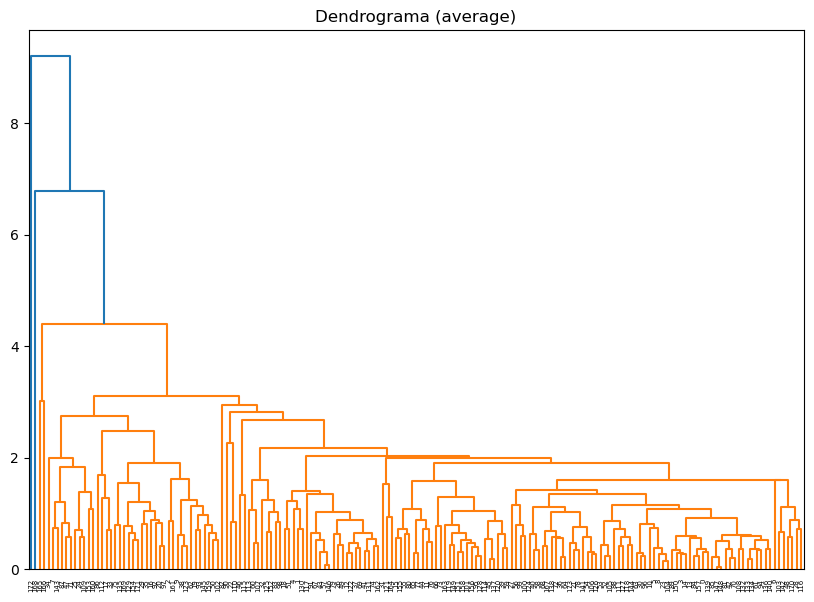
Método de vinculación: ward, Correlación cofenética: 0.5148
El mejor método es "average"
range_n_clusters = range(2, 11)
silhouette_avg_values = []
for n_clusters in range_n_clusters:
# Agrupar los datos con AgglomerativeClustering
clusterer = AgglomerativeClustering(n_clusters=n_clusters, linkage="average")
cluster_labels = clusterer.fit_predict(df_scaled)
# Calcular el silhouette score medio
silhouette_avg = silhouette_score(df_scaled, cluster_labels)
silhouette_avg_values.append(silhouette_avg)
# Graficar el silhouette score para cada número de clusters
plt.figure(figsize=(10, 6))
plt.plot(range_n_clusters, silhouette_avg_values, "bo-")
plt.xlabel("Número de clusters")
plt.ylabel("Silhouette Score promedio")
plt.title("Silhouette Score para diferentes números de clusters")
plt.show()
La mejor cantidad de cluster son 2 y 3.
# Asignar clusters
k = 3 # Definir el número de clusters
metodo = "average"
model = AgglomerativeClustering(n_clusters=k, linkage=metodo)
labels = model.fit_predict(df_scaled)
# Agregar los clusters al DataFrame
df["cluster"] = labels
print("Cantidad de empresas por cluster:\n", df["cluster"].value_counts().sort_index())
Cantidad de empresas por cluster:
0 172
1 1
2 1
Name: cluster, dtype: int64
# Lista de variables que deseas graficar
variables = ["Liquidez", "Endeudamiento", "UtilidadesAcumuladas", "Margen_EBIT"]
# Crear una figura con subplots
fig, axes = plt.subplots(nrows=2, ncols=2, figsize=(20, 12))
# Aplanar el array de ejes para un fácil acceso
axes = axes.flatten()
# Iterar sobre cada variable para graficar en su respectivo subplot
for i, var in enumerate(variables):
sns.boxplot(x="cluster", y=var, data=df, palette="tab10", ax=axes[i])
axes[i].set_title(f"Boxplot de {var} por Cluster")
# Ajustar el layout para evitar solapamientos
plt.tight_layout()
plt.show()

sns.pairplot(df, hue="cluster", palette="tab10")
plt.show()
Ajuste Cluster DBSCAN:#
Optimizar los siguientes hiperparámetros:
epsmin_samples
# Definir los valores de eps y min_samples para evaluar
eps_values = np.arange(0.1, 2, 0.1)
min_samples_values = range(1, 20, 2)
# Almacenar las puntuaciones de silueta
results = []
for eps in eps_values:
for min_samples in min_samples_values:
db = DBSCAN(eps=eps, min_samples=min_samples)
dbscan_labels = db.fit_predict(df_scaled)
if len(set(dbscan_labels)) > 1: # Asegurarse de que hay más de un cluster
silhouette_avg = silhouette_score(df_scaled, dbscan_labels)
results.append((eps, min_samples, silhouette_avg))
else:
results.append((eps, min_samples, -1))
# Convertir los resultados a un DataFrame
import pandas as pd
results_df = pd.DataFrame(results, columns=["eps", "min_samples", "silhouette_score"])
# Visualizar los resultados en un heatmap
pivot_table = results_df.pivot(index='eps', columns='min_samples', values='silhouette_score')
plt.figure(figsize=(10, 7))
sns.heatmap(pivot_table, annot=True, fmt=".4f", cmap="viridis")
plt.title("Puntuación de Silueta para diferentes combinaciones de eps y min_samples")
plt.show()
Los mejores valores son:
eps=1.6
min_samples=3:
eps = 1.6
min_samples = 3
# Aplicar DBSCAN
db = DBSCAN(eps=eps, min_samples=min_samples).fit(df_scaled)
labels = db.labels_
print(set(labels))
# Número de clusters en las etiquetas, ignorando el ruido si está presente.
n_clusters_ = len(set(labels)) - (1 if -1 in labels else 0) # Tener en cuenta que el cluster -1 es el ruido.
n_noise_ = list(labels).count(-1)
print(f"Número de clusters: {n_clusters_}")
print(f"Número de puntos de ruido: {n_noise_}")
labels = db.fit_predict(df_scaled)
# Agregar los clusters al DataFrame
df["cluster"] = labels
# Calcular el índice de silueta
silhouette_scores = silhouette_score(df_scaled, labels)
print(f"Puntuación de Silueta: {silhouette_scores:.4f}")
print("Cantidad de empresas por cluster:\n", df["cluster"].value_counts().sort_index())
{0, -1}
Número de clusters: 1
Número de puntos de ruido: 4
Puntuación de Silueta: 0.6100
Cantidad de empresas por cluster:
-1 4
0 170
Name: cluster, dtype: int64
# Lista de variables que deseas graficar
variables = ["Liquidez", "Endeudamiento", "UtilidadesAcumuladas", "Margen_EBIT"]
# Crear una figura con subplots
fig, axes = plt.subplots(nrows=2, ncols=2, figsize=(20, 12))
# Aplanar el array de ejes para un fácil acceso
axes = axes.flatten()
# Iterar sobre cada variable para graficar en su respectivo subplot
for i, var in enumerate(variables):
sns.boxplot(x="cluster", y=var, data=df, palette="tab10", ax=axes[i])
axes[i].set_title(f"Boxplot de {var} por Cluster")
# Ajustar el layout para evitar solapamientos
plt.tight_layout()
plt.show()
sns.pairplot(df, hue="cluster", palette="tab10")
plt.show()
# Datos atípicos
print(df[df["cluster"] == -1])
# Índices de los datos atípicos
index_atipicos = df[df["cluster"] == -1].index
print("Índices de los datos atípicos:", index_atipicos)
Liquidez Endeudamiento UtilidadesAcumuladas Margen_EBIT cluster
165 1.022211 0.724341 17662216.0 0.024441 -1
166 1.181853 0.378594 16511616.0 -0.019511 -1
168 0.437121 0.961229 -23717894.0 0.023014 -1
172 0.994625 0.624813 40820504.0 0.015182 -1
Índices de los datos atípicos: Int64Index([165, 166, 168, 172], dtype='int64')
# Crear una lista para almacenar las filas seleccionadas
filas_atipicas = []
# Iterar sobre los índices y seleccionar las filas correspondientes
for index in index_atipicos:
filas_atipicas.append(combined_data.iloc[index])
# Convertir la lista de filas seleccionadas en un DataFrame
filas_atipicas_df = pd.DataFrame(filas_atipicas)
# Mostrar el DataFrame con las filas atípicas
print(filas_atipicas_df)
Razón social de la sociedad Liquidez Endeudamiento 165 CARIBE SA 1.022211 0.724341
166 EL ARROZAL Y CIA SCA 1.181853 0.378594
168 IN BOND GEMA SAS 0.437121 0.961229
172 INVERCOMER DEL CARIBE SAS 0.994625 0.624813
UtilidadesAcumuladas Margen_EBIT Tipo
165 17662216.0 0.024441 Grande
166 16511616.0 -0.019511 Grande
168 -23717894.0 0.023014 Grande
172 40820504.0 0.015182 Grande
Las anteriores empresas solo son datos atípicos por las Utilidades Acumuladas.