Cross Validation#
¿Cómo seleccionamos los mejores puntos para el entrenamiento y los mejores puntos para las pruebas?
Train-Test#
Podemos usar la validación cruzada (Cross Validation) para determinar estos dos conjuntos de datos (train y test) manera imparcial.
En lugar de preocuparnos demasiado por cuáles puntos específicos son mejores para el entrenamiento y cuáles para las pruebas, la validación cruzada utiliza todos los puntos para ambos de manera iterativa, lo que significa que los usamos en etapas.
La validación cruzada resuelve el problema de no saber cuáles puntos son los mejores para las pruebas utilizándolos todos de manera iterativa. El primer paso es asignar aleatoriamente los datos a diferentes grupos.
El error se mide para cada punto en los datos de prueba y se sigue iterando hasta que todos los grupos de datos también tengan su turno para ser utilizados en las pruebas.
Si se tienen 3 grupos de puntos de datos, se realizan 3 iteraciones, lo que garantiza que cada grupo se utilice para testing. El número de iteraciones también se denomina Folds (pliegues), por lo que esto se llama validación cruzada de 3-Fold (3-Fold Cross Validation).

Cross-Validation#
K-Fold Cross Validation:#
K subconjuntos distintos de tamaño aproximadamente igual (Folds=).
Seleccionados de manera aleatoria y sin reemplazo. El remuestreo se
realiza de manera que ningún par de conjutnos de test se superponga.
El entrenamiento se realiza con K-1 subconjuntos, y el subconjunto restante se utiliza para la validación, midiendo así el rendimiento. Este proceso se repite hasta que cada uno de los K subconjuntos haya sido utilizado para la validación. El rendimiento final es el promedio de los resultados de los K subconjuntos de validación.
Dado que cada iteración utiliza una combinación diferente de datos para training, cada una resulta en una línea ajustada ligeramente distinta. Esta variación en la línea ajustada, combinada con el uso de distintos datos para testing, produce errores de predicción diferentes en cada iteración. Podemos promediar estos errores para obtener una idea general del rendimiento del modelo con datos futuros, o bien compararlos con los errores generados por otro método en cada iteración.
Lo más común es usar 5-Folds Cross Validation o 10-Folds Cross Validation.
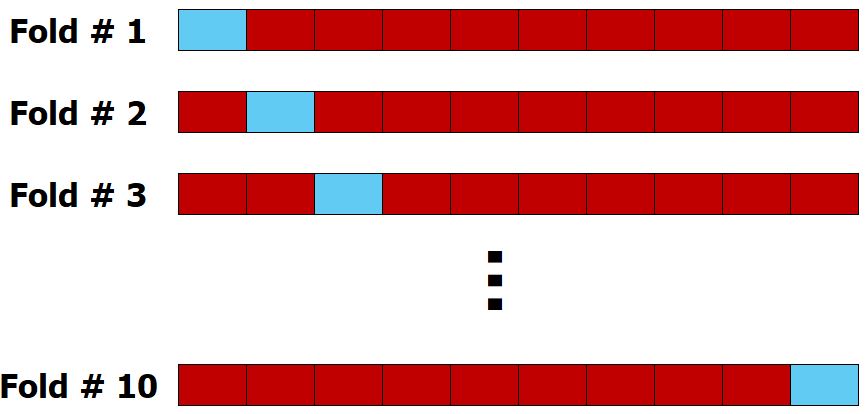
Folds#
La única manera de determinar si un método de aprendizaje automático ha sobreajustado los datos de entrenamiento es probarlo con datos nuevos que no ha visto antes. Esto se conoce como capacidad de generalización. La capacidad de generalización se evalúa con nuevos datos, pero antes se puede estimar el rendimiento predictivo mediante el remuestreo de datos, como la validación cruzada.
Es muy fácil construir un modelo que se adapte perfectamente al conjunto de datos de entrenamiento, pero que luego no pueda generalizar bien a datos no vistos. En estos casos, el modelo se ajusta tanto que incluso modela el ruido presente en los datos.
Reutilizar los mismos datos para el entrenamiento y las pruebas se llama filtración de datos (Data Leakage), y generalmente resulta en la creencia de que el método de aprendizaje automático tendrá un mejor rendimiento del que realmente tiene porque está sobreajustado.