GRU#
Kyunghyun Cho et al. propusieron la celda de Unidad Recurrente Cerrada (GRU- Gated Recurrent Unit) (ver figura).
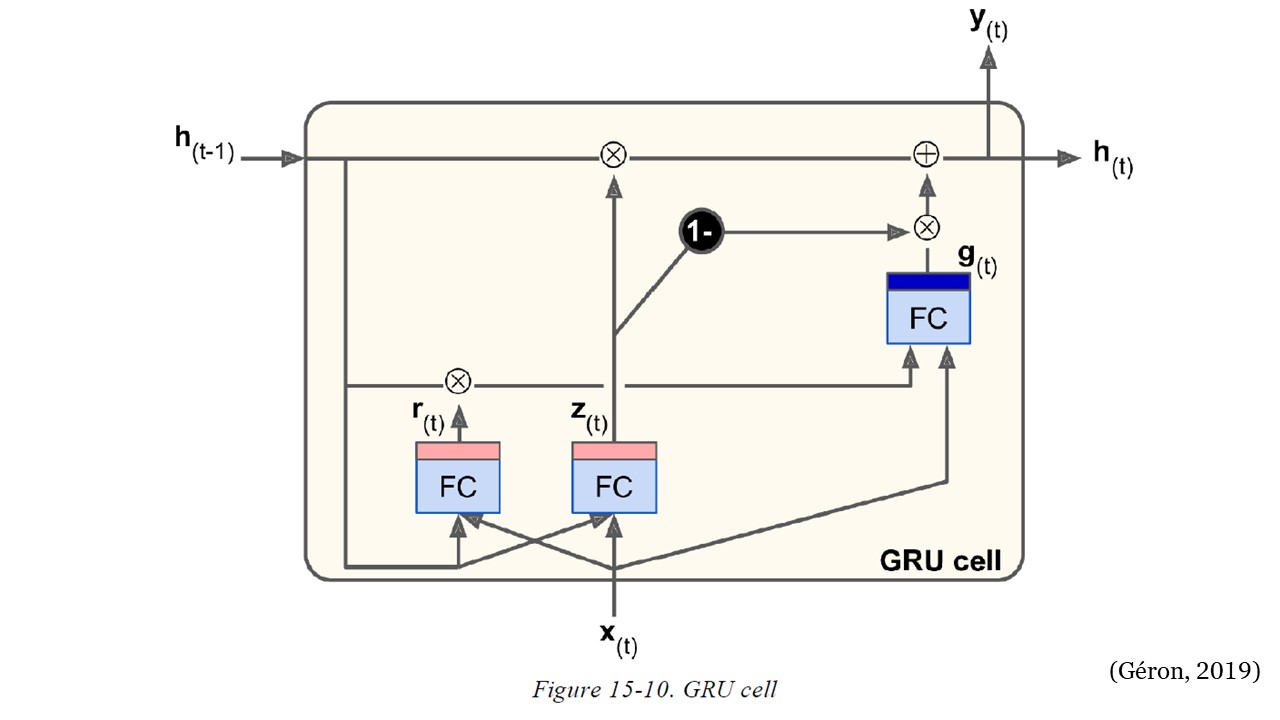
GRU#
La celda GRU es una versión simplificada de la celda LSTM y parece funcionar igual de bien (lo que explica su creciente popularidad). Estas son las principales simplificaciones:
Ambos vectores de estado se fusionan en un solo vector \(h_{(t)}\).
Un único controlador de puerta \(z_{(t)}\) controla tanto la puerta de olvido como la puerta de entrada. Si el controlador de puerta emite un 1, la puerta de olvido está abierta (= 1) y la puerta de entrada está cerrada (1 – 1 = 0). Si da como resultado un 0, sucede lo contrario. En otras palabras, cada vez que se debe almacenar una memoria, primero se borra la ubicación donde se almacenará. En realidad, esta es una variante frecuente de la celda LSTM en sí misma.
No hay puerta de salida; el vector de estado completo se emite en cada paso de tiempo. Sin embargo, hay un nuevo controlador de puerta \(r_{(t)}\) que controla qué parte del estado anterior se mostrará a la capa principal \((g_{(t)})\).
Las siguientes ecuaciones resumen cómo calcular el estado de la celda en cada paso de tiempo para una sola instancia.
Las células LSTM y GRU son una de las principales razones del éxito de las RNN. Sin embargo, aunque pueden abordar secuencias mucho más largas que las RNN simples, todavía tienen una memoria a corto plazo bastante limitada y les resulta difícil aprender patrones a largo plazo en secuencias de 100 pasos de tiempo o más, como muestras de audio de mucho tiempo. series u oraciones largas.
Código:#
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import yfinance as yf
from sklearn.preprocessing import StandardScaler
import warnings # Para ignorar mensajes de advertencia
warnings.filterwarnings("ignore")
Descargar datos desde Yahoo Finance:#
tickers = ["ES=F"]
ohlc = yf.download(tickers, period="max")
print(ohlc.tail())
[*******************100%*********************] 1 of 1 completed
Open High Low Close Adj Close Volume
Date
2022-08-24 4128.25 4158.50 4110.75 4142.75 4142.75 1348612
2022-08-25 4148.75 4202.75 4143.00 4201.00 4201.00 1635476
2022-08-26 4198.25 4217.25 4042.75 4059.50 4059.50 2241117
2022-08-29 4024.00 4064.00 4006.75 4031.25 4031.25 1963446
2022-08-30 4035.75 4072.75 3964.50 3987.50 3987.50 1963446
df = ohlc["Adj Close"].dropna(how="all")
df.tail()
Date
2022-08-24 4142.75
2022-08-25 4201.00
2022-08-26 4059.50
2022-08-29 4031.25
2022-08-30 3987.50
Name: Adj Close, dtype: float64
df = np.array(df[:, np.newaxis])
df.shape
(5548, 1)
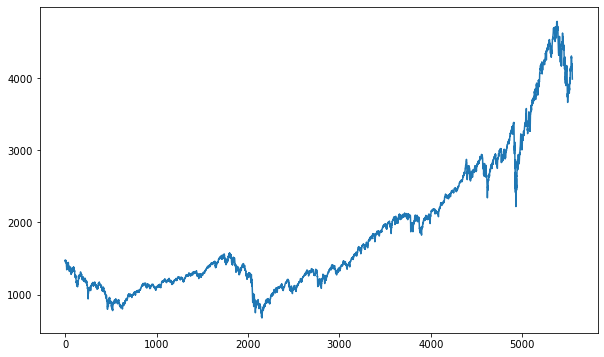
plt.figure(figsize=(10, 6))
plt.plot(df)
plt.show()
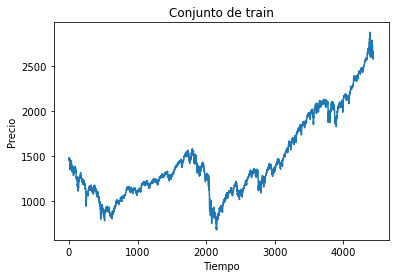
Conjunto de train y test:#
time_test = 0.20
train = df[: int(len(df) * (1 - time_test))]
test = df[int(len(df) * (1 - time_test)) :]
plt.plot(train)
plt.xlabel("Tiempo")
plt.ylabel("Precio")
plt.title("Conjunto de train")
plt.show()
plt.plot(test)
plt.xlabel("Tiempo")
plt.ylabel("Precio")
plt.title("Conjunto de test")
plt.show()
Función para conformar el dataset para datos secuenciales:
def split_sequence(sequence, time_step):
X, y = list(), list()
for i in range(len(sequence)):
end_ix = i + time_step
if end_ix > len(sequence) - 1:
break
seq_x, seq_y = sequence[i:end_ix], sequence[end_ix]
X.append(seq_x)
y.append(seq_y)
return np.array(X), np.array(y)
time_step = 5
X_train, y_train = split_sequence(train, time_step)
X_test, y_test = split_sequence(test, time_step)
Arquitectura de la red con celdas GRU:#
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import GRU
model = Sequential()
model.add(GRU(10, activation="relu", return_sequences=True))
model.add(GRU(10, activation="relu", return_sequences=True))
model.add(GRU(4, activation="relu"))
model.add(Dense(1)) # última capa Dense
model.compile(optimizer="adam", loss="mse")
history = model.fit(
X_train,
y_train,
validation_data=(X_test, y_test),
epochs=50,
batch_size=100,
verbose=0
)
Evaluación del desempeño:#
mse = model.evaluate(X_test, y_test, verbose=0)
mse
2123.21630859375
rmse = mse ** 0.5
rmse
46.07837137523146
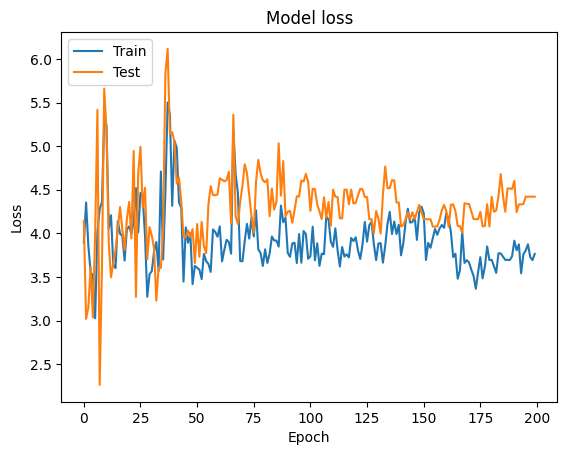
plt.plot(range(1, len(history.epoch) + 1), history.history["loss"], label="Train")
plt.plot(range(1, len(history.epoch) + 1), history.history["val_loss"], label="Test")
plt.xlabel("epoch")
plt.ylabel("Loss")
plt.legend();
Predicción del modelo con valores sin escalar:#
y_pred = model.predict(X_test, verbose=0)
y_pred[0:5]
array([[2657.94 ],
[2669.9927],
[2693.0232],
[2705.2556],
[2697.1033]], dtype=float32)
plt.figure(figsize=(18, 6))
plt.plot(
range(1, len(X_test) + 1),
test[time_step:, :],
color="b",
marker=".",
linestyle="-",
label="True",
)
plt.plot(
range(1, len(X_test) + 1),
y_pred,
color="g",
marker=".",
linestyle="-",
label="y_pred",
)
plt.legend();
Predicción fuera de la muestra:#
predictions = []
time_prediction = 20 # cantidad de predicciones fuera de la muestra
first_sample = df[-time_step:, 0] # última muestra dentro de la serie de tiempo
current_batch = first_sample[np.newaxis] # Transformación en muestras y time step
current_batch = np.reshape(current_batch, (1, time_step, 1)) # Transformación en 3D
for i in range(time_prediction):
current_pred = model.predict(current_batch, verbose=0)[0]
# Guardar la predicción
predictions.append(current_pred)
# Actualizar el lote para incluir ahora la predicción y soltar el primer valor (primer time step)
current_batch = np.append(current_batch[:, 1:], [[current_pred]])[np.newaxis]
current_batch = np.reshape(current_batch, (1, time_step, 1)) # Transformación en 3D
plt.figure(figsize=(10, 6))
plt.plot(
range(1, len(df[-100:, 0]) + 1),
df[-100:, 0],
color="b",
marker=".",
linestyle="-",
label="True",
)
plt.plot(
range(len(df[-100:, 0]) + 1, len(df[-100:, 0]) + len(predictions) + 1),
predictions,
color="g",
marker=".",
linestyle="-",
label="y_pred fuera de la muestra",
)
plt.legend();