Ejemplo empresas en Reorganización - Regularización#
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.ticker as mtick
import seaborn as sns
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from keras.models import Sequential
from keras.layers import Dense, InputLayer, Dropout
from keras.optimizers import Adam
from keras.optimizers import RMSprop
from keras.callbacks import EarlyStopping
from sklearn.metrics import classification_report, confusion_matrix, roc_auc_score, roc_curve
from sklearn.metrics import ConfusionMatrixDisplay, precision_score, precision_recall_curve, recall_score, accuracy_score, f1_score
# path = "BD empresas re organización.xlsx"
path = "BD empresas en re organización.xlsx"
xls = pd.ExcelFile(path)
df = pd.read_excel(path, sheet_name=xls.sheet_names[0])
df.head()
| Razón Social | Margen EBIT | Carga financiera | Margen neto | CxC | CxP | Solvencia | Apalancamiento | En Reorganización | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | AACER SAS | 0.071690 | 0.000000 | 0.042876 | 0.104095 | 0.153192 | 1.877078 | 1.642505 | 0 |
| 1 | ABARROTES EL ROMPOY SAS | 0.017816 | 0.000000 | 0.010767 | 0.018414 | 0.000000 | 0.000000 | 0.865044 | 0 |
| 2 | ABASTECIMIENTOS INDUSTRIALES SAS | 0.144646 | 0.054226 | 0.059784 | 0.227215 | 0.025591 | 1.077412 | 1.272299 | 0 |
| 3 | ACME LEON PLASTICOS SAS | 0.004465 | 0.000000 | -0.013995 | 0.073186 | 0.127866 | 0.000000 | 1.391645 | 0 |
| 4 | ADVANCED PRODUCTS COLOMBIA SAS | 0.141829 | 0.050810 | 0.053776 | 0.398755 | 0.147678 | 0.675073 | 2.118774 | 0 |
df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 629 entries, 0 to 628
Data columns (total 9 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Razón Social 629 non-null object
1 Margen EBIT 629 non-null float64
2 Carga financiera 629 non-null float64
3 Margen neto 629 non-null float64
4 CxC 629 non-null float64
5 CxP 629 non-null float64
6 Solvencia 629 non-null float64
7 Apalancamiento 629 non-null float64
8 En Reorganización 629 non-null int64
dtypes: float64(7), int64(1), object(1)
memory usage: 44.4+ KB
# Conteo absoluto
conteo_clases = df['En Reorganización'].value_counts()
# Porcentaje
porcentaje_clases = df['En Reorganización'].value_counts(normalize=True) * 100
# Mostrar conteo y porcentaje
print("Cantidad de empresas por clase:")
print(conteo_clases)
print("\nPorcentaje de empresas por clase:")
print(porcentaje_clases.round(2))
Cantidad de empresas por clase:
En Reorganización
1 342
0 287
Name: count, dtype: int64
Porcentaje de empresas por clase:
En Reorganización
1 54.37
0 45.63
Name: proportion, dtype: float64
Red Neuronal Artificial:#
df.columns
Index(['Razón Social', 'Margen EBIT', 'Carga financiera', 'Margen neto', 'CxC',
'CxP', 'Solvencia', 'Apalancamiento', 'En Reorganización'],
dtype='object')
# ------------------------
# Selección de variables
# ------------------------
variables_seleccionadas = ['Margen EBIT',
'Carga financiera',
'Margen neto',
'CxC',
'CxP',
'Solvencia',
'Apalancamiento']
# Variable objetivo
target = 'En Reorganización'
# ------------------------
# Preparar datos
# ------------------------
X = df[variables_seleccionadas]
y = df[target]
# Estandarizar variables
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# Dividir en entrenamiento y prueba (70%-30%)
X_train, X_test, y_train, y_test = train_test_split(X_scaled, y, test_size=0.3, random_state=35, stratify=y)
model = Sequential()
model.add(InputLayer(shape=(X_train.shape[1],)))
model.add(Dense(10, activation='relu'))
model.add(Dense(10, activation='relu'))
model.add(Dense(1, activation='sigmoid')) # 'sigmoid' porque es clasifiación binaria
model.compile(loss='binary_crossentropy', optimizer=Adam(learning_rate=0.001), metrics=['accuracy'])
history = model.fit(X_train, y_train,
validation_data=(X_test, y_test),
epochs=200,
batch_size=32,
verbose=0
)
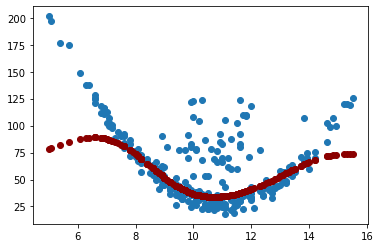
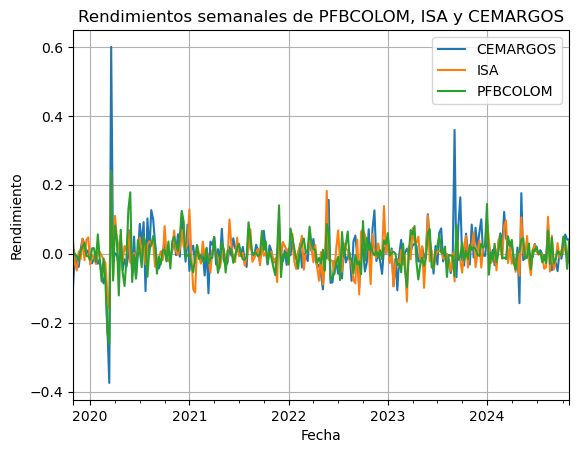
# Graficar Loss y Val Loss:
plt.figure(figsize=(5, 5))
plt.plot(history.history["loss"], color="blue")
plt.plot(history.history["val_loss"], color="red")
plt.title("Loss vs Val Loss")
plt.legend(["loss", "val_loss"])
plt.show()
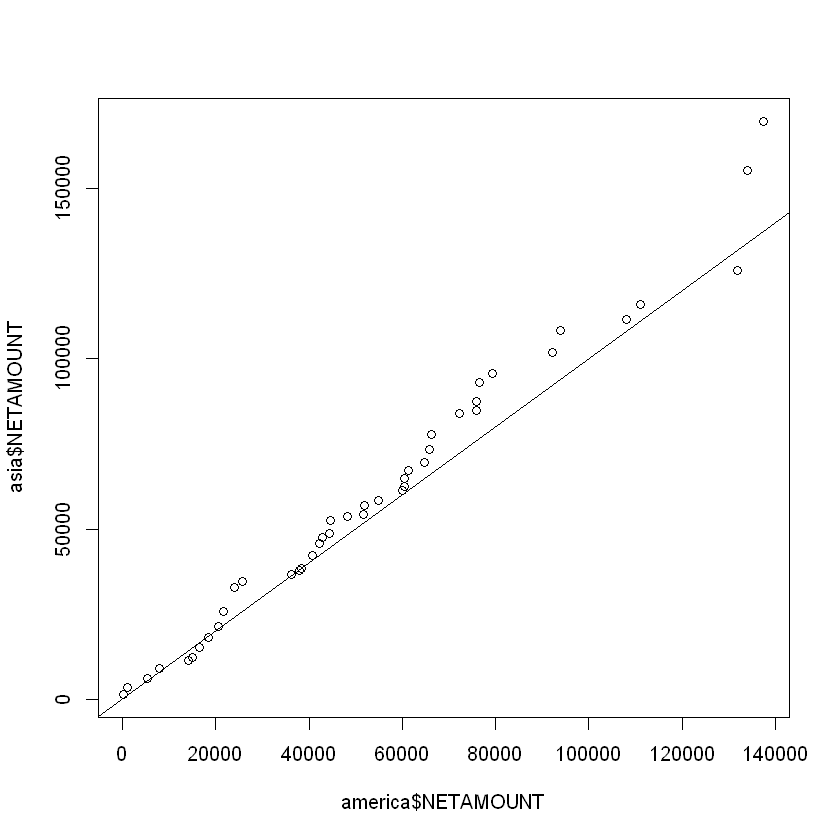
Regularización#
Dropout
Early Stopping
model = Sequential()
model.add(InputLayer(shape=(X_train.shape[1],)))
model.add(Dense(10, activation='relu'))
model.add(Dropout(0.2))
model.add(Dense(10, activation='relu'))
model.add(Dropout(0.2))
model.add(Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy', optimizer=Adam(learning_rate=0.001), metrics=['accuracy'])
callback = EarlyStopping(monitor='val_loss', patience=10, restore_best_weights=False)
history = model.fit(X_train, y_train,
validation_data=(X_test, y_test),
epochs=200,
batch_size=32,
callbacks=[callback],
verbose=0
)
# Graficar Loss y Val Loss:
plt.figure(figsize=(5, 5))
plt.plot(history.history["loss"], color="blue")
plt.plot(history.history["val_loss"], color="red")
plt.title("Loss vs Val Loss")
plt.legend(["loss", "val_loss"])
plt.show()
Predicción#
y_prob_train = model.predict(X_train, verbose=0).flatten()
y_prob_test = model.predict(X_test, verbose=0).flatten()
# Calcular y_pred_train y y_pred_train con umbral de 0.5
umbral = 0.5
y_pred_train = np.where(y_prob_train >= umbral, 1, 0)
y_pred = np.where(y_prob_test >= umbral, 1, 0)
Evaluación del modelo#
# ------------------------
# Evaluación del modelo
# ------------------------
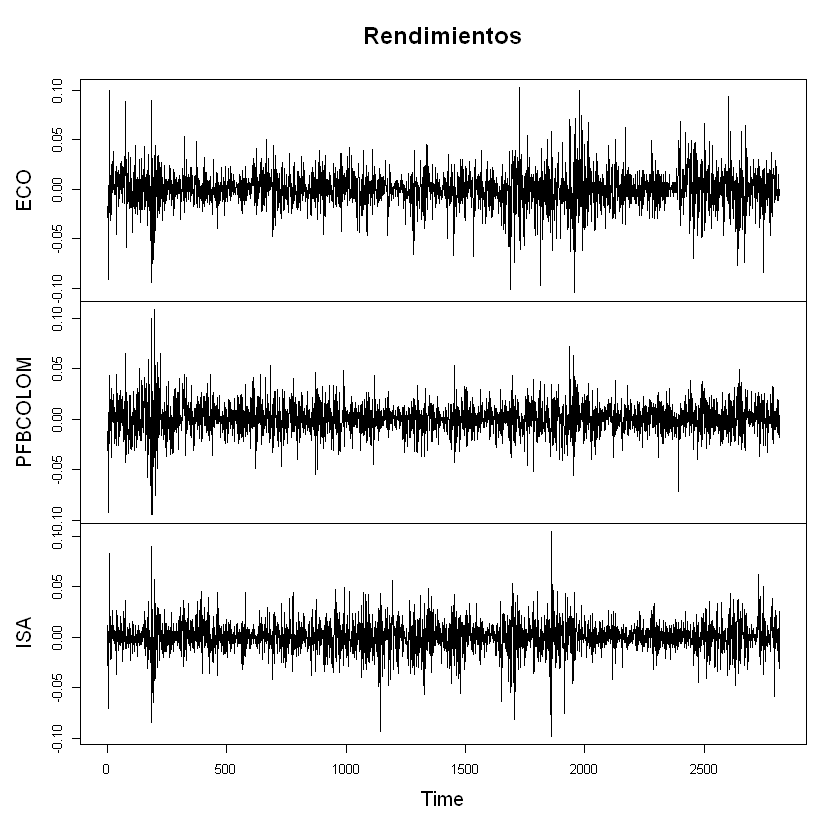
cm_train = confusion_matrix(y_train, y_pred_train, labels=[0,1])
cm_df_train = pd.DataFrame(cm_train, index=["Real 0", "Real 1"], columns=["Predicho 0", "Predicho 1"])
plt.figure(figsize=(5.2,4.2))
sns.heatmap(cm_train, annot=True, fmt="d", cbar=True, linewidths=.5, cmap="coolwarm")
plt.title("Matriz de confusión - train")
plt.xlabel("Predicho"); plt.ylabel("Real")
plt.tight_layout()
plt.show()
cm = confusion_matrix(y_test, y_pred, labels=[0,1])
cm_df = pd.DataFrame(cm, index=["Real 0", "Real 1"], columns=["Predicho 0", "Predicho 1"])
plt.figure(figsize=(5.2,4.2))
sns.heatmap(cm_df, annot=True, fmt="d", cbar=True, linewidths=.5, cmap="coolwarm")
plt.title("Matriz de confusión - Test")
plt.xlabel("Predicho"); plt.ylabel("Real")
plt.tight_layout()
plt.show()
print("\n=== Reporte de Clasificación - train ===")
print(classification_report(y_train, y_pred_train))
print("\n=== Reporte de Clasificación - test ===")
print(classification_report(y_test, y_pred))
=== Reporte de Clasificación - train ===
precision recall f1-score support
0 0.71 0.92 0.80 201
1 0.91 0.68 0.78 239
accuracy 0.79 440
macro avg 0.81 0.80 0.79 440
weighted avg 0.82 0.79 0.79 440
=== Reporte de Clasificación - test ===
precision recall f1-score support
0 0.68 0.87 0.76 86
1 0.86 0.65 0.74 103
accuracy 0.75 189
macro avg 0.77 0.76 0.75 189
weighted avg 0.78 0.75 0.75 189
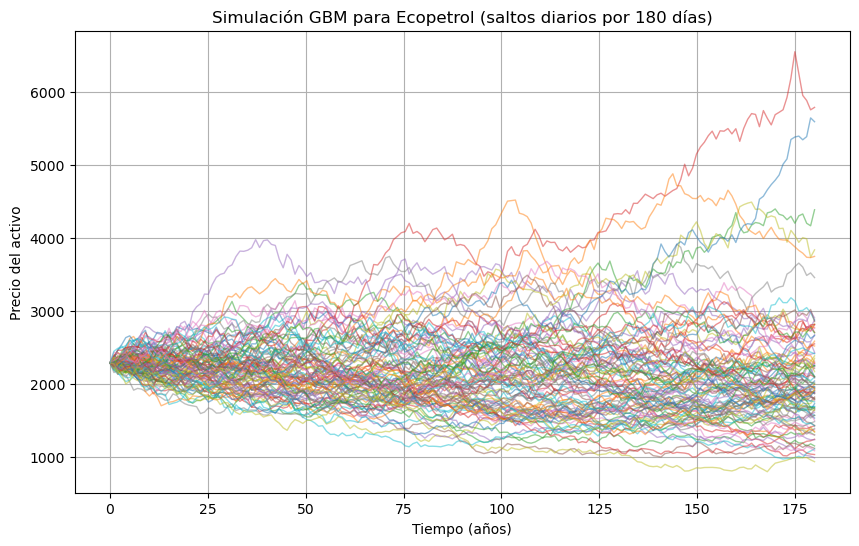
Curva ROC#
La curva ROC (Receiver Operating Characteristic) muestra el desempeño de un modelo de clasificación para todos los posibles umbrales.
Eje X: FPR (False Positive Rate)
Eje Y: TPR (True Positive Rate o Recall) - Sensibilidad
Cada punto de la curva = un umbral diferente
La curva muestra el trade-off entre:
Sensibilidad (TPR) - Recall
Falsos positivos (FPR)
El AUC (Area Under the Curve) mide el área bajo la curva ROC, no depende del umbral
# ============================
# ROC AUC Score
# ============================
auc_train = roc_auc_score(y_train, y_prob_train)
auc_test = roc_auc_score(y_test, y_prob_test)
print(f"ROC AUC - Train: {auc_train:.3f}")
print(f"ROC AUC - Test : {auc_test:.3f}")
# ============================
# Curva ROC (Train y Test)
# ============================
fpr_train, tpr_train, _ = roc_curve(y_train, y_prob_train)
fpr_test, tpr_test, _ = roc_curve(y_test, y_prob_test)
plt.figure(figsize=(8, 6))
plt.plot(fpr_train, tpr_train, label=f'Train (AUC = {auc_train:.2f})', color='blue')
plt.plot(fpr_test, tpr_test, label=f'Test (AUC = {auc_test:.2f})', color='orange')
plt.plot([0, 1], [0, 1], 'k--', label='Azar')
plt.xlabel("False Positive Rate")
plt.ylabel("True Positive Rate")
plt.title("Curva ROC - Train y Test")
plt.legend(loc="lower right")
plt.grid(True)
plt.tight_layout()
plt.show()
ROC AUC - Train: 0.873
ROC AUC - Test : 0.847
Curva Precisión / Recall#
La curva Precision–Recall (PR) muestra el desempeño del modelo para distintos umbrales, enfocándose en la clase positiva.
# Calcular precisión y recall para diferentes umbrales
precision, recall, thresholds = precision_recall_curve(y_test, y_prob_test)
# Agregar el umbral 0 para completar el array de thresholds
thresholds = np.append(thresholds, 1)
# Graficar precisión y recall en función del umbral
plt.figure(figsize=(10, 6))
plt.plot(thresholds, precision, label="Precisión")
plt.plot(thresholds, recall, label="Recall")
plt.xlabel("Umbral")
plt.ylabel("Precisión/Recall")
plt.title("Precisión y Recall en función del umbral")
plt.legend()
plt.grid(True)
plt.show()
Tasa de positivos por decil#
El gráfico se construye ordenando las observaciones según la probabilidad estimada por el modelo de mayor a menor. Luego, estas observaciones se dividen en deciles (grupos del mismo tamaño) y, para cada decil, se calcula la proporción de la clase positiva real respecto al total de observaciones en ese grupo. Esto permite evaluar si el modelo concentra los casos positivos en los deciles de mayor riesgo.
Decil 1 → mayor probabilidad predicha
Decil 10 → menor probabilidad predicha
Muestra qué tan bien el modelo concentra los positivos en los primeros deciles.
El gráfico responde: Entre los casos que el modelo considera más riesgosos (según probabilidad), qué proporción realmente es positiva.
Curva decreciente = buen modelo
Si el modelo ordena bien el riesgo, entonces:
el decil 1 debe tener la tasa más alta de positivos
los siguientes deciles deben ir bajando
el decil 10 debe tener la tasa más baja
Es decir, una curva descendente indica que el modelo sí está separando bien los casos.
Tasa de positivos por decil:
Esto significa: De todas las observaciones que quedaron en ese decil, qué proporción realmente pertenece a la clase positiva.
# DataFrame con probas y clase real
df_deciles = pd.DataFrame({'y_real': y_test, 'y_proba': y_prob_test})
# Crear deciles (1 = más alto riesgo, 10 = más bajo)
df_deciles['Decil'] = pd.qcut(df_deciles['y_proba'], 10, labels=False, duplicates='drop') + 1
df_deciles['Decil'] = 11 - df_deciles['Decil'] # invertir para que el decil 1 sea el de mayor probabilidad
# Calcular tasa por decil
tabla_deciles = df_deciles.groupby('Decil').agg(
Total=('y_real','count'),
Positivos=('y_real','sum')
)
tabla_deciles['Tasa'] = tabla_deciles['Positivos'] / tabla_deciles['Total']
print(f"Tasa de positivos reales en test: {df_deciles['y_real'].mean():.2f}")
print(tabla_deciles)
# --- 📊 Gráfico ---
plt.figure(figsize=(8,5))
plt.plot(tabla_deciles.index, tabla_deciles['Tasa'], marker='o', linestyle='-', color='blue')
plt.title("Tasa de positivos por decil")
plt.xlabel("Decil")
plt.ylabel("Tasa de clase 1")
plt.grid(True)
plt.show()
Tasa de positivos reales en test: 0.54
Total Positivos Tasa
Decil
1 19 19 1.000000
2 19 18 0.947368
3 19 18 0.947368
4 19 11 0.578947
5 18 9 0.500000
6 19 10 0.526316
7 19 6 0.315789
8 19 4 0.210526
9 19 5 0.263158
10 19 3 0.157895