Mejor modelo - Precio electricidad#
# Importar librerías:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.dates as mdates
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler
from sklearn.metrics import mean_squared_error, r2_score, mean_absolute_error
from scipy.stats import boxcox
from scipy.special import inv_boxcox
from keras.models import load_model
import statsmodels.api as sm
from scipy.stats import norm
from statsmodels.graphics.tsaplots import plot_acf, plot_pacf
# warning
import warnings
warnings.filterwarnings("ignore")
Función para evaluar el modelo#
def evaluar_modelo_ts(
model,
X_train, y_train,
X_test, y_test,
train_index,
test_index,
lags,
scaler=None,
transformacion=None,
lambda_bc=None,
nombre_modelo="Modelo",
nombre_serie="Serie",
):
"""
Evalúa un modelo de series de tiempo ya entrenado.
Muestra métricas de desempeño y un gráfico de ajuste
en train y test.
Parámetros
----------
model : keras Model
Modelo ya cargado / entrenado.
X_train, y_train, X_test, y_test : np.array
Datos de entrenamiento y prueba (ya con lags aplicados).
train_index, test_index : pd.DatetimeIndex o array-like
Índices temporales COMPLETOS (antes de crear lags).
lags : int
Número de rezagos usados para crear X/y.
scaler : sklearn scaler o None
Para invertir el escalado.
transformacion : str o None
"log", "boxcox" o None.
lambda_bc : float o None
Lambda de Box-Cox.
nombre_modelo : str
Nombre para mostrar en títulos.
nombre_serie : str
Nombre de la serie para el eje Y.
Retorna
-------
metricas : dict
Diccionario con todas las métricas calculadas.
"""
# -------------------------------------------------
# Funciones de inversión
# -------------------------------------------------
def invertir_a_escala_original(valores):
resultado = valores.copy().flatten()
if scaler is not None:
resultado = scaler.inverse_transform(
resultado.reshape(-1, 1)
).flatten()
if transformacion == "log":
resultado = np.exp(resultado)
elif transformacion == "boxcox":
resultado = inv_boxcox(resultado, lambda_bc)
return resultado
# -------------------------------------------------
# Predicciones
# -------------------------------------------------
y_train_pred = model.predict(X_train, verbose=0).flatten()
y_test_pred = model.predict(X_test, verbose=0).flatten()
idx_train = train_index[lags:]
idx_test = test_index[lags:]
hay_inversion = (scaler is not None) or (transformacion is not None)
# -------------------------------------------------
# Métricas en espacio escalado
# -------------------------------------------------
rmse_train = np.sqrt(mean_squared_error(y_train, y_train_pred))
rmse_test = np.sqrt(mean_squared_error(y_test, y_test_pred))
mae_train = mean_absolute_error(y_train, y_train_pred)
mae_test = mean_absolute_error(y_test, y_test_pred)
r2_train = r2_score(y_train, y_train_pred)
r2_test = r2_score(y_test, y_test_pred)
metricas = {
"rmse_train_scaled": rmse_train,
"rmse_test_scaled": rmse_test,
"mae_train_scaled": mae_train,
"mae_test_scaled": mae_test,
"r2_train_scaled": r2_train,
"r2_test_scaled": r2_test,
}
# -------------------------------------------------
# Métricas en escala original
# -------------------------------------------------
if hay_inversion:
y_tr_inv = invertir_a_escala_original(y_train)
y_te_inv = invertir_a_escala_original(y_test)
y_tr_pred_inv = invertir_a_escala_original(y_train_pred)
y_te_pred_inv = invertir_a_escala_original(y_test_pred)
rmse_train_o = np.sqrt(mean_squared_error(y_tr_inv, y_tr_pred_inv))
rmse_test_o = np.sqrt(mean_squared_error(y_te_inv, y_te_pred_inv))
mae_train_o = mean_absolute_error(y_tr_inv, y_tr_pred_inv)
mae_test_o = mean_absolute_error(y_te_inv, y_te_pred_inv)
r2_train_o = r2_score(y_tr_inv, y_tr_pred_inv)
r2_test_o = r2_score(y_te_inv, y_te_pred_inv)
metricas.update({
"rmse_train_original": rmse_train_o,
"rmse_test_original": rmse_test_o,
"mae_train_original": mae_train_o,
"mae_test_original": mae_test_o,
"r2_train_original": r2_train_o,
"r2_test_original": r2_test_o,
})
else:
y_tr_inv = y_train
y_te_inv = y_test
y_tr_pred_inv = y_train_pred
y_te_pred_inv = y_test_pred
rmse_train_o = rmse_train
rmse_test_o = rmse_test
mae_train_o = mae_train
mae_test_o = mae_test
r2_train_o = r2_train
r2_test_o = r2_test
# -------------------------------------------------
# Imprimir métricas
# -------------------------------------------------
print(f"\n{'═'*62}")
print(f" {nombre_modelo}")
print(f"{'═'*62}")
if hay_inversion:
print(f"\n ▸ Espacio escalado/transformado:")
print(f" {'Métrica':<12} {'Train':>12} {'Test':>12}")
print(f" {'─'*36}")
print(f" {'RMSE':<12} {rmse_train:>12.6f} {rmse_test:>12.6f}")
print(f" {'MAE':<12} {mae_train:>12.6f} {mae_test:>12.6f}")
print(f" {'R²':<12} {r2_train:>12.6f} {r2_test:>12.6f}")
print(f"\n ▸ Escala original:")
print(f" {'Métrica':<12} {'Train':>12} {'Test':>12}")
print(f" {'─'*36}")
print(f" {'RMSE':<12} {rmse_train_o:>12.4f} {rmse_test_o:>12.4f}")
print(f" {'MAE':<12} {mae_train_o:>12.4f} {mae_test_o:>12.4f}")
print(f" {'R²':<12} {r2_train_o:>12.6f} {r2_test_o:>12.6f}")
else:
print(f"\n {'Métrica':<12} {'Train':>12} {'Test':>12}")
print(f" {'─'*36}")
print(f" {'RMSE':<12} {rmse_train_o:>12.6f} {rmse_test_o:>12.6f}")
print(f" {'MAE':<12} {mae_train_o:>12.6f} {mae_test_o:>12.6f}")
print(f" {'R²':<12} {r2_train_o:>12.6f} {r2_test_o:>12.6f}")
print(f"{'═'*62}\n")
# -------------------------------------------------
# Gráfico de ajuste (estilo ggplot)
# -------------------------------------------------
with plt.style.context("ggplot"):
plt.figure(figsize=(12, 6))
plt.plot(idx_train, y_tr_inv, label="Real Train", color="black")
plt.plot(
idx_train, y_tr_pred_inv,
label="Ajuste Train", color="tab:blue",
)
plt.plot(idx_test, y_te_inv, label="Real Test", color="black")
plt.plot(
idx_test, y_te_pred_inv,
label="Pronóstico Test", color="tab:green",
)
plt.title(f"Ajuste y pronóstico - {nombre_modelo}")
plt.xlabel("Tiempo")
plt.ylabel(nombre_serie)
plt.legend()
plt.tight_layout()
plt.show()
return metricas
Función para analizar los residuales#
def analisis_residuales(
residuals,
nombre: str = "Serie de tiempo",
lags: int = 24,
color_resid: str = "navy",
color_qq: str = "navy",
color_acf_pacf: str = "navy"
):
"""
Análisis gráfico de residuales:
- Residuales en el tiempo (toda la fila superior)
- Histograma + curva normal (izq), QQ-plot (der)
- ACF (izq), PACF (der) con bandas y barras color navy
"""
residuals = residuals[1:].dropna()
# Ensure mu and sigma are scalar values
if isinstance(residuals, pd.DataFrame) and 'Precio' in residuals.columns:
mu = residuals['Precio'].mean()
sigma = residuals['Precio'].std(ddof=1)
elif isinstance(residuals, pd.Series):
mu = residuals.mean()
sigma = residuals.std(ddof=1)
else:
mu = residuals.mean().iloc[0] if hasattr(residuals.mean(), 'iloc') else residuals.mean()
sigma = residuals.std(ddof=1).iloc[0] if hasattr(residuals.std(ddof=1), 'iloc') else residuals.std(ddof=1)
x = np.linspace(residuals.min().min() if isinstance(residuals, pd.DataFrame) else residuals.min(),
residuals.max().max() if isinstance(residuals, pd.DataFrame) else residuals.max(),
400)
pdf = norm.pdf(x, loc=mu, scale=sigma)
with plt.style.context("ggplot"):
fig = plt.figure(constrained_layout=True, figsize=(14, 11))
gs = fig.add_gridspec(3, 2, height_ratios=[1, 1, 1])
# 1. Residuales en el tiempo
ax_time = fig.add_subplot(gs[0, :])
ax_time.scatter(residuals.index, residuals, color=color_resid, alpha=0.7, s=20)
ax_time.axhline(0, ls="--", color="black")
ax_time.set_title(f"Residuales en el tiempo: {nombre}", color='black')
ax_time.set_xlabel("Tiempo", color='black')
ax_time.set_ylabel("Residual", color='black')
ax_time.tick_params(axis='both', labelsize=11, colors='black')
# 2. Histograma + curva Normal
ax_hist = fig.add_subplot(gs[1, 0])
ax_hist.hist(residuals, bins="auto", density=True, alpha=0.6, edgecolor="k", color="royalblue")
ax_hist.plot(x, pdf, lw=2, label=f"N({mu:.3f}, {sigma:.3f}²)", color="darkred")
ax_hist.set_title("Histograma residuales y ajuste Normal", color='black')
ax_hist.set_xlabel("Residual", color='black')
ax_hist.set_ylabel("Densidad", color='black')
ax_hist.legend(fontsize=9)
ax_hist.grid(alpha=0.18)
ax_hist.tick_params(axis='both', labelsize=10, colors='black')
# 3. QQ-plot
ax_qq = fig.add_subplot(gs[1, 1])
qq = sm.qqplot(residuals.iloc[:, 0] if isinstance(residuals, pd.DataFrame) else residuals, line='45', fit=True, ax=ax_qq, markerfacecolor=color_qq, markeredgecolor=color_qq, marker='o')
lines = ax_qq.get_lines()
if len(lines) >= 1:
lines[0].set_color(color_qq)
lines[0].set_marker('o')
lines[0].set_linestyle('None')
if len(lines) >= 2:
lines[1].set_color("black")
lines[1].set_linestyle("--")
ax_qq.set_title("Q-Q Plot de los residuales", color='black')
ax_qq.set_xlabel("Cuantiles teóricos (Normal)", color='black')
ax_qq.set_ylabel("Cuantiles de los residuales", color='black')
ax_qq.tick_params(axis='both', labelsize=10, colors='black')
for l in ax_qq.get_xticklabels() + ax_qq.get_yticklabels():
l.set_color('black')
# 4. ACF
ax_acf = fig.add_subplot(gs[2, 0])
sm.graphics.tsa.plot_acf(residuals.iloc[:, 0] if isinstance(residuals, pd.DataFrame) else residuals, lags=lags, ax=ax_acf, zero=False, color=color_acf_pacf)
ax_acf.set_title("ACF de los residuales", color='black')
ax_acf.set_xlabel("Rezagos", color='black')
ax_acf.set_ylabel("Autocorrelación", color='black')
ax_acf.tick_params(axis='both', labelsize=10, colors='black')
# 5. PACF
ax_pacf = fig.add_subplot(gs[2, 1])
sm.graphics.tsa.plot_pacf(residuals.iloc[:, 0] if isinstance(residuals, pd.DataFrame) else residuals, lags=lags, ax=ax_pacf, zero=False, color=color_acf_pacf)
ax_pacf.set_title("PACF de los residuales", color='black')
ax_pacf.set_xlabel("Rezagos", color='black')
ax_pacf.set_ylabel("Autocorrelación parcial", color='black')
ax_pacf.tick_params(axis='both', labelsize=10, colors='black')
plt.show()
return
Datos:#
# Cargar datos:
data = pd.read_excel("Precio_diario.xlsx")
data.index = pd.to_datetime(data['Fecha'])
data.drop('Fecha', axis=1, inplace=True)
print(data.head())
plt.figure(figsize=(15,5))
plt.plot(data['Precio'], color="black", label="Precio electricidad diario")
plt.legend()
plt.show()
Precio
Fecha
2002-05-01 40.802839
2002-05-02 41.677618
2002-05-03 37.826814
2002-05-04 37.904091
2002-05-05 36.266849
# Función para crear los lags para RNA
def prepare_data(precio, n_lags):
X = []
y = []
for i in range(n_lags, len(precio)):
lag_features = precio[i - n_lags : i, 0] # Extraemos el vector de lags
X.append(lag_features)
# El target es el valor en la posición actual
y.append(precio[i, 0])
# Convertimos las listas a numpy.ndarray
X = np.array(X)
y = np.array(y)
return X, y
# Función para crear los lags para redes RNN, GRU y LSTM
def prepare_data_rnn(precio, n_lags):
X = []
y = []
for i in range(n_lags, len(precio)):
lag_features = precio[i - n_lags : i, 0] # Extraemos el vector de lags
X.append(lag_features)
# El target es el valor en la posición actual
y.append(precio[i, 0])
# Convertimos las listas a numpy.ndarray
X = np.array(X)
y = np.array(y)
X = X.reshape(X.shape[0], n_lags, 1)
return X, y
Transformaciones serie de tiempo:#
# Transformación logarítmica a la serie original
serie_log = np.log(data['Precio'])
data_log = pd.DataFrame(serie_log, columns=['Precio'])
# Transformación Box-Cox a la serie original
serie_bc, lambda_bc = boxcox(data['Precio'])
data_bc = pd.DataFrame(serie_bc, columns=['Precio'], index=data.index)
# Conjunto de Train y Test:
train, test = train_test_split(data_bc, test_size=0.30, shuffle=False)
# Escalado de variables:
scaler = MinMaxScaler()
scaler.fit(train)
train_scaled = scaler.transform(train)
test_scaled = scaler.transform(test)
Cargar mejor modelo: Redes Neuronales#
# Cargar modelo keras
model = load_model('modelo_2_GRU_lags_60.keras')
# Creación de lags:
lags = 60
X_train, y_train = prepare_data_rnn(train_scaled, lags)
X_test, y_test = prepare_data_rnn(test_scaled, lags)
Evaluación del modelo#
metricas = evaluar_modelo_ts(
model=model,
X_train=X_train, y_train=y_train,
X_test=X_test, y_test=y_test,
train_index=train.index,
test_index=test.index,
lags=lags,
scaler=scaler,
transformacion="boxcox", # o "log" o None
lambda_bc=lambda_bc,
nombre_modelo="GRU — Mejor Modelo",
nombre_serie="Precio",
)
══════════════════════════════════════════════════════════════
GRU — Mejor Modelo
══════════════════════════════════════════════════════════════
▸ Espacio escalado/transformado:
Métrica Train Test
────────────────────────────────────
RMSE 0.038879 0.034798
MAE 0.026712 0.024226
R² 0.946227 0.942441
▸ Escala original:
Métrica Train Test
────────────────────────────────────
RMSE 29.6251 82.2282
MAE 12.5171 39.6053
R² 0.956445 0.920795
══════════════════════════════════════════════════════════════
Análisis de residuales#
# Ajuste en train
y_train_pred = model.predict(X_train, verbose=0).flatten()
# Devolver scaler
y_train_pred_inv = scaler.inverse_transform(y_train_pred.reshape(-1, 1)).flatten()
y_train_pred_inv = pd.Series(y_train_pred_inv, index=train.index[lags:])
residuales = train['Precio'][lags:] - y_train_pred_inv
analisis_residuales(
residuales, # Agregar los residuales
nombre="Precio de electricidad",
)
Cargar mejor modelo: CNN#
# Cargar modelo keras
model = load_model('modelo_1_CNN_Dense_lags_40.keras')
# Creación de lags:
lags = 40
X_train, y_train = prepare_data_rnn(train_scaled, lags)
X_test, y_test = prepare_data_rnn(test_scaled, lags)
Evaluación del modelo#
metricas = evaluar_modelo_ts(
model=model,
X_train=X_train, y_train=y_train,
X_test=X_test, y_test=y_test,
train_index=train.index,
test_index=test.index,
lags=lags,
scaler=scaler,
transformacion="boxcox", # o "log" o None
lambda_bc=lambda_bc,
nombre_modelo="CNN + Dense — Mejor Modelo",
nombre_serie="Precio",
)
══════════════════════════════════════════════════════════════
CNN + Dense — Mejor Modelo
══════════════════════════════════════════════════════════════
▸ Espacio escalado/transformado:
Métrica Train Test
────────────────────────────────────
RMSE 0.044422 0.050793
MAE 0.033612 0.041175
R² 0.930954 0.876672
▸ Escala original:
Métrica Train Test
────────────────────────────────────
RMSE 65.0409 175.0175
MAE 21.4667 87.4161
R² 0.789722 0.638411
══════════════════════════════════════════════════════════════
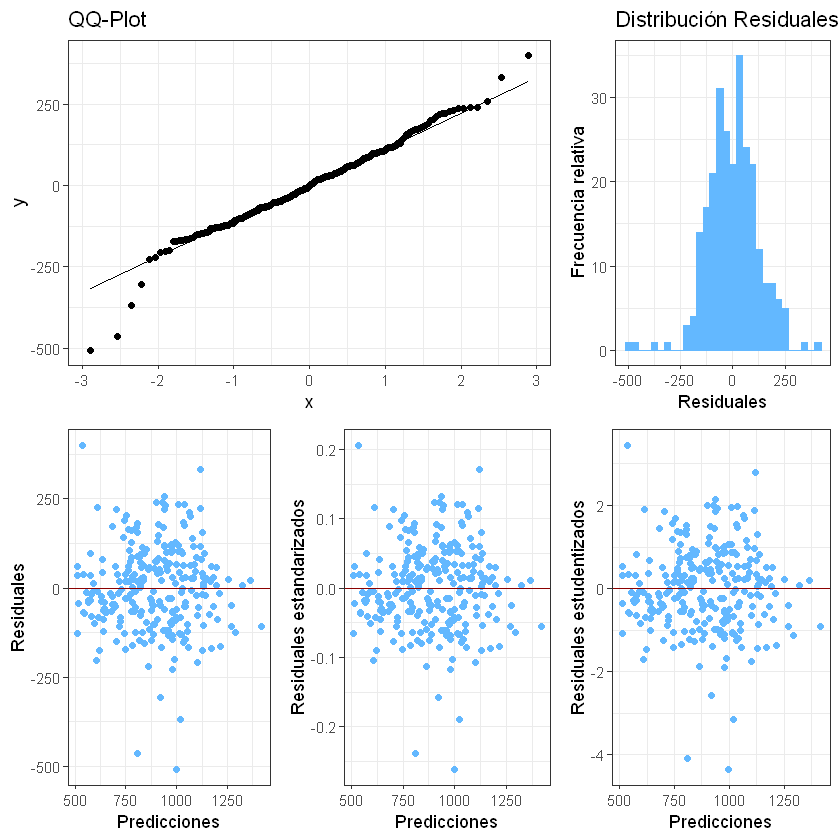
Análisis de residuales#
# Ajuste en train
y_train_pred = model.predict(X_train, verbose=0).flatten()
# Devolver scaler
y_train_pred_inv = scaler.inverse_transform(y_train_pred.reshape(-1, 1)).flatten()
y_train_pred_inv = pd.Series(y_train_pred_inv, index=train.index[lags:])
residuales = train['Precio'][lags:] - y_train_pred_inv
analisis_residuales(
residuales, # Agregar los residuales
nombre="Precio de electricidad",
)