SHAP - empresas en Reorganización#
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import matplotlib as mpl
import seaborn as sns
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.metrics import (
classification_report, confusion_matrix,
accuracy_score, f1_score, roc_auc_score,
RocCurveDisplay, ConfusionMatrixDisplay
)
import xgboost.callback as xgb_callback
from xgboost import XGBClassifier, plot_importance
import warnings
warnings.filterwarnings("ignore")
path = "BD empresas en re organización.xlsx"
xls = pd.ExcelFile(path)
df = pd.read_excel(path, sheet_name=xls.sheet_names[0])
df.head()
| Razón Social | Margen EBIT | Carga financiera | Margen neto | CxC | CxP | Solvencia | Apalancamiento | En Reorganización | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | AACER SAS | 0.071690 | 0.000000 | 0.042876 | 0.104095 | 0.153192 | 1.877078 | 1.642505 | 0 |
| 1 | ABARROTES EL ROMPOY SAS | 0.017816 | 0.000000 | 0.010767 | 0.018414 | 0.000000 | 0.000000 | 0.865044 | 0 |
| 2 | ABASTECIMIENTOS INDUSTRIALES SAS | 0.144646 | 0.054226 | 0.059784 | 0.227215 | 0.025591 | 1.077412 | 1.272299 | 0 |
| 3 | ACME LEON PLASTICOS SAS | 0.004465 | 0.000000 | -0.013995 | 0.073186 | 0.127866 | 0.000000 | 1.391645 | 0 |
| 4 | ADVANCED PRODUCTS COLOMBIA SAS | 0.141829 | 0.050810 | 0.053776 | 0.398755 | 0.147678 | 0.675073 | 2.118774 | 0 |
df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 629 entries, 0 to 628
Data columns (total 9 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Razón Social 629 non-null object
1 Margen EBIT 629 non-null float64
2 Carga financiera 629 non-null float64
3 Margen neto 629 non-null float64
4 CxC 629 non-null float64
5 CxP 629 non-null float64
6 Solvencia 629 non-null float64
7 Apalancamiento 629 non-null float64
8 En Reorganización 629 non-null int64
dtypes: float64(7), int64(1), object(1)
memory usage: 44.4+ KB
Ajuste con todas las variables#
En este tipo de modelos no es necesario escalar las variables.
# ------------------------
# Selección de variables
# ------------------------
variables_seleccionadas = ['Margen EBIT',
'Carga financiera',
'Margen neto',
'CxC',
'CxP',
'Solvencia',
'Apalancamiento']
# Variable objetivo
target = 'En Reorganización'
# ------------------------
# Preparar datos
# ------------------------
X = df[variables_seleccionadas]
y = df[target]
# Dividir en entrenamiento y prueba (70%-30%)
X_train, X_test, y_train, y_test = train_test_split(X,
y,
test_size=0.3,
random_state=35,
stratify=y)
XGBoost#
model = XGBClassifier(
# --- Tasa de aprendizaje e iteraciones ---
learning_rate=0.1, # η: contracción de cada árbol
n_estimators=500, # techo de árboles (early stopping decide el real)
early_stopping_rounds=50, # Early Stopping
# --- Estructura del árbol ---
max_depth=5, # profundidad máxima por árbol
min_child_weight=3, # suma mínima de hessianos en nodo hijo
gamma=0.1, # ganancia mínima para aceptar un split
# --- Regularización directa ---
reg_lambda=1, # λ: penalización L2 sobre pesos de hojas
reg_alpha=0.1, # α: penalización L1 sobre pesos de hojas (sparsity)
# --- Muestreo (stochastic boosting) ---
subsample=0.8, # fracción de filas por árbol
colsample_bytree=0.8, # fracción de columnas por árbol
# --- Configuración general ---
objective='binary:logistic',
eval_metric='logloss',
random_state=36
)
# Separar una porción del train para monitoreo
X_tr, X_val, y_tr, y_val = train_test_split(
X_train, y_train, test_size=0.2, random_state=35, stratify=y_train
)
model.fit(
X_tr, y_tr,
eval_set=[(X_val, y_val)],
verbose=False,
)
XGBClassifier(base_score=None, booster=None, callbacks=None,
colsample_bylevel=None, colsample_bynode=None,
colsample_bytree=0.8, device=None, early_stopping_rounds=50,
enable_categorical=False, eval_metric='logloss',
feature_types=None, feature_weights=None, gamma=0.1,
grow_policy=None, importance_type=None,
interaction_constraints=None, learning_rate=0.1, max_bin=None,
max_cat_threshold=None, max_cat_to_onehot=None,
max_delta_step=None, max_depth=5, max_leaves=None,
min_child_weight=3, missing=nan, monotone_constraints=None,
multi_strategy=None, n_estimators=500, n_jobs=None,
num_parallel_tree=None, ...)In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
XGBClassifier(base_score=None, booster=None, callbacks=None,
colsample_bylevel=None, colsample_bynode=None,
colsample_bytree=0.8, device=None, early_stopping_rounds=50,
enable_categorical=False, eval_metric='logloss',
feature_types=None, feature_weights=None, gamma=0.1,
grow_policy=None, importance_type=None,
interaction_constraints=None, learning_rate=0.1, max_bin=None,
max_cat_threshold=None, max_cat_to_onehot=None,
max_delta_step=None, max_depth=5, max_leaves=None,
min_child_weight=3, missing=nan, monotone_constraints=None,
multi_strategy=None, n_estimators=500, n_jobs=None,
num_parallel_tree=None, ...)SHAP#
import shap
Calcular valores SHAP:
# Crear explicador SHAP
explainer = shap.Explainer(model, X_tr)
# Calcular valores SHAP sobre test
shap_values = explainer(X_test)
Gráfico de importancia global tipo bar plot:
Muestra la importancia global promedio de las variables. El promedio del valor absoluto de los SHAP values de cada variable.
Una variable puede ser muy importante, pero el gráfico no indica si aumenta o disminuye la predicción (no muestra dirección).
shap.plots.bar(shap_values, max_display=len(variables_seleccionadas))
Summary plot tipo beeswarm:
Combina simultáneamente información sobre importancia global, dirección del efecto y dispersión de las contribuciones.
En este gráfico, cada punto representa una observación individual del dataset. Es decir, si el conjunto de prueba contiene 500 empresas, entonces para cada variable existirán 500 puntos.
Las variables se organizan verticalmente según su importancia global, de forma similar al Bar Plot. Sin embargo, ahora el eje horizontal representa el valor SHAP de cada observación.
Cuando un punto aparece hacia la derecha del gráfico significa que esa variable incrementó la predicción del modelo para esa observación específica. Cuando aparece hacia la izquierda, significa que disminuyó la predicción.
La interpretación de los colores es fundamental. Los puntos rojos representan valores altos de la variable, mientras que los puntos azules representan valores bajos. Esto permite analizar cómo cambia el efecto de la variable dependiendo de su magnitud.
Por ejemplo, si para la variable CxP los puntos rojos aparecen principalmente hacia la derecha, esto indica que valores altos de CxP incrementan la probabilidad de reorganización. Si los puntos azules aparecen hacia la izquierda, entonces valores bajos de CxP reducen dicha probabilidad.
Una de las mayores ventajas del Beeswarm Plot es que permite identificar relaciones no lineales y comportamientos heterogéneos. En modelos complejos es común que una misma variable tenga efectos distintos dependiendo del contexto de cada observación. Este fenómeno se refleja cuando los puntos aparecen muy dispersos horizontalmente.
Si la dispersión es amplia, significa que la variable puede tener impactos muy diferentes según las características de cada empresa. Por ejemplo, las CxP podría ser extremadamente peligroso en empresas con baja rentabilidad, pero menos relevante en empresas altamente líquidas.
Además, el gráfico puede sugerir interacciones entre variables. Cuando puntos de distintos colores aparecen mezclados en ciertas regiones, puede inferirse que el efecto de una variable depende del valor de otras variables.
shap.plots.beeswarm(
shap_values,
max_display=len(variables_seleccionadas)
)
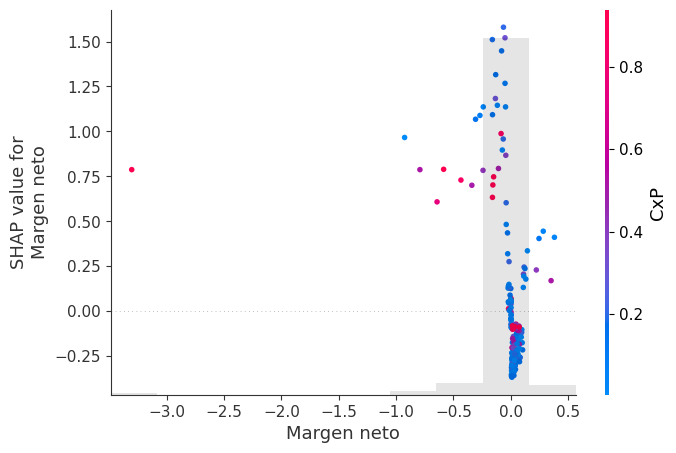
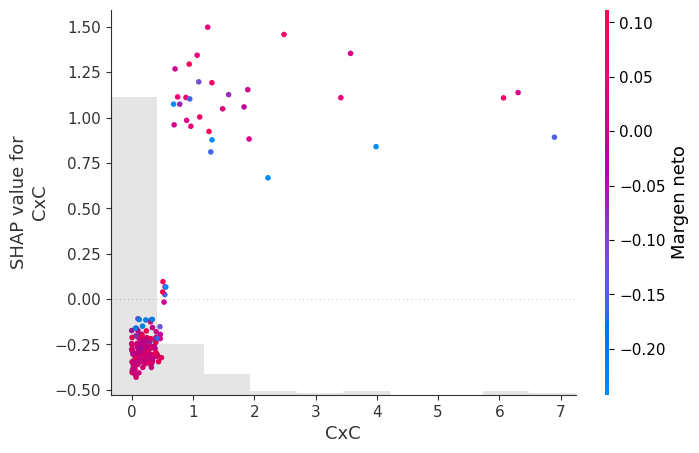
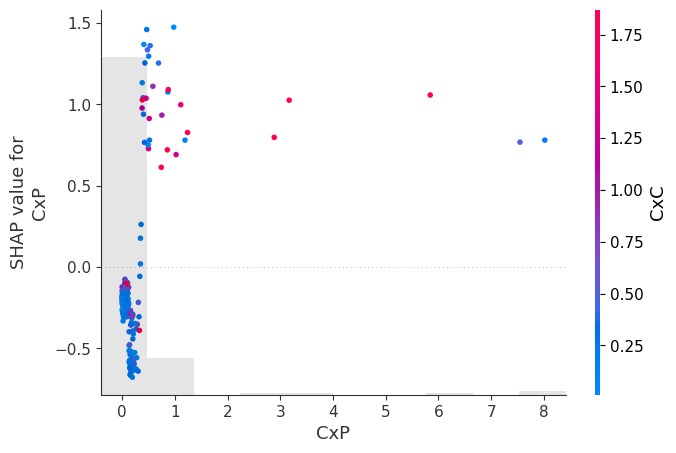
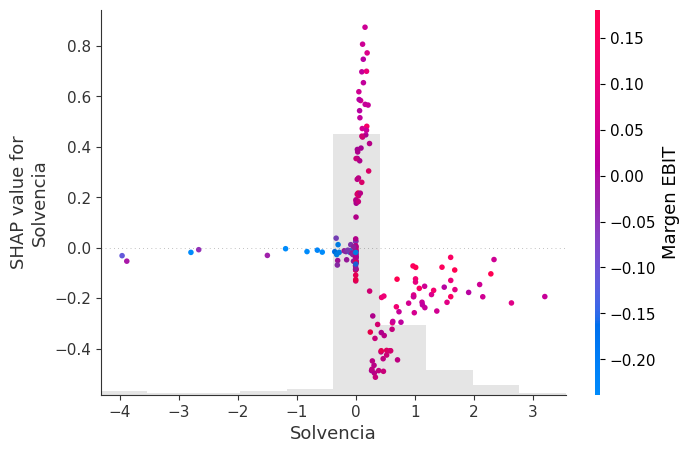
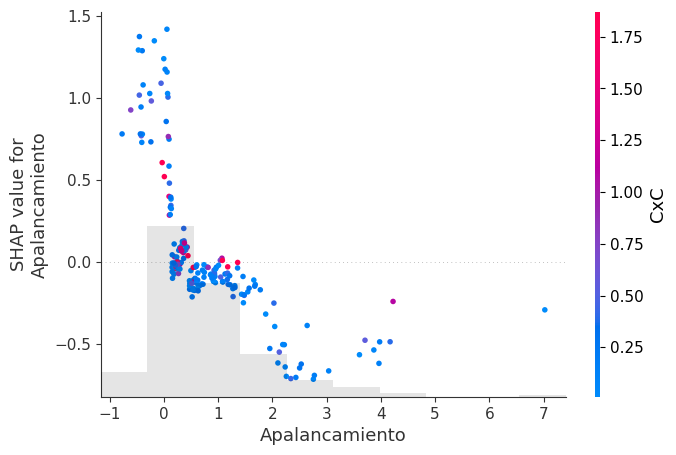
Gráfico de dependencia por variable:
El Dependence Plot se utiliza para analizar en detalle la relación entre el valor real de una variable y su impacto sobre la predicción del modelo.
En este caso, el eje horizontal representa el valor de la variable, mientras que el eje vertical representa el SHAP value asociado.
La principal ventaja de este gráfico es que permite observar cómo evoluciona el efecto de la variable a medida que aumenta o disminuye su valor. En otras palabras, permite analizar la forma funcional aprendida por el modelo.
Por ejemplo, si al aumentar el valor de una variable los valores SHAP también aumentan progresivamente, entonces el modelo está aprendiendo una relación positiva entre esa variable y el riesgo de reorganización.
Sin embargo, en muchos modelos complejos las relaciones no son lineales. El gráfico puede revelar umbrales críticos, efectos de saturación o cambios bruscos en el comportamiento del modelo. Puede ocurrir, por ejemplo, que la variable tenga poco efecto hasta cierto nivel, pero a partir de un umbral específico incremente fuertemente el riesgo.
Este tipo de comportamiento es extremadamente valioso porque permite identificar patrones que modelos lineales tradicionales no pueden capturar.
Cuando se incorpora color al gráfico, SHAP utiliza otra variable para representar posibles interacciones. Así, el gráfico puede mostrar que el efecto de la variable depende simultáneamente de otras variables.
for variable in variables_seleccionadas:
shap.plots.scatter(
shap_values[:, variable],
color=shap_values
)
Waterfall plot para una empresa específica:
El Waterfall Plot es un gráfico diseñado para explicar una predicción individual de manera detallada.
El gráfico comienza en el valor base del modelo, es decir, la predicción promedio global. Posteriormente, va sumando o restando las contribuciones de cada variable hasta llegar a la predicción final de una observación específica.
Las barras rojas representan variables que aumentan la predicción, mientras que las barras azules representan variables que la disminuyen.
Suponga una empresa cuya probabilidad predicha de reorganización es 0,85. El Waterfall Plot podría mostrar que:
el alto apalancamiento aumentó el riesgo,
la baja solvencia también incrementó la probabilidad,
mientras que un margen EBIT positivo redujo parcialmente el riesgo.
Este gráfico es especialmente útil porque permite comprender exactamente por qué el modelo tomó una determinada decisión para una observación específica.
En aplicaciones financieras, médicas o industriales, esta capacidad resulta crítica porque permite justificar las decisiones del modelo frente a analistas, reguladores o expertos del dominio.
X_test.iloc[42]
| 607 | |
|---|---|
| Margen EBIT | 0.025216 |
| Carga financiera | 0.000000 |
| Margen neto | 0.010397 |
| CxC | 0.401042 |
| CxP | 0.691024 |
| Solvencia | 0.289014 |
| Apalancamiento | 0.077172 |
y_test.iloc[42]
np.int64(1)
y_pred = model.predict(X_test.iloc[42].values.reshape(1, -1))
y_pred
array([1])
shap.plots.waterfall(shap_values[42])
Force plot:
El Force Plot tiene una lógica similar al Waterfall Plot, pero utiliza una representación visual más intuitiva y dinámica.
El gráfico muestra cómo las variables “empujan” la predicción desde el valor base hacia el valor final.
Las regiones rojas empujan la predicción hacia valores mayores, mientras que las regiones azules la desplazan hacia valores menores.
La ventaja principal de este gráfico es su capacidad visual para resumir rápidamente cuáles variables dominan una predicción específica. Sin embargo, cuando existen muchas variables puede volverse difícil de interpretar.
Por ello, suele utilizarse principalmente para exploración interactiva o análisis individuales.
shap.initjs()
shap.force_plot(
shap_values.base_values[0],
shap_values.values[42],
X_test.iloc[42],
feature_names=variables_seleccionadas
)

Have you run `initjs()` in this notebook? If this notebook was from another user you must also trust this notebook (File -> Trust notebook). If you are viewing this notebook on github the Javascript has been stripped for security. If you are using JupyterLab this error is because a JupyterLab extension has not yet been written.
Decision plot:
El Decision Plot permite analizar cómo se construyen las predicciones paso a paso para múltiples observaciones simultáneamente.
Cada línea representa una observación del dataset. Todas las líneas comienzan en el valor base y van modificándose conforme se agregan las contribuciones de las variables.
Este gráfico resulta especialmente útil para comparar trayectorias de predicción entre empresas. Por ejemplo, dos empresas podrían comenzar con riesgos similares, pero diferenciarse significativamente debido al impacto del apalancamiento o de la solvencia.
El gráfico también permite identificar qué variables generan los mayores cambios en las predicciones y cómo se separan distintos grupos de observaciones.
En problemas financieros, este tipo de visualización puede utilizarse para identificar patrones de comportamiento entre empresas sanas y empresas con dificultades financieras.
shap.decision_plot(
shap_values.base_values[0],
shap_values.values,
X_test,
feature_names=variables_seleccionadas
)