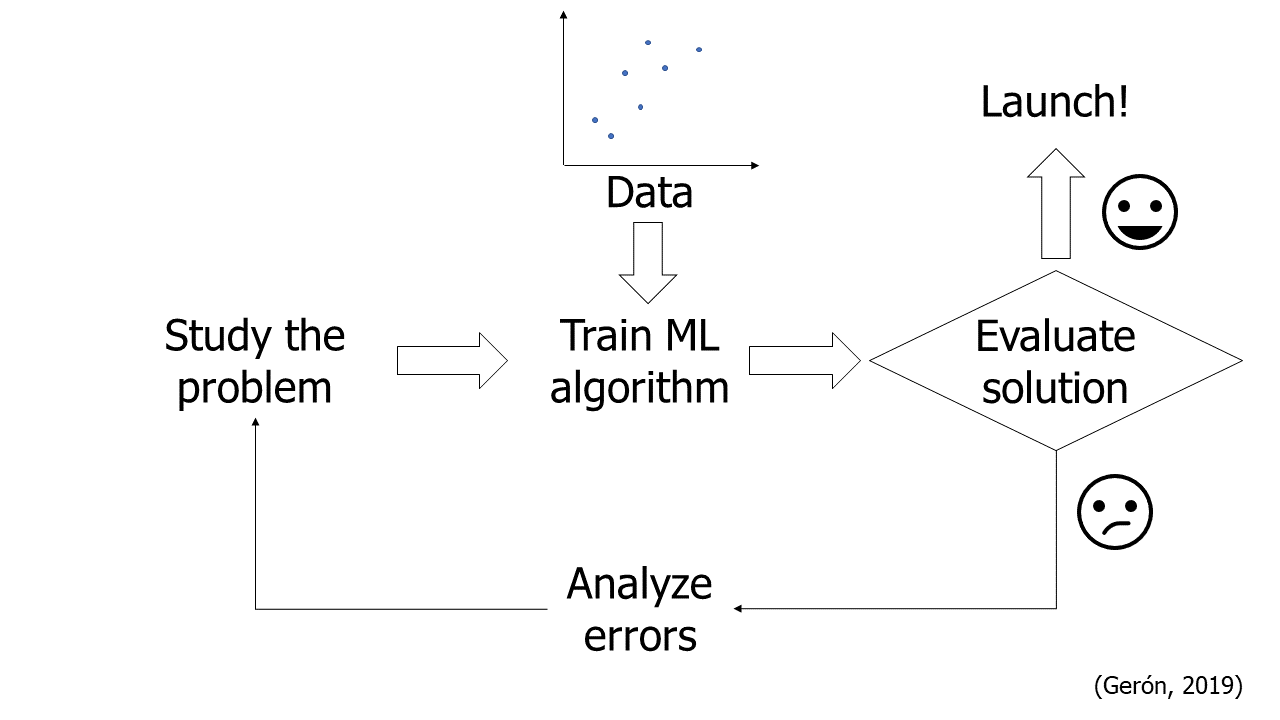
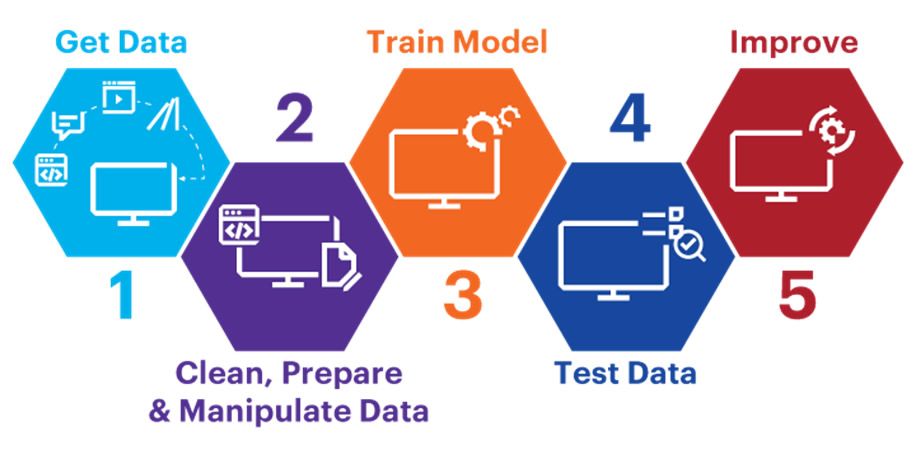
Proyectos de Machine Learning¶
1. Estudiar el problema:
Objetivos.
Supuestos.
¿Cómo medir el desempeño (performance)?
2. Obtener los datos (data).
Convertir los datos en un formato fácil de manipular.
Verificar el tipo de datos y el tamaño.
3. Explorar los datos para obtener información.
Estudiar cada atributo de los datos como: nombre, tipo, porcentaje de valores faltantes, distribuciones de probabilidad, etc.
Visualizar los datos.
Estudiar las correlaciones.
4. Preparar los datos para los algoritmos de aprendizaje automático (Machine Learning-ML).
Ajustar o remover los outliers (optional).
Ajustar los valores faltantes.
Eliminar variables que no proveen información útil (opcional).
Estandarizar o normalizar las variables.
5. Explorar muchos modelos diferentes y preseleccionar los mejores.
Entrenar rápidamente varios modelos con parámetros estándar: Lineales, Support Vector Machine (SVM), Random Forest, Neural networks, etc.
Medir y comparar el desempeño (performance).
Seleccionar los modelos más prometedores.
6. Ajustar los modelos (tuning).
Optimización de los hiperparámetros (Fine-tune the hyperparameters).
Con el modelo final medir el desempeño en el conjunto de prueba (test) para estimar el error.
7. Presentar la solución.
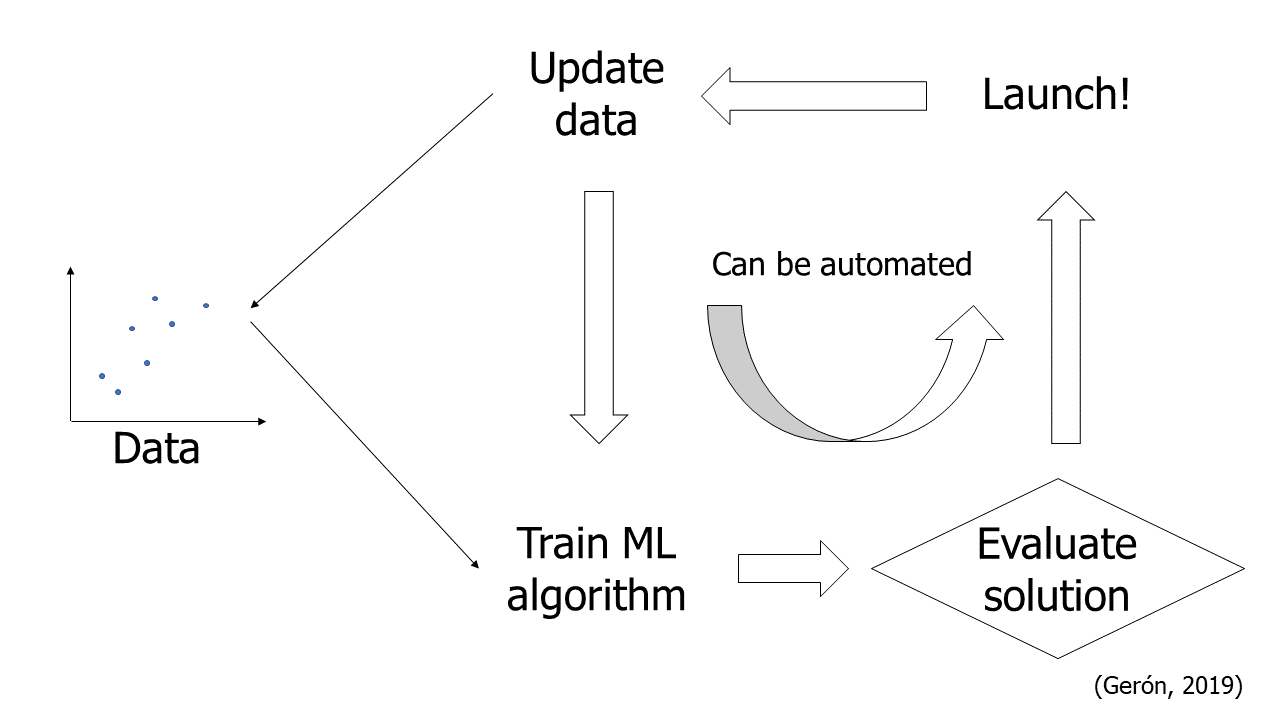
8. Inicie (launch), supervise y mantenga el sistema.
Automatizar cada paso en lo posible.
Proyectos de ML¶
automatedML¶
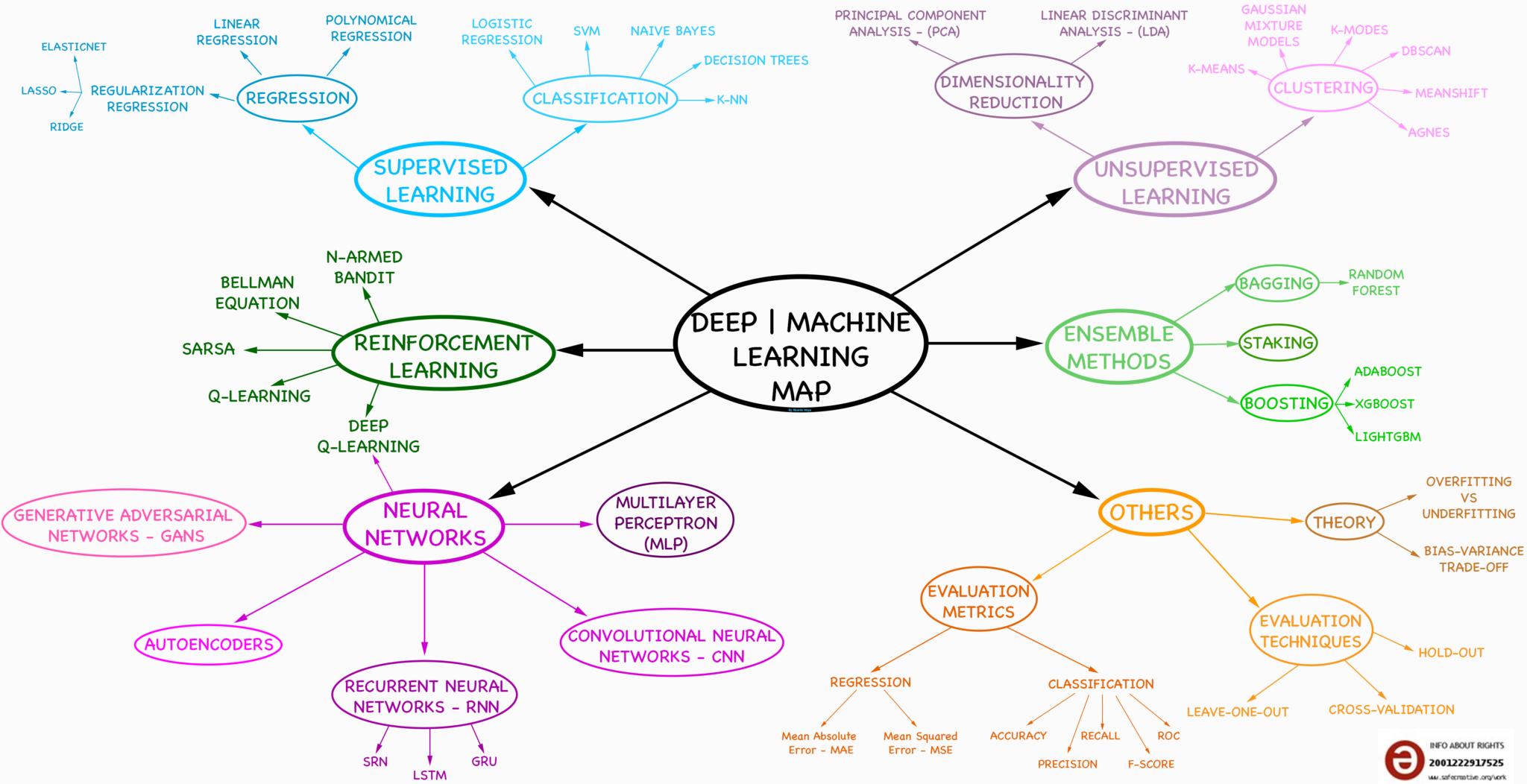
Tipos de problemas:¶
El Machine Learning se enfoca en aprender desde los datos para descubrir patrones ocultos o predecir eventos futuros. Existen dos enfoques principales en el Machine Learning: Aprendizaje supervisado (supervised learning) y aprendizaje no supervisado (unsupervised learning). La principal diferencia entre estos dos enfoques es que en uno se utilizan las etiquetas (labels) para predecir y en el otro no.
Aprendizaje supervisado:¶
Este enfoque de Machine Learning requiere una etiqueta que contenga un resultado esperado para cada observación, es decir, para cada fila del dataset. Con el dataset los algoritmos aprenden de los datos y de las etiquetas y se usan para clasificación o predecir resultados (regresión).
Clasificación:
La clasificación es un conjunto de métodos del aprendizaje supervisado
que tiene como objetivo asignar una etiqueta de clase discreta elegida a
un conjunto limitado de opciones, que pueden ser dos o más. En muchos
casos se usan las siguientes etiquetas: Si, No para referirse al
1 y al 0, respectivamente; también se puede utilizar
positivo para indicar el valor de 1 o negativo para el valor
del 0. No necesariamente deben ser etiquetas de buenos o malo o de
claro u oscuro.
ID cliente |
Edad |
Género |
Salario |
¿Pagó? |
|---|---|---|---|---|
1 |
50 |
F |
1000 |
Si |
2 |
18 |
M |
800 |
No |
3 |
44 |
F |
2000 |
No |
4 |
60 |
M |
1500 |
No |
5 |
32 |
M |
1200 |
Si |
. |
. |
. |
. |
. |
. |
. |
. |
. |
. |
. |
. |
. |
. |
. |
100000 |
32 |
M |
1850 |
Si |
Regresión:
La regresión es una técnica de aprendizaje supervisado que trata de capturar la relación entre dos o más variables. En estos problemas tenemos variables independientes con las cuales queremos predecir una variable dependiente. En estos casos se usan variables continuas y discretas.
ID cliente |
Edad |
Género |
Salario |
Valor compra |
|---|---|---|---|---|
1 |
50 |
F |
1000 |
100 |
2 |
18 |
M |
800 |
20 |
3 |
44 |
F |
2000 |
50 |
4 |
60 |
M |
1500 |
1000 |
5 |
32 |
M |
1200 |
22 |
. |
. |
. |
. |
. |
. |
. |
. |
. |
. |
. |
. |
. |
. |
. |
100000 |
32 |
M |
1850 |
200 |
Algoritmos de aprendizaje supervisado:
k-Nearest Neighbors.
Linear Regression.
Logistic Regression.
Support Vector Machines (SVMs).
Decision Trees and Random Forests.
Neural networks*.
Aprendizaje no supervisado:¶
El aprendizaje no supervisado es un conjunto de técnicas que se enfocan en encontrar patrones ocultos. En estos métodos no se requieren datos etiquetados. El objetivo es encontrar estructuras subyacentes en los datos, simplificar y comprimir el conjunto de datos, o agrupas los datos según similitudes inherentes.
Una tarea común del aprendizaje no supervisado es el agrupamiento (clustering), que es un método para agrupar puntos de datos en grupos (clusters) para que los objetos que son similares entre sí se asignen a un grupo y se asegure de que los cluster sean significativamente diferentes.
ID cliente |
Edad |
Género |
Salario |
|---|---|---|---|
1 |
50 |
F |
1000 |
2 |
18 |
M |
800 |
3 |
44 |
F |
2000 |
4 |
60 |
M |
1500 |
5 |
32 |
M |
1200 |
. |
. |
. |
. |
. |
. |
. |
. |
. |
. |
. |
. |
100000 |
32 |
M |
1850 |
Algoritmos de aprendizaje no supervisado:
Clustering:
K-Means.
DBSCAN.
Hierarchical Cluster Analysis (HCA).
Reducción de dimensionalidad:
Análisis de Componentes Principales (Principal Component Analysis-PCA).
Kernel PCA.
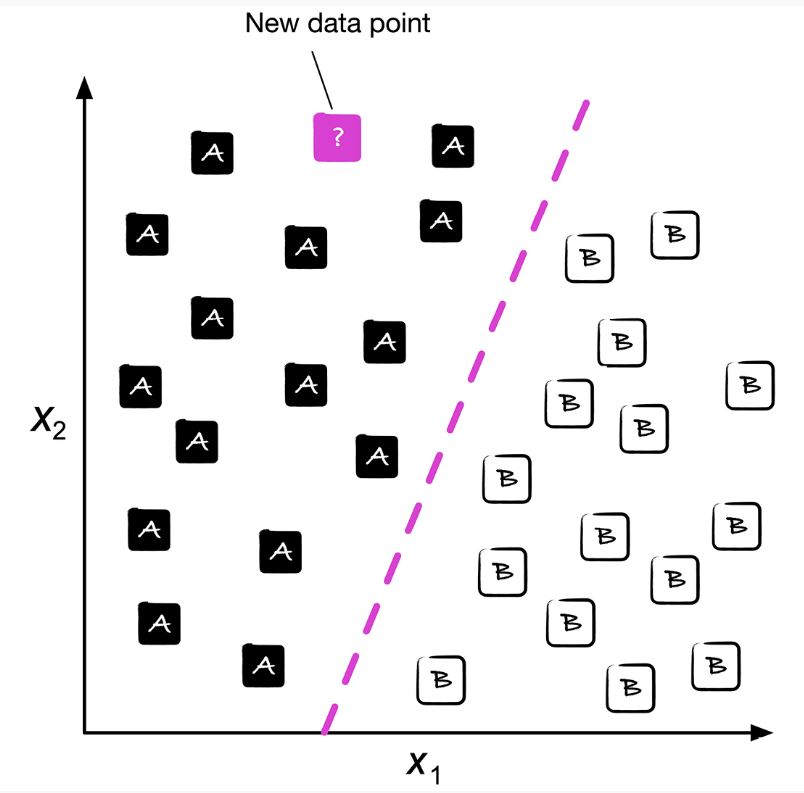
Classification (Raschka, 2022)¶
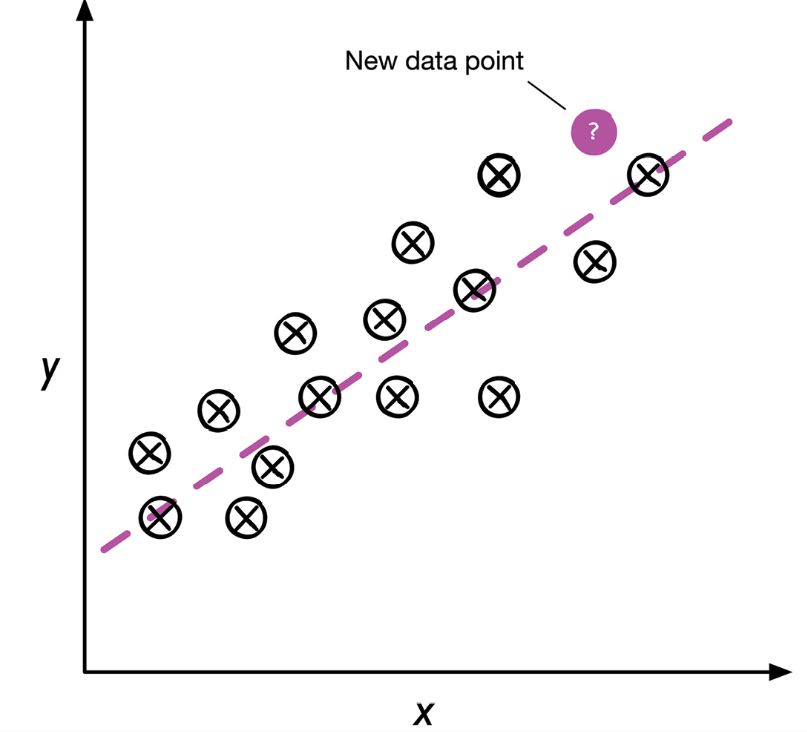
Regression (Raschka, 2022)¶
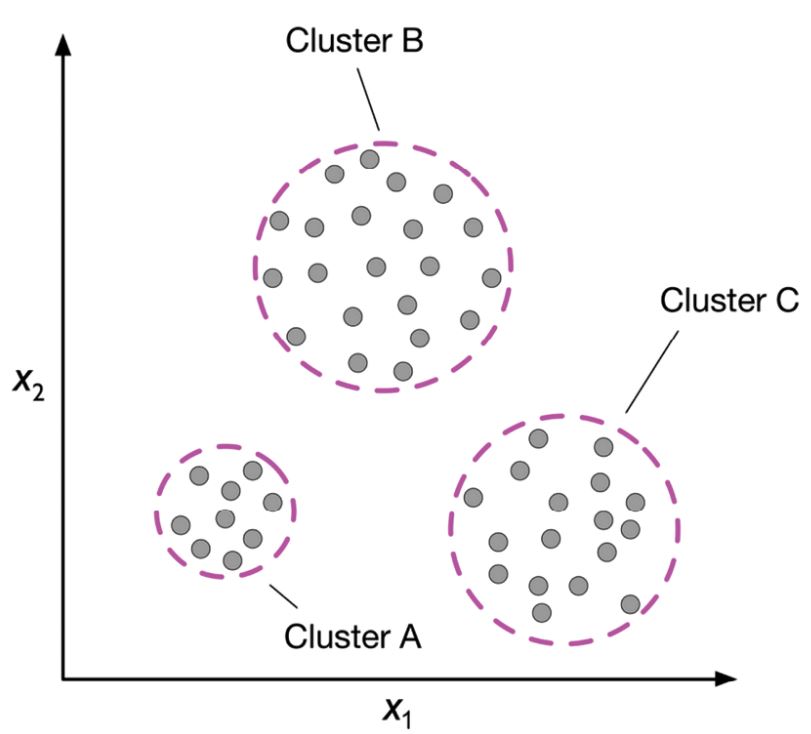
Clustering (Raschka, 2022)¶
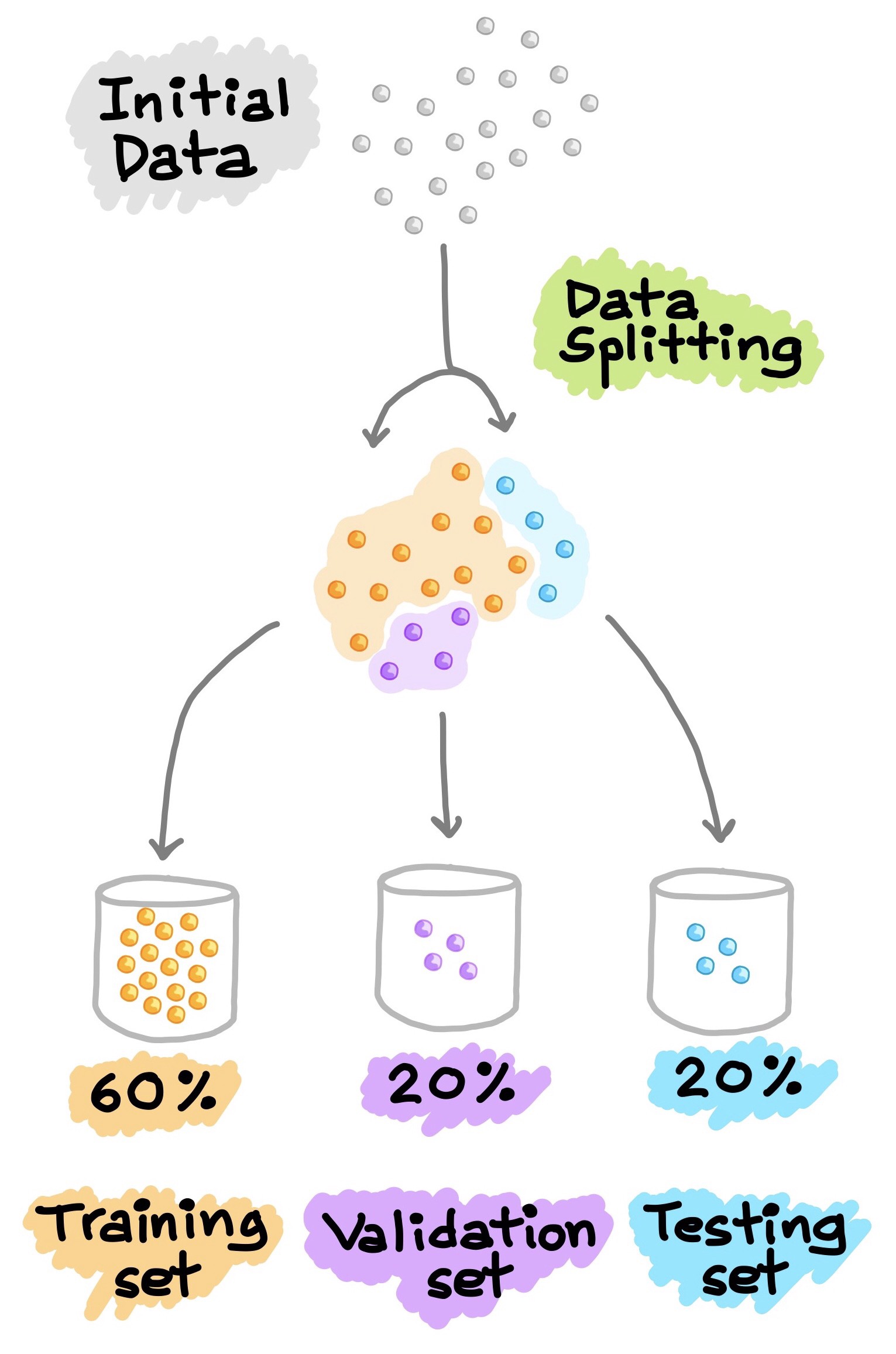
Conjunto de entrenamiento y conjunto de prueba:¶
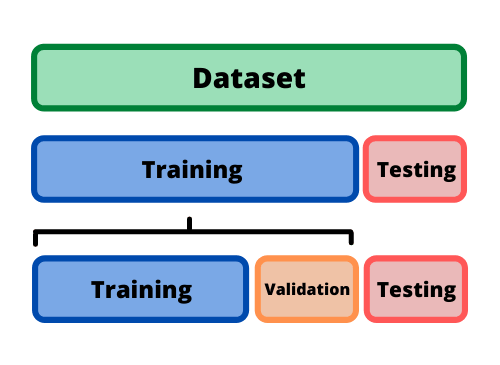
Antes de lanzar el modelo a producción se debe evaluar qué tan bien generaliza.
La única forma de saber el nivel en que el modelo generaliza nuevos valores es probándolo con los nuevos valores. Lo ideal es dividir el dataset en dos: conjunto de entrenamiento (train) y conjunto de prueba (test). Usando el training set se ajustan los parámetros del modelo y los hiperparámetros, esto es el entrenamiento del modelo, luego, se prueba el modelo con el test set que serán los valores nuevos que el modelo no conoce.
La tasa de error en el conjunto de prueba se llamará error de generalización o error fuera de la muestra. Este resultado indicará qué tan bien funcionará el modelo en instancias en las que nunca había visto.
Si error en el conjunto de train es bajo, pero el error en el conjunto de test es alto, significa que el modelo está sobreajustado (overfitting) a los datos de entrenamiento.
Lo más común es utilizar el 80% del dataset para train y reservar el 20% para test; sin embargo, esto depende del tamaño del dataset, por ejemplo, con millones de datos, tener 1% en test es más que suficiente para estimar el error de generalización.
DataSet¶
DataSetSplit¶
Selección del modelo:¶
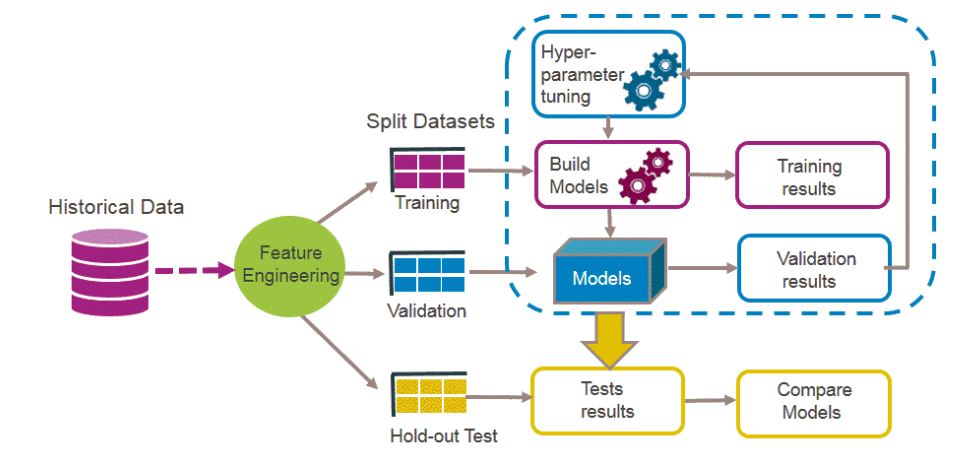
Para seleccionar el modelo más adecuado se evalúa qué tan bien generalizan usando el conjunto de test, pero antes de determinar esto se debe encontrar la mejor combinación de hiperparámetros para cada modelo.
Los hiperparámetros de un modelo son los valores de las configuraciones utilizadas durante el proceso de entrenamiento. Generalmente son valores que no se obtienen de los datos, son indicados por el analista de datos. En cambio, los parámetros se ajustan a los datos, aprenden de los datos.
Dicho de otra forma, Un hiperparámetro es un parámetro de un algoritmo de aprendizaje (no del modelo). Como tal, no se ve afectado por el propio algoritmo de aprendizaje; debe establecerse antes del entrenamiento y permanece constante durante el entrenamiento. Ajustar los hiperparámetros es una parte importante de la construcción de un sistema de aprendizaje automático.
Ejemplos de hiperparámetro, cantidad de neuronas, cantidad que se ejecuta el modelo para entrenar, tipo de función a utilizar: lineal o logística, etc.
En algunos casos en la optimización de los hiperparámetros el modelo se adapta al conjunto de test y en la etapa de producción muestra mayores errores. Una forma de solucionar este problema es dividir el conjunto de test en dos: conjunto de entrenamiento y conjunto de validación, note que el conjunto de test sigue siendo el mismo. Con el conjunto de entrenamiento reducido se entrenan varios modelos con varios hiperparámetros y se selecciona el modelo que mejor funciona con el conjunto de validación. Después de este proceso, se entrena el modelo seleccionado con el conjunto de train completo (conjunto de train reducido más el de validación) y esto dará el modelo final. Por último, se evalúa el modelo final en el conjunto de test para estimar el error de generalización.
Métricas para evaluación del desempeño:¶
Performance Measure
Para problemas de regresión es común calcular el RMSE - Error Cuadrático Medio - (Root Mean Square Error). Esta métrica muestra el error de las predicciones en las mismas unidades que la variable dependiente, \(y\). Por su forma de calcularse, asigna mayor peso a los errores grandes.
El RMSE es sensible si hay presencia de muchos datos atípico.
Cuando se tienen muchos datos atípicos se podría utilizar el MAE - Error Absoluto Medio - (Mean Absolute Error) el cual calcula el promedio de la desviación absoluta.
Existen muchas más métricas para medir el desempeño de los modelos de Machine Learning y cada técnica tiene sus propias métricas, por ejemplo para los problemas de clasificación se usa la matriz de confusión.
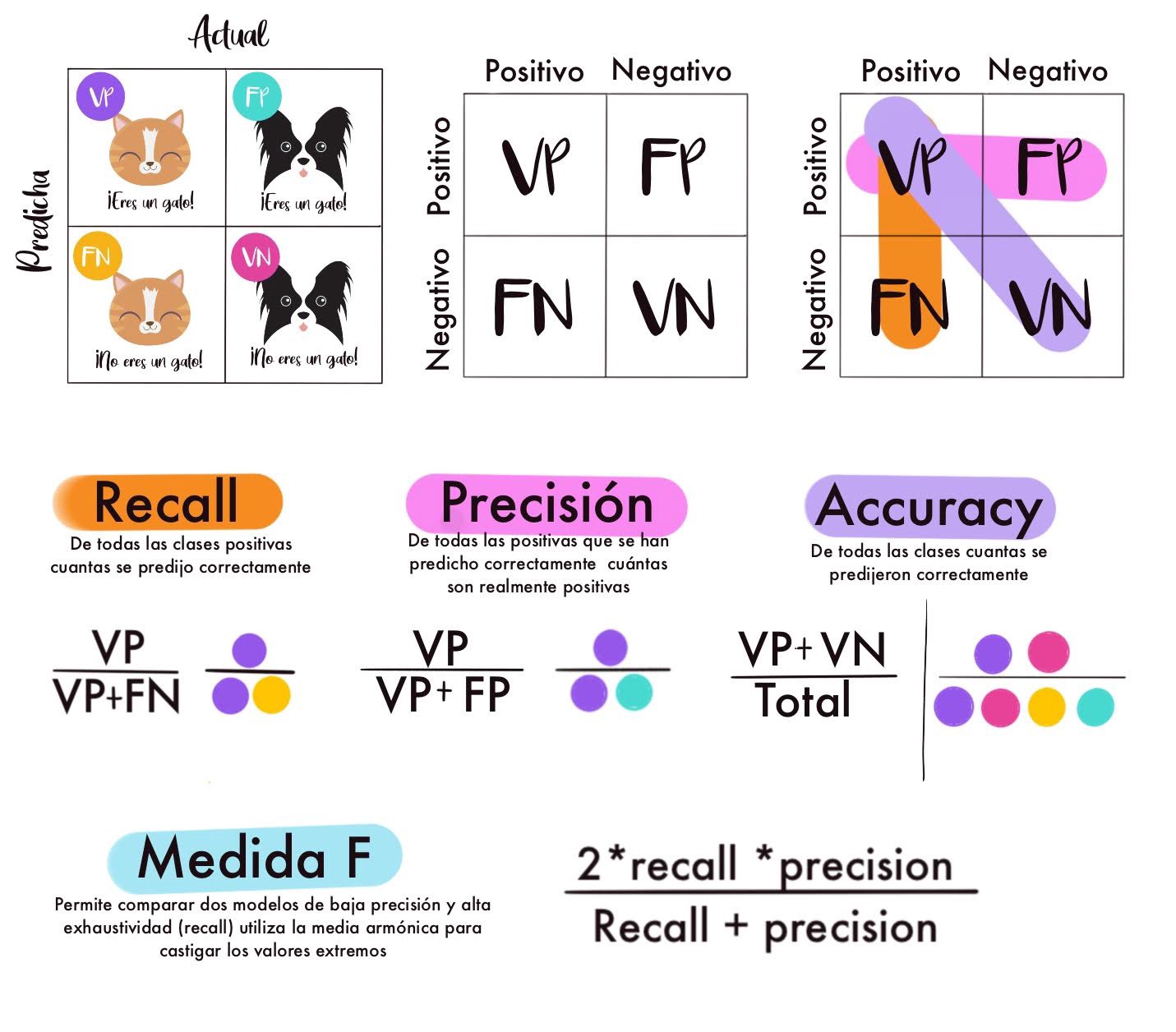
Matriz-Confusion¶
Deep_Machine_Learning¶